 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-Spec: Expert Budgeting for Efficient Speculative Decoding
Feb 17, 2026Speculative decoding accelerates Large Language Model (LLM) inference by verifying multiple drafted tokens in parallel. However, for Mixture-of-Experts (MoE) models, this parallelism introduces a severe bottleneck: large draft trees activate many unique experts, significantly increasing memory pressure and diminishing speedups from speculative decoding relative to autoregressive decoding. Prior methods reduce speculation depth when MoE verification becomes expensive. We propose MoE-Spec, a training-free verification-time expert budgeting method that decouples speculation depth from memory cost by enforcing a fixed expert capacity limit at each layer, loading only the experts that contribute most to verification and dropping the long tail of rarely used experts that drive bandwidth overhead. Experiments across multiple model scales and datasets show that this method yields 10--30\% higher throughput than state-of-the-art speculative decoding baselines (EAGLE-3) at comparable quality, with flexibility to trade accuracy for further latency reductions through tighter budgets.
CLAA: Cross-Layer Attention Aggregation for Accelerating LLM Prefill
Feb 17, 2026The prefill stage in long-context LLM inference remains a computational bottleneck. Recent token-ranking heuristics accelerate inference by selectively processing a subset of semantically relevant tokens. However, existing methods suffer from unstable token importance estimation, often varying between layers. Evaluating token-ranking quality independently from heuristic-specific architectures is challenging. To address this, we introduce an Answer-Informed Oracle, which defines ground-truth token importance by measuring attention from generated answers back to the prompt. This oracle reveals that existing heuristics exhibit high variance across layers: rankings can degrade sharply at specific layers, a failure mode invisible to end-to-end benchmarks. The diagnosis suggests a simple fix: aggregate scores across layers rather than relying on any single one. We implement this as Cross-Layer Attention Aggregation (CLAA), which closes the gap to the oracle upper bound and reduces Time-to-First-Token (TTFT) by up to 39\% compared to the Full KV Cache baseline.
R-Sparse: Rank-Aware Activation Sparsity for Efficient LLM Inference
Apr 28, 2025Large Language Models (LLMs), while demonstrating remarkable capabilities across various applications, present significant challenges during inference due to their substantial model size, especially when deployed on edge devices. Activation sparsity offers a promising solution to reduce computation and memory movement, enabling more efficient inference, particularly for small-batch on-device applications. However, current approaches face limitations with non-ReLU activation function, which are foundational to most advanced LLMs, or require heavy continual training. Additionally, the difficulty in predicting active channels and limited achievable sparsity ratios constrain the effectiveness of activation sparsity-based methods. In this paper, we introduce R-Sparse, a training-free activation sparsity approach capable of achieving high sparsity levels in advanced LLMs. We conducted two preliminary investigations into how different components contribute to the output within a single linear layer and found two key observations: (i) the non-sparse components of the input function can be regarded as a few bias terms, and (ii) The full computation can be effectively approximated by an appropriate combination of input channels and weight singular values. Building on this, we replace the linear layers in LLMs with a rank-aware sparse inference method that leverages the sparsity of input channels and singular value components, eliminating the need for active channel prediction like the output sparsity based approaches. Experiments on Llama-2/3 and Mistral models across ten diverse tasks demonstrate that R-Sparse achieves comparable performance at 50% model-level sparsity, resulting in a significant 43% end-to-end efficient improvements with customized kernels.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022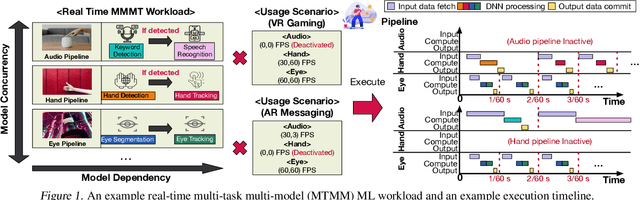
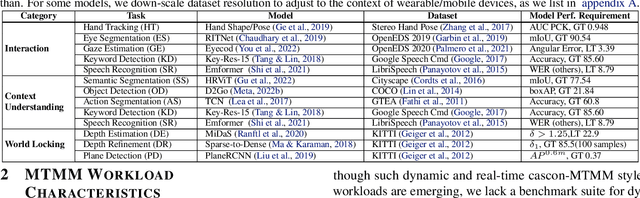

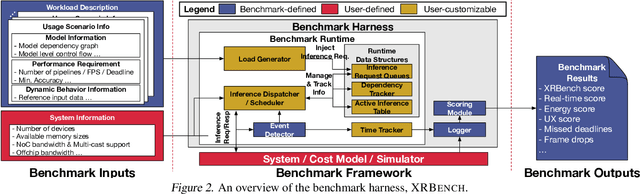
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.