 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoW-Bench: Evaluating Fine-Grained Acoustic Perception in Audio-Language Models via Marine Mammal Vocalizations
Aug 28, 2025



Large audio language models (LALMs) extend language understanding into the auditory domain, yet their ability to perform low-level listening, such as pitch and duration detection, remains underexplored. However, low-level listening is critical for real-world, out-of-distribution tasks where models must reason about unfamiliar sounds based on fine-grained acoustic cues. To address this gap, we introduce the World-of-Whale benchmark (WoW-Bench) to evaluate low-level auditory perception and cognition using marine mammal vocalizations. WoW-bench is composed of a Perception benchmark for categorizing novel sounds and a Cognition benchmark, inspired by Bloom's taxonomy, to assess the abilities to remember, understand, apply, and analyze sound events. For the Cognition benchmark, we additionally introduce distractor questions to evaluate whether models are truly solving problems through listening rather than relying on other heuristics. Experiments with state-of-the-art LALMs show performance far below human levels, indicating a need for stronger auditory grounding in LALMs.
ViSAGe: Video-to-Spatial Audio Generation
Jun 13, 2025



Spatial audio is essential for enhancing the immersiveness of audio-visual experiences, yet its production typically demands complex recording systems and specialized expertise. In this work, we address a novel problem of generating first-order ambisonics, a widely used spatial audio format, directly from silent videos. To support this task, we introduce YT-Ambigen, a dataset comprising 102K 5-second YouTube video clips paired with corresponding first-order ambisonics. We also propose new evaluation metrics to assess the spatial aspect of generated audio based on audio energy maps and saliency metrics. Furthermore, we present Video-to-Spatial Audio Generation (ViSAGe), an end-to-end framework that generates first-order ambisonics from silent video frames by leveraging CLIP visual features, autoregressive neural audio codec modeling with both directional and visual guidance. Experimental results demonstrate that ViSAGe produces plausible and coherent first-order ambisonics, outperforming two-stage approaches consisting of video-to-audio generation and audio spatialization. Qualitative examples further illustrate that ViSAGe generates temporally aligned high-quality spatial audio that adapts to viewpoint changes.
Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates
May 28, 2025While pre-trained multimodal representations (e.g., CLIP) have shown impressive capabilities, they exhibit significant compositional vulnerabilities leading to counterintuitive judgments. We introduce Multimodal Adversarial Compositionality (MAC), a benchmark that leverages large language models (LLMs) to generate deceptive text samples to exploit these vulnerabilities across different modalities and evaluates them through both sample-wise attack success rate and group-wise entropy-based diversity. To improve zero-shot methods, we propose a self-training approach that leverages rejection-sampling fine-tuning with diversity-promoting filtering, which enhances both attack success rate and sample diversity. Using smaller language models like Llama-3.1-8B, our approach demonstrates superior performance in revealing compositional vulnerabilities across various multimodal representations, including images, videos, and audios.
ReSpec: Relevance and Specificity Grounded Online Filtering for Learning on Video-Text Data Streams
Apr 21, 2025The rapid growth of video-text data presents challenges in storage and computation during training. Online learning, which processes streaming data in real-time, offers a promising solution to these issues while also allowing swift adaptations in scenarios demanding real-time responsiveness. One strategy to enhance the efficiency and effectiveness of learning involves identifying and prioritizing data that enhances performance on target downstream tasks. We propose Relevance and Specificity-based online filtering framework (ReSpec) that selects data based on four criteria: (i) modality alignment for clean data, (ii) task relevance for target focused data, (iii) specificity for informative and detailed data, and (iv) efficiency for low-latency processing. Relevance is determined by the probabilistic alignment of incoming data with downstream tasks, while specificity employs the distance to a root embedding representing the least specific data as an efficient proxy for informativeness. By establishing reference points from target task data, ReSpec filters incoming data in real-time, eliminating the need for extensive storage and compute. Evaluating on large-scale datasets WebVid2M and VideoCC3M, ReSpec attains state-of-the-art performance on five zeroshot video retrieval tasks, using as little as 5% of the data while incurring minimal compute. The source code is available at https://github.com/cdjkim/ReSpec.
Spherical World-Locking for Audio-Visual Localization in Egocentric Videos
Aug 09, 2024



Egocentric videos provide comprehensive contexts for user and scene understanding, spanning multisensory perception to behavioral interaction. We propose Spherical World-Locking (SWL) as a general framework for egocentric scene representation, which implicitly transforms multisensory streams with respect to measurements of head orientation. Compared to conventional head-locked egocentric representations with a 2D planar field-of-view, SWL effectively offsets challenges posed by self-motion, allowing for improved spatial synchronization between input modalities. Using a set of multisensory embeddings on a worldlocked sphere, we design a unified encoder-decoder transformer architecture that preserves the spherical structure of the scene representation, without requiring expensive projections between image and world coordinate systems. We evaluate the effectiveness of the proposed framework on multiple benchmark tasks for egocentric video understanding, including audio-visual active speaker localization, auditory spherical source localization, and behavior anticipation in everyday activities.
Dense 2D-3D Indoor Prediction with Sound via Aligned Cross-Modal Distillation
Sep 20, 2023


Sound can convey significant information for spatial reasoning in our daily lives. To endow deep networks with such ability, we address the challenge of dense indoor prediction with sound in both 2D and 3D via cross-modal knowledge distillation. In this work, we propose a Spatial Alignment via Matching (SAM) distillation framework that elicits local correspondence between the two modalities in vision-to-audio knowledge transfer. SAM integrates audio features with visually coherent learnable spatial embeddings to resolve inconsistencies in multiple layers of a student model. Our approach does not rely on a specific input representation, allowing for flexibility in the input shapes or dimensions without performance degradation. With a newly curated benchmark named Dense Auditory Prediction of Surroundings (DAPS), we are the first to tackle dense indoor prediction of omnidirectional surroundings in both 2D and 3D with audio observations. Specifically, for audio-based depth estimation, semantic segmentation, and challenging 3D scene reconstruction, the proposed distillation framework consistently achieves state-of-the-art performance across various metrics and backbone architectures.
Panoramic Vision Transformer for Saliency Detection in 360° Videos
Sep 19, 2022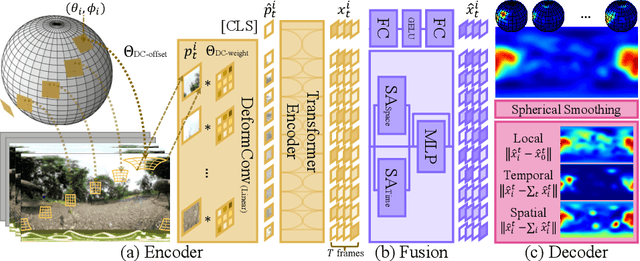
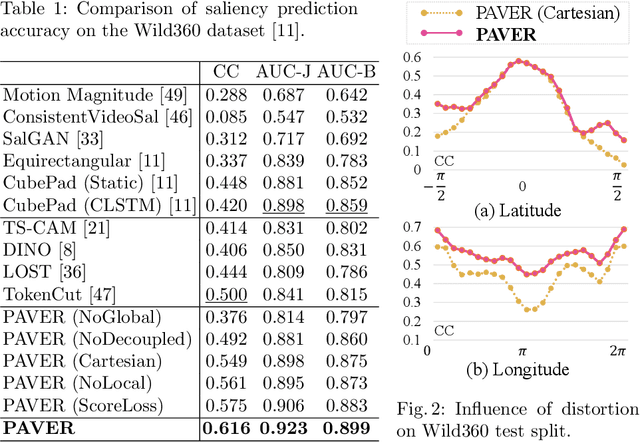

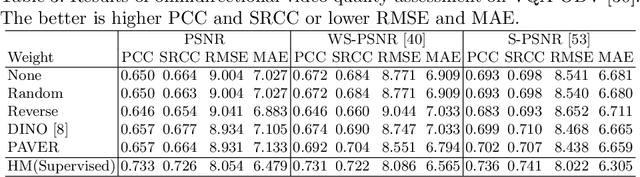
360$^\circ$ video saliency detection is one of the challenging benchmarks for 360$^\circ$ video understanding since non-negligible distortion and discontinuity occur in the projection of any format of 360$^\circ$ videos, and capture-worthy viewpoint in the omnidirectional sphere is ambiguous by nature. We present a new framework named Panoramic Vision Transformer (PAVER). We design the encoder using Vision Transformer with deformable convolution, which enables us not only to plug pretrained models from normal videos into our architecture without additional modules or finetuning but also to perform geometric approximation only once, unlike previous deep CNN-based approaches. Thanks to its powerful encoder, PAVER can learn the saliency from three simple relative relations among local patch features, outperforming state-of-the-art models for the Wild360 benchmark by large margins without supervision or auxiliary information like class activation. We demonstrate the utility of our saliency prediction model with the omnidirectional video quality assessment task in VQA-ODV, where we consistently improve performance without any form of supervision, including head movement.
Multimodal Knowledge Alignment with Reinforcement Learning
May 25, 2022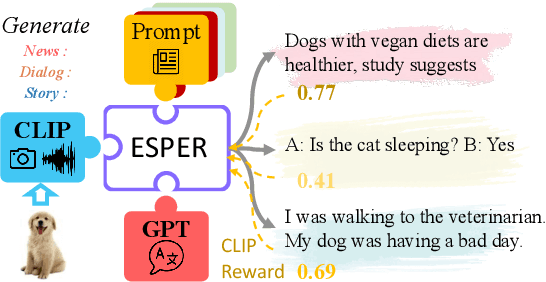
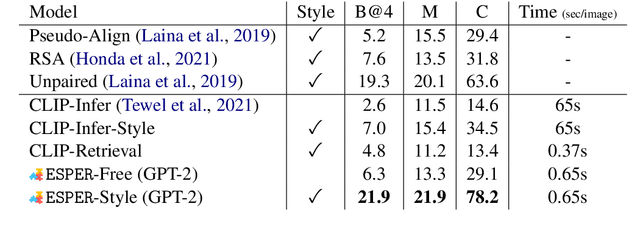
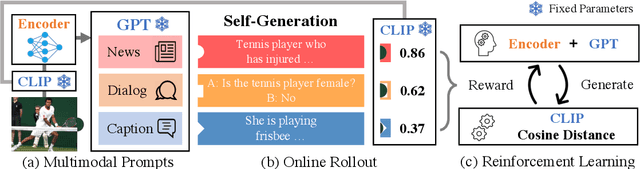
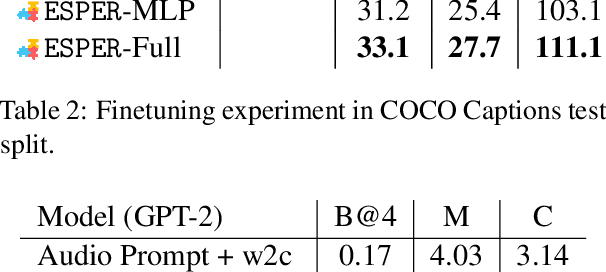
Large language models readily adapt to novel settings, even without task-specific training data. Can their zero-shot capacity be extended to multimodal inputs? In this work, we propose ESPER which extends language-only zero-shot models to unseen multimodal tasks, like image and audio captioning. Our key novelty is to use reinforcement learning to align multimodal inputs to language model generations without direct supervision: for example, in the image case our reward optimization relies only on cosine similarity derived from CLIP, and thus requires no additional explicitly paired (image, caption) data. Because the parameters of the language model are left unchanged, the model maintains its capacity for zero-shot generalization. Experiments demonstrate that ESPER outperforms baselines and prior work on a variety of zero-shot tasks; these include a new benchmark we collect+release, ESP dataset, which tasks models with generating several diversely-styled captions for each image.
Pano-AVQA: Grounded Audio-Visual Question Answering on 360$^\circ$ Videos
Oct 11, 2021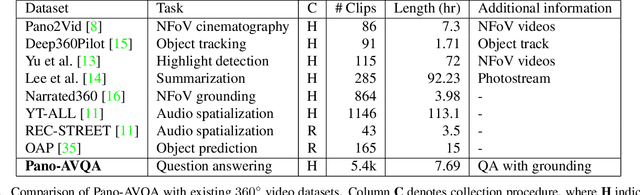
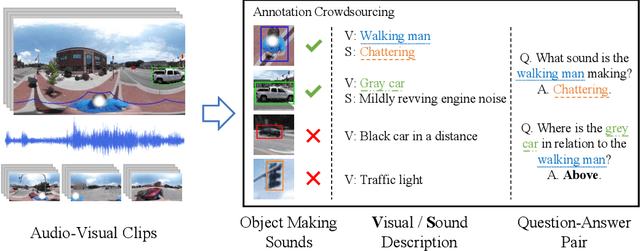
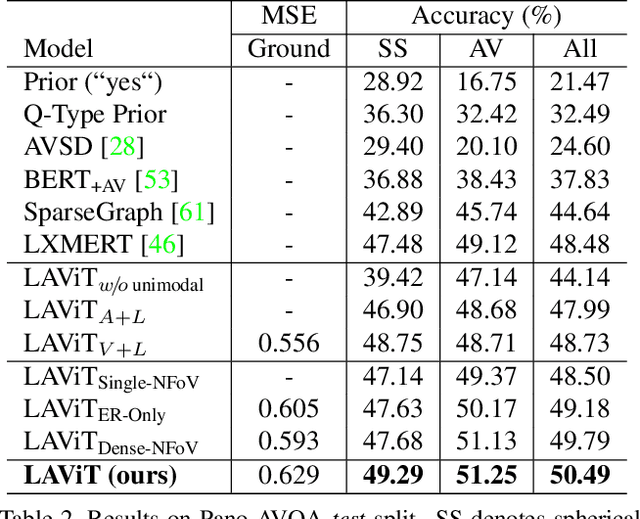
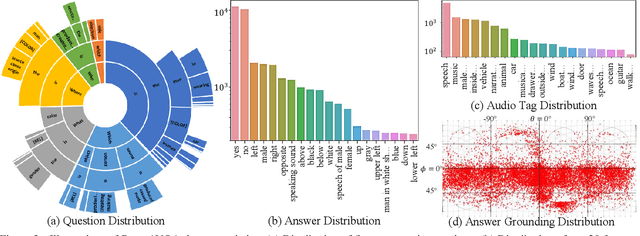
360$^\circ$ videos convey holistic views for the surroundings of a scene. It provides audio-visual cues beyond pre-determined normal field of views and displays distinctive spatial relations on a sphere. However, previous benchmark tasks for panoramic videos are still limited to evaluate the semantic understanding of audio-visual relationships or spherical spatial property in surroundings. We propose a novel benchmark named Pano-AVQA as a large-scale grounded audio-visual question answering dataset on panoramic videos. Using 5.4K 360$^\circ$ video clips harvested online, we collect two types of novel question-answer pairs with bounding-box grounding: spherical spatial relation QAs and audio-visual relation QAs. We train several transformer-based models from Pano-AVQA, where the results suggest that our proposed spherical spatial embeddings and multimodal training objectives fairly contribute to a better semantic understanding of the panoramic surroundings on the dataset.
Video Summarization through Human Detection on a Social Robot
Jan 30, 2019


In this paper, we propose a novel video summarization system which captures images via a social robot's camera but processes images on a server. The system helps remote family members easily be aware of their seniors' daily activities via summaries. The system utilizes two vision-based algorithms, one for pose estimation and the other for human detection, to locate people in frames to guide the robot through people tracking and filter out improper frames including the ones without a person or blurred, or with a person but too small or not at the center of the frame. The system utilizes a video summarization method to select keyframes by balancing the representativeness and diversity. We conduct experiments of the system through three in-the-wild studies and evaluate the performance through human subject studies. Experimental results show that the users of the system think the system is promising and useful for their needs.