 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Stochastic Bilevel Optimization with Momentum-Based Variance Reduction
May 03, 2022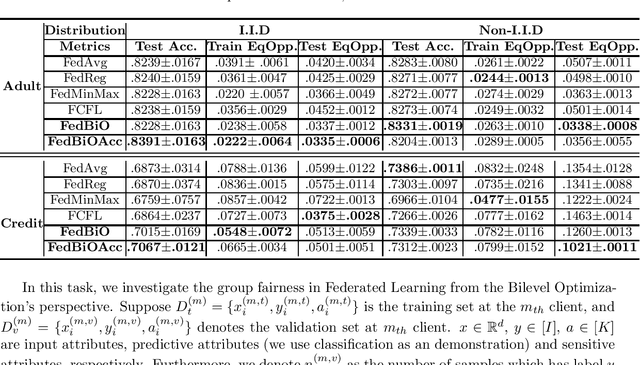
Bilevel Optimization has witnessed notable progress recently with new emerging efficient algorithms and has been applied to many machine learning tasks such as data cleaning, few-shot learning, and neural architecture search. However, little attention has been paid to solve the bilevel problems under distributed setting. Federated learning (FL) is an emerging paradigm which solves machine learning tasks over distributed-located data. FL problems are challenging to solve due to the heterogeneity and communication bottleneck. However, it is unclear how these challenges will affect the convergence of Bilevel Optimization algorithms. In this paper, we study Federated Bilevel Optimization problems. Specifically, we first propose the FedBiO, a deterministic gradient-based algorithm and we show it requires $O(\epsilon^{-2})$ number of iterations to reach an $\epsilon$-stationary point. Then we propose FedBiOAcc to accelerate FedBiO with the momentum-based variance-reduction technique under the stochastic scenario. We show FedBiOAcc has complexity of $O(\epsilon^{-1.5})$. Finally, we validate our proposed algorithms via the important Fair Federated Learning task. More specifically, we define a bilevel-based group fair FL objective. Our algorithms show superior performances compared to other baselines in numerical experiments.
Distributed Dynamic Safe Screening Algorithms for Sparse Regularization
Apr 23, 2022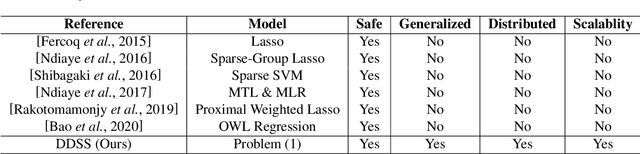
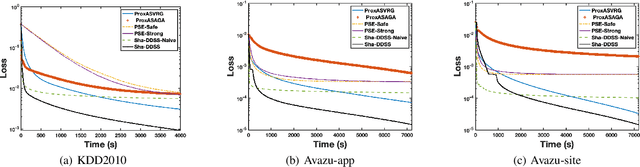

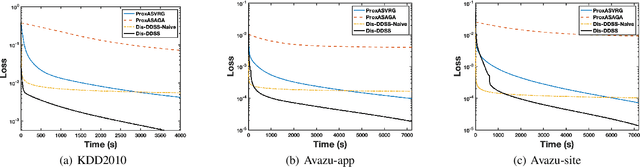
Distributed optimization has been widely used as one of the most efficient approaches for model training with massive samples. However, large-scale learning problems with both massive samples and high-dimensional features widely exist in the era of big data. Safe screening is a popular technique to speed up high-dimensional models by discarding the inactive features with zero coefficients. Nevertheless, existing safe screening methods are limited to the sequential setting. In this paper, we propose a new distributed dynamic safe screening (DDSS) method for sparsity regularized models and apply it on shared-memory and distributed-memory architecture respectively, which can achieve significant speedup without any loss of accuracy by simultaneously enjoying the sparsity of the model and dataset. To the best of our knowledge, this is the first work of distributed safe dynamic screening method. Theoretically, we prove that the proposed method achieves the linear convergence rate with lower overall complexity and can eliminate almost all the inactive features in a finite number of iterations almost surely. Finally, extensive experimental results on benchmark datasets confirm the superiority of our proposed method.
Desirable Companion for Vertical Federated Learning: New Zeroth-Order Gradient Based Algorithm
Mar 19, 2022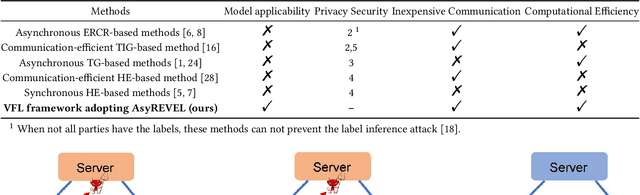
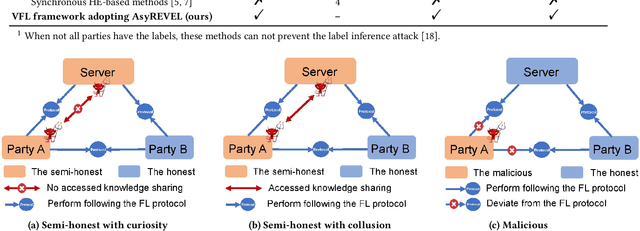
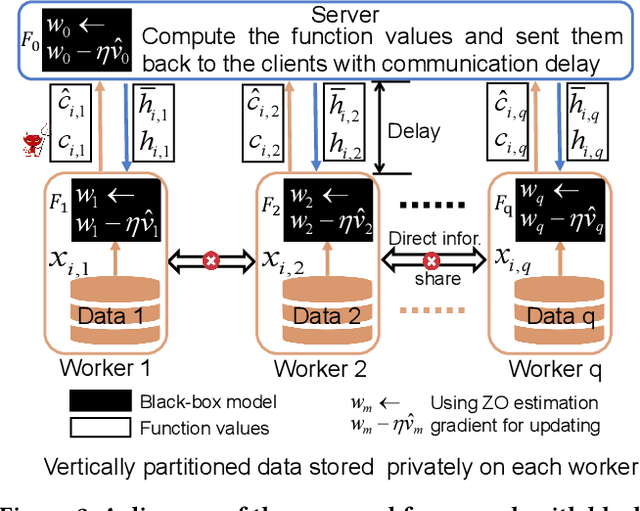
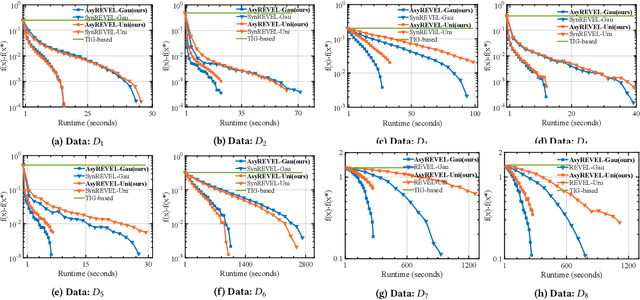
Vertical federated learning (VFL) attracts increasing attention due to the emerging demands of multi-party collaborative modeling and concerns of privacy leakage. A complete list of metrics to evaluate VFL algorithms should include model applicability, privacy security, communication cost, and computation efficiency, where privacy security is especially important to VFL. However, to the best of our knowledge, there does not exist a VFL algorithm satisfying all these criteria very well. To address this challenging problem, in this paper, we reveal that zeroth-order optimization (ZOO) is a desirable companion for VFL. Specifically, ZOO can 1) improve the model applicability of VFL framework, 2) prevent VFL framework from privacy leakage under curious, colluding, and malicious threat models, 3) support inexpensive communication and efficient computation. Based on that, we propose a novel and practical VFL framework with black-box models, which is inseparably interconnected to the promising properties of ZOO. We believe that it takes one stride towards designing a practical VFL framework matching all the criteria. Under this framework, we raise two novel {\bf asy}nchronous ze{\bf r}oth-ord{\bf e}r algorithms for {\bf v}ertical f{\bf e}derated {\bf l}earning (AsyREVEL) with different smoothing techniques. We theoretically drive the convergence rates of AsyREVEL algorithms under nonconvex condition. More importantly, we prove the privacy security of our proposed framework under existing VFL attacks on different levels. Extensive experiments on benchmark datasets demonstrate the favorable model applicability, satisfied privacy security, inexpensive communication, efficient computation, scalability and losslessness of our framework.
Closing the Generalization Gap of Cross-silo Federated Medical Image Segmentation
Mar 18, 2022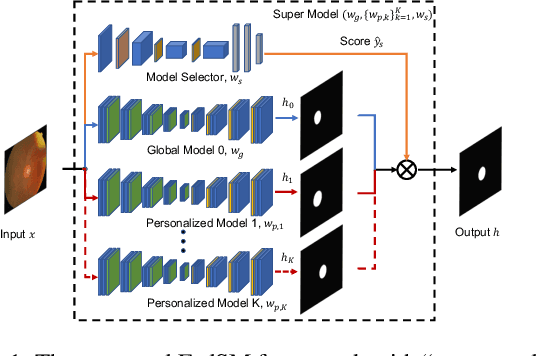
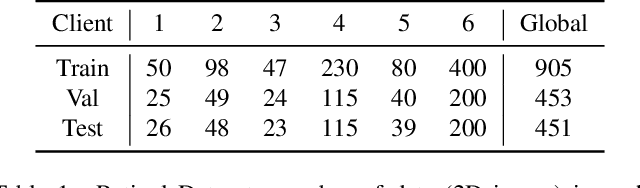
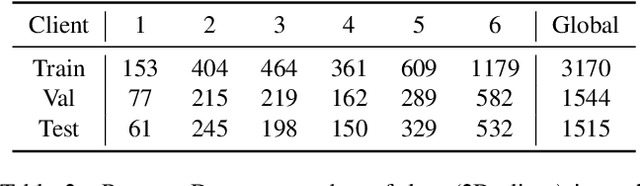
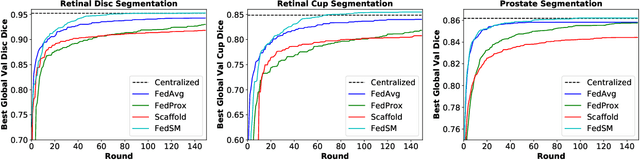
Cross-silo federated learning (FL) has attracted much attention in medical imaging analysis with deep learning in recent years as it can resolve the critical issues of insufficient data, data privacy, and training efficiency. However, there can be a generalization gap between the model trained from FL and the one from centralized training. This important issue comes from the non-iid data distribution of the local data in the participating clients and is well-known as client drift. In this work, we propose a novel training framework FedSM to avoid the client drift issue and successfully close the generalization gap compared with the centralized training for medical image segmentation tasks for the first time. We also propose a novel personalized FL objective formulation and a new method SoftPull to solve it in our proposed framework FedSM. We conduct rigorous theoretical analysis to guarantee its convergence for optimizing the non-convex smooth objective function. Real-world medical image segmentation experiments using deep FL validate the motivations and effectiveness of our proposed method.
Towards Bi-directional Skip Connections in Encoder-Decoder Architectures and Beyond
Mar 17, 2022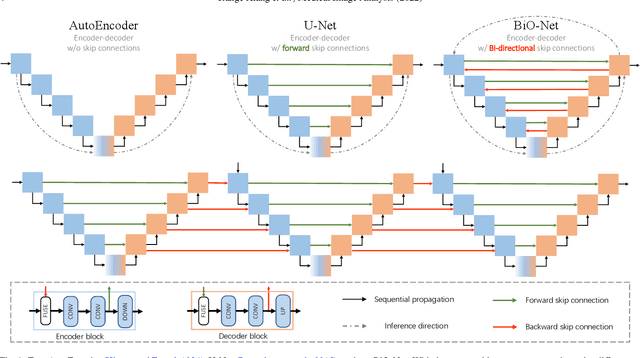
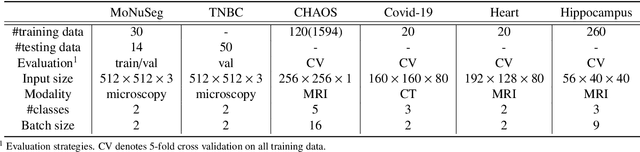
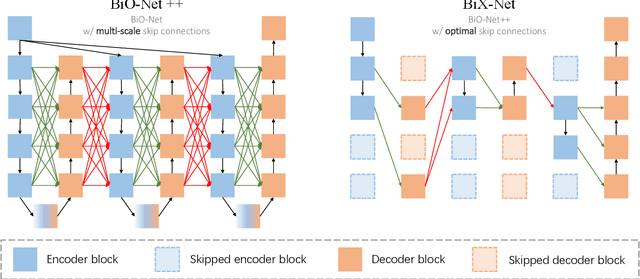
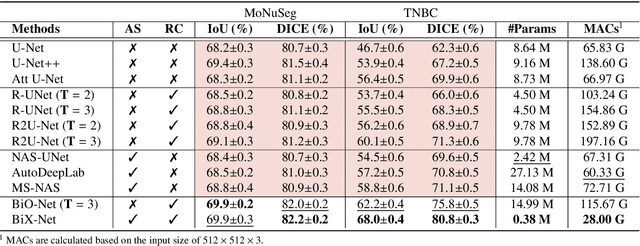
U-Net, as an encoder-decoder architecture with forward skip connections, has achieved promising results in various medical image analysis tasks. Many recent approaches have also extended U-Net with more complex building blocks, which typically increase the number of network parameters considerably. Such complexity makes the inference stage highly inefficient for clinical applications. Towards an effective yet economic segmentation network design, in this work, we propose backward skip connections that bring decoded features back to the encoder. Our design can be jointly adopted with forward skip connections in any encoder-decoder architecture forming a recurrence structure without introducing extra parameters. With the backward skip connections, we propose a U-Net based network family, namely Bi-directional O-shape networks, which set new benchmarks on multiple public medical imaging segmentation datasets. On the other hand, with the most plain architecture (BiO-Net), network computations inevitably increase along with the pre-set recurrence time. We have thus studied the deficiency bottleneck of such recurrent design and propose a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS, to search for the best multi-scale bi-directional skip connections. The ineffective skip connections are then discarded to reduce computational costs and speed up network inference. The finally searched BiX-Net yields the least network complexity and outperforms other state-of-the-art counterparts by large margins. We evaluate our methods on both 2D and 3D segmentation tasks in a total of six datasets. Extensive ablation studies have also been conducted to provide a comprehensive analysis for our proposed methods.
How Many Data Are Needed for Robust Learning?
Feb 23, 2022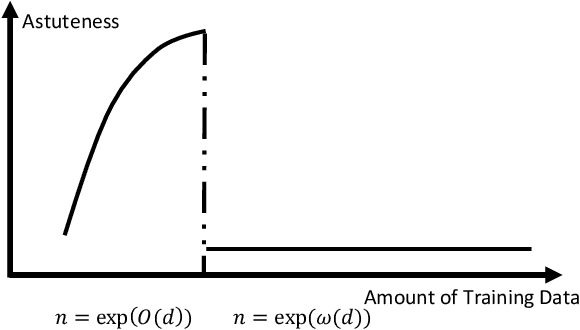
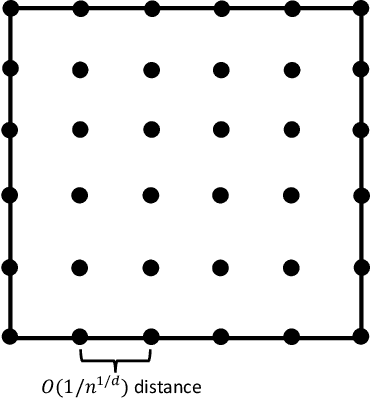
We show that the sample complexity of robust interpolation problem could be exponential in the input dimensionality and discover a phase transition phenomenon when the data are in a unit ball. Robust interpolation refers to the problem of interpolating $n$ noisy training data in $\R^d$ by a Lipschitz function. Although this problem has been well understood when the covariates are drawn from an isoperimetry distribution, much remains unknown concerning its performance under generic or even the worst-case distributions. Our results are two-fold: 1) too many data hurt robustness; we provide a tight and universal Lipschitzness lower bound $\Omega(n^{1/d})$ of the interpolating function for arbitrary data distributions. Our result disproves potential existence of an $\mathcal{O}(1)$-Lipschitz function in the overparametrization scenario when $n=\exp(\omega(d))$. 2) Small data hurt robustness: $n=\exp(\Omega(d))$ is necessary for obtaining a good population error under certain distributions by any $\mathcal{O}(1)$-Lipschitz learning algorithm. Perhaps surprisingly, our results shed light on the curse of big data and the blessing of dimensionality for robustness, and discover an intriguing phenomenon of phase transition at $n=\exp(\Theta(d))$.
HNF-Netv2 for Brain Tumor Segmentation using multi-modal MR Imaging
Feb 10, 2022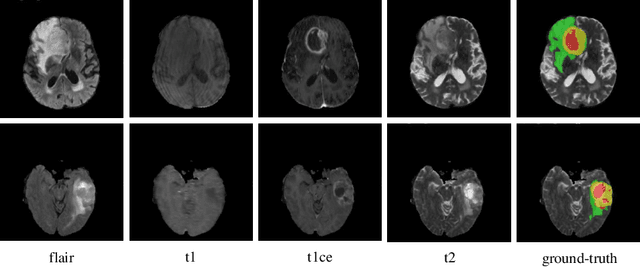

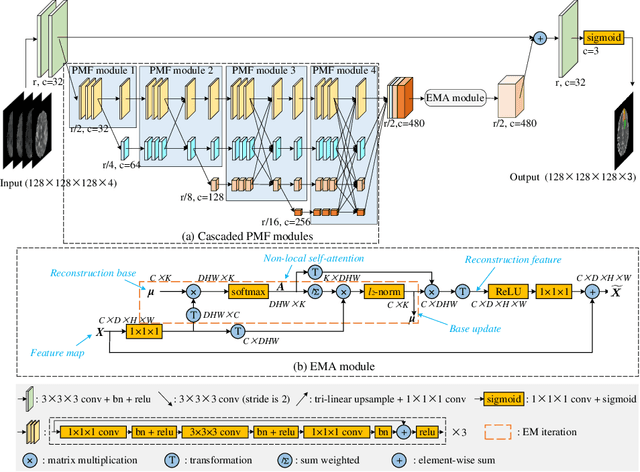

In our previous work, $i.e.$, HNF-Net, high-resolution feature representation and light-weight non-local self-attention mechanism are exploited for brain tumor segmentation using multi-modal MR imaging. In this paper, we extend our HNF-Net to HNF-Netv2 by adding inter-scale and intra-scale semantic discrimination enhancing blocks to further exploit global semantic discrimination for the obtained high-resolution features. We trained and evaluated our HNF-Netv2 on the multi-modal Brain Tumor Segmentation Challenge (BraTS) 2021 dataset. The result on the test set shows that our HNF-Netv2 achieved the average Dice scores of 0.878514, 0.872985, and 0.924919, as well as the Hausdorff distances ($95\%$) of 8.9184, 16.2530, and 4.4895 for the enhancing tumor, tumor core, and whole tumor, respectively. Our method won the RSNA 2021 Brain Tumor AI Challenge Prize (Segmentation Task), which ranks 8th out of all 1250 submitted results.
Decompose to Adapt: Cross-domain Object Detection via Feature Disentanglement
Jan 06, 2022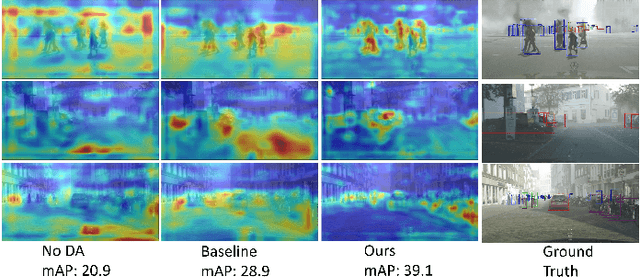
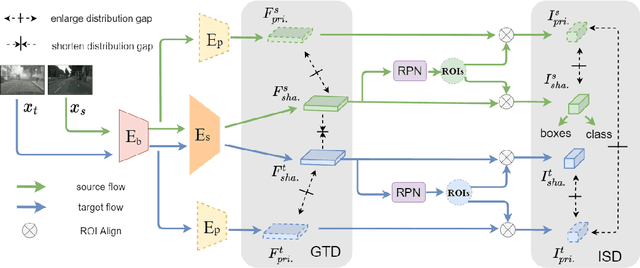
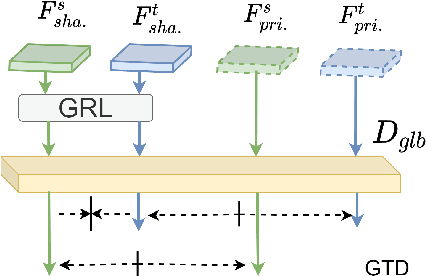

Recent advances in unsupervised domain adaptation (UDA) techniques have witnessed great success in cross-domain computer vision tasks, enhancing the generalization ability of data-driven deep learning architectures by bridging the domain distribution gaps. For the UDA-based cross-domain object detection methods, the majority of them alleviate the domain bias by inducing the domain-invariant feature generation via adversarial learning strategy. However, their domain discriminators have limited classification ability due to the unstable adversarial training process. Therefore, the extracted features induced by them cannot be perfectly domain-invariant and still contain domain-private factors, bringing obstacles to further alleviate the cross-domain discrepancy. To tackle this issue, we design a Domain Disentanglement Faster-RCNN (DDF) to eliminate the source-specific information in the features for detection task learning. Our DDF method facilitates the feature disentanglement at the global and local stages, with a Global Triplet Disentanglement (GTD) module and an Instance Similarity Disentanglement (ISD) module, respectively. By outperforming state-of-the-art methods on four benchmark UDA object detection tasks, our DDF method is demonstrated to be effective with wide applicability.
A Fully Single Loop Algorithm for Bilevel Optimization without Hessian Inverse
Dec 10, 2021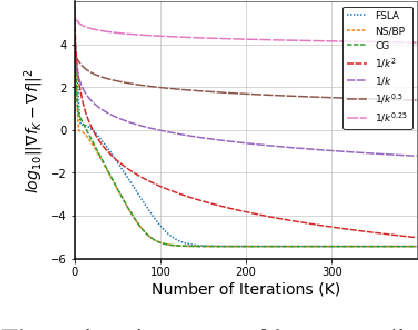
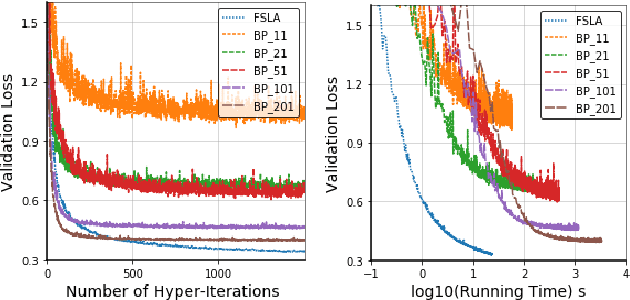
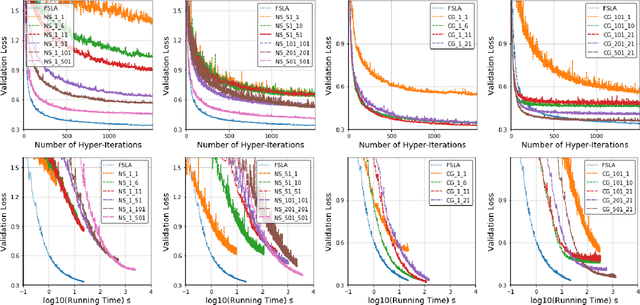
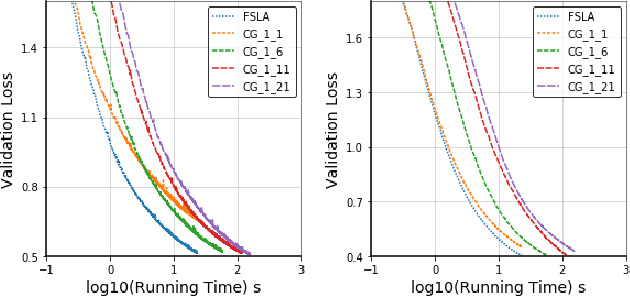
In this paper, we propose a new Hessian inverse free Fully Single Loop Algorithm (FSLA) for bilevel optimization problems. Classic algorithms for bilevel optimization admit a double loop structure which is computationally expensive. Recently, several single loop algorithms have been proposed with optimizing the inner and outer variable alternatively. However, these algorithms not yet achieve fully single loop. As they overlook the loop needed to evaluate the hyper-gradient for a given inner and outer state. In order to develop a fully single loop algorithm, we first study the structure of the hyper-gradient and identify a general approximation formulation of hyper-gradient computation that encompasses several previous common approaches, e.g. back-propagation through time, conjugate gradient, \emph{etc.} Based on this formulation, we introduce a new state variable to maintain the historical hyper-gradient information. Combining our new formulation with the alternative update of the inner and outer variables, we propose an efficient fully single loop algorithm. We theoretically show that the error generated by the new state can be bounded and our algorithm converges with the rate of $O(\epsilon^{-2})$. Finally, we verify the efficacy our algorithm empirically through multiple bilevel optimization based machine learning tasks.
Adaptive Hierarchical Similarity Metric Learning with Noisy Labels
Oct 29, 2021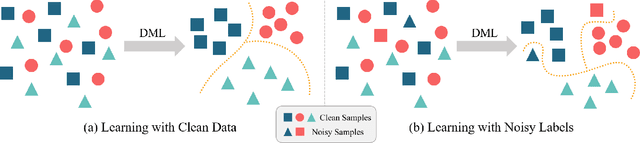
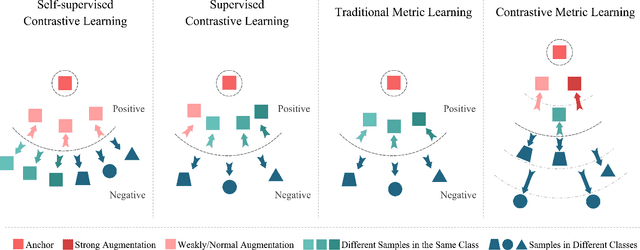
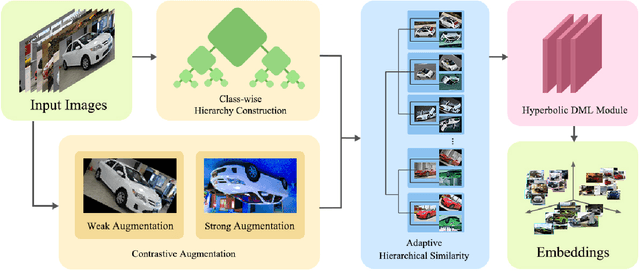
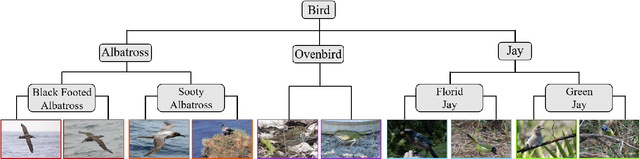
Deep Metric Learning (DML) plays a critical role in various machine learning tasks. However, most existing deep metric learning methods with binary similarity are sensitive to noisy labels, which are widely present in real-world data. Since these noisy labels often cause severe performance degradation, it is crucial to enhance the robustness and generalization ability of DML. In this paper, we propose an Adaptive Hierarchical Similarity Metric Learning method. It considers two noise-insensitive information, \textit{i.e.}, class-wise divergence and sample-wise consistency. Specifically, class-wise divergence can effectively excavate richer similarity information beyond binary in modeling by taking advantage of Hyperbolic metric learning, while sample-wise consistency can further improve the generalization ability of the model using contrastive augmentation. More importantly, we design an adaptive strategy to integrate this information in a unified view. It is noteworthy that the new method can be extended to any pair-based metric loss. Extensive experimental results on benchmark datasets demonstrate that our method achieves state-of-the-art performance compared with current deep metric learning approaches.