 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Step Is Enough: Dispersive MeanFlow Policy Optimization
Jan 28, 2026Real-time robotic control demands fast action generation. However, existing generative policies based on diffusion and flow matching require multi-step sampling, fundamentally limiting deployment in time-critical scenarios. We propose Dispersive MeanFlow Policy Optimization (DMPO), a unified framework that enables true one-step generation through three key components: MeanFlow for mathematically-derived single-step inference without knowledge distillation, dispersive regularization to prevent representation collapse, and reinforcement learning (RL) fine-tuning to surpass expert demonstrations. Experiments across RoboMimic manipulation and OpenAI Gym locomotion benchmarks demonstrate competitive or superior performance compared to multi-step baselines. With our lightweight model architecture and the three key algorithmic components working in synergy, DMPO exceeds real-time control requirements (>120Hz) with 5-20x inference speedup, reaching hundreds of Hertz on high-performance GPUs. Physical deployment on a Franka-Emika-Panda robot validates real-world applicability.
DM1: MeanFlow with Dispersive Regularization for 1-Step Robotic Manipulation
Oct 09, 2025The ability to learn multi-modal action distributions is indispensable for robotic manipulation policies to perform precise and robust control. Flow-based generative models have recently emerged as a promising solution to learning distributions of actions, offering one-step action generation and thus achieving much higher sampling efficiency compared to diffusion-based methods. However, existing flow-based policies suffer from representation collapse, the inability to distinguish similar visual representations, leading to failures in precise manipulation tasks. We propose DM1 (MeanFlow with Dispersive Regularization for One-Step Robotic Manipulation), a novel flow matching framework that integrates dispersive regularization into MeanFlow to prevent collapse while maintaining one-step efficiency. DM1 employs multiple dispersive regularization variants across different intermediate embedding layers, encouraging diverse representations across training batches without introducing additional network modules or specialized training procedures. Experiments on RoboMimic benchmarks show that DM1 achieves 20-40 times faster inference (0.07s vs. 2-3.5s) and improves success rates by 10-20 percentage points, with the Lift task reaching 99% success over 85% of the baseline. Real-robot deployment on a Franka Panda further validates that DM1 transfers effectively from simulation to the physical world. To the best of our knowledge, this is the first work to leverage representation regularization to enable flow-based policies to achieve strong performance in robotic manipulation, establishing a simple yet powerful approach for efficient and robust manipulation.
FB-MSTCN: A Full-Band Single-Channel Speech Enhancement Method Based on Multi-Scale Temporal Convolutional Network
Mar 15, 2022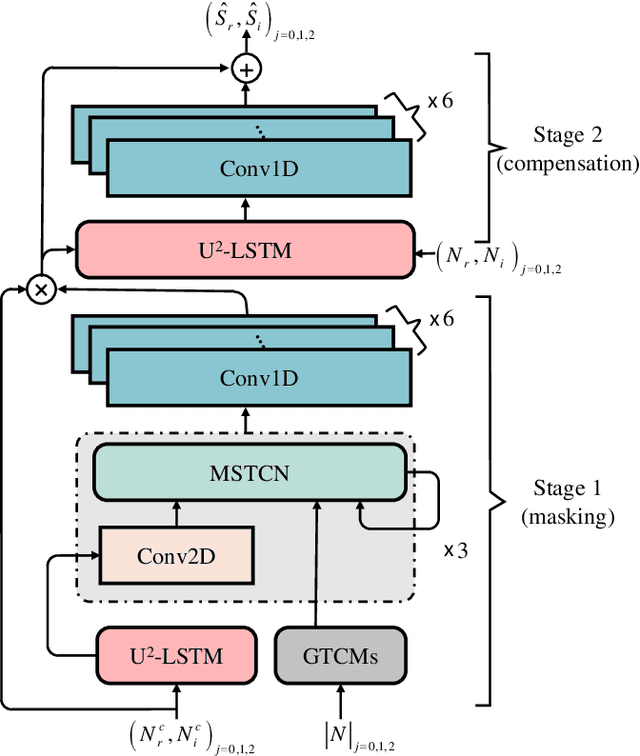
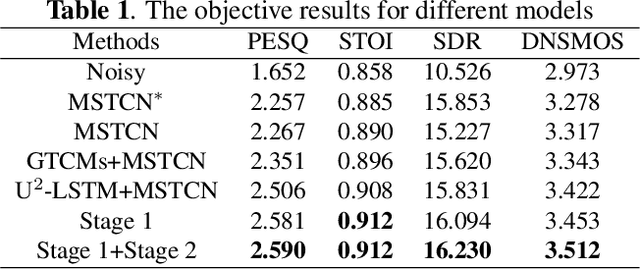
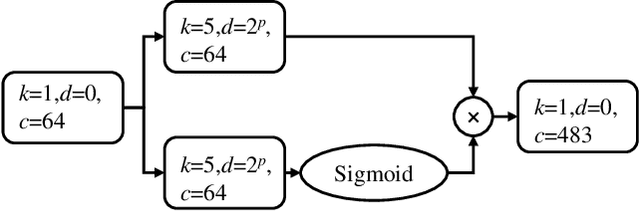
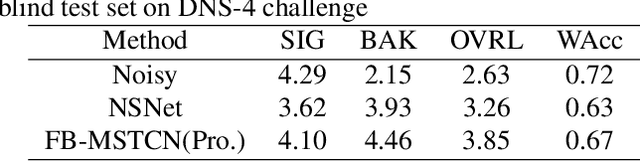
In recent years, deep learning-based approaches have significantly improved the performance of single-channel speech enhancement. However, due to the limitation of training data and computational complexity, real-time enhancement of full-band (48 kHz) speech signals is still very challenging. Because of the low energy of spectral information in the high-frequency part, it is more difficult to directly model and enhance the full-band spectrum using neural networks. To solve this problem, this paper proposes a two-stage real-time speech enhancement model with extraction-interpolation mechanism for a full-band signal. The 48 kHz full-band time-domain signal is divided into three sub-channels by extracting, and a two-stage processing scheme of `masking + compensation' is proposed to enhance the signal in the complex domain. After the two-stage enhancement, the enhanced full-band speech signal is restored by interval interpolation. In the subjective listening and word accuracy test, our proposed model achieves superior performance and outperforms the baseline model overall by 0.59 MOS and 4.0% WAcc for the non-personalized speech denoising task.