 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Distillation for Worst-class Performance
Jun 13, 2022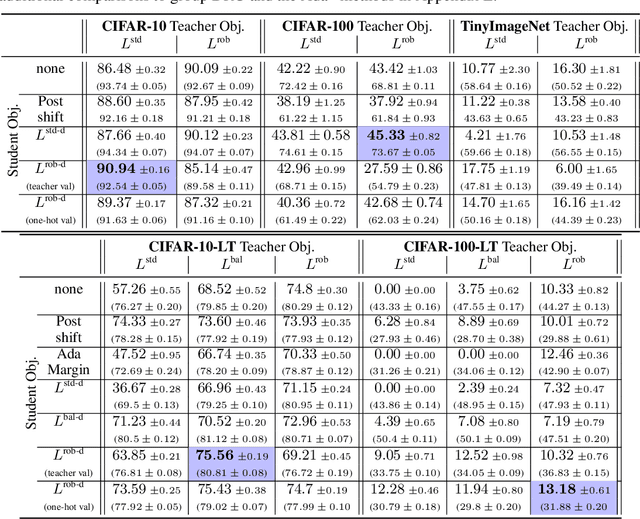
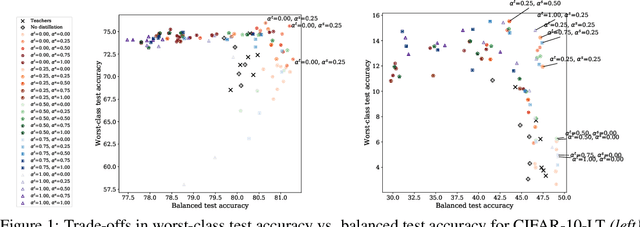
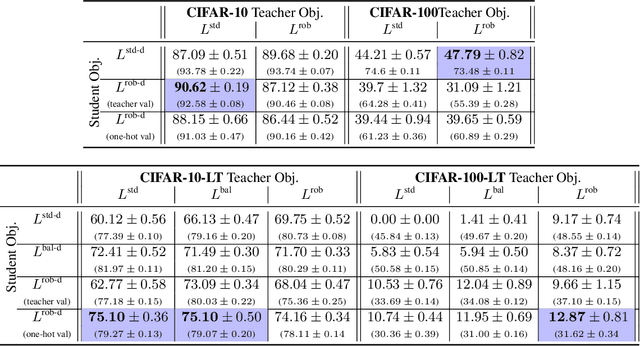
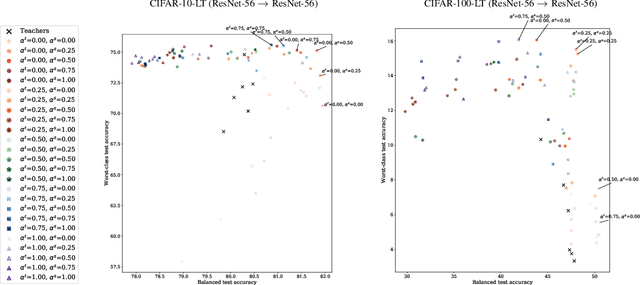
Knowledge distillation has proven to be an effective technique in improving the performance a student model using predictions from a teacher model. However, recent work has shown that gains in average efficiency are not uniform across subgroups in the data, and in particular can often come at the cost of accuracy on rare subgroups and classes. To preserve strong performance across classes that may follow a long-tailed distribution, we develop distillation techniques that are tailored to improve the student's worst-class performance. Specifically, we introduce robust optimization objectives in different combinations for the teacher and student, and further allow for training with any tradeoff between the overall accuracy and the robust worst-class objective. We show empirically that our robust distillation techniques not only achieve better worst-class performance, but also lead to Pareto improvement in the tradeoff between overall performance and worst-class performance compared to other baseline methods. Theoretically, we provide insights into what makes a good teacher when the goal is to train a robust student.
Implicit Rate-Constrained Optimization of Non-decomposable Objectives
Jul 29, 2021


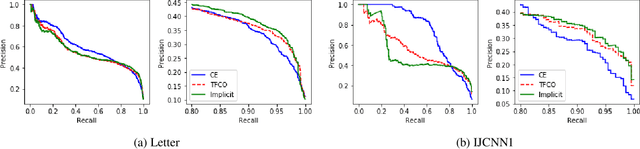
We consider a popular family of constrained optimization problems arising in machine learning that involve optimizing a non-decomposable evaluation metric with a certain thresholded form, while constraining another metric of interest. Examples of such problems include optimizing the false negative rate at a fixed false positive rate, optimizing precision at a fixed recall, optimizing the area under the precision-recall or ROC curves, etc. Our key idea is to formulate a rate-constrained optimization that expresses the threshold parameter as a function of the model parameters via the Implicit Function theorem. We show how the resulting optimization problem can be solved using standard gradient based methods. Experiments on benchmark datasets demonstrate the effectiveness of our proposed method over existing state-of-the art approaches for these problems. The code for the proposed method is available at https://github.com/google-research/google-research/tree/master/implicit_constrained_optimization .
Training Over-parameterized Models with Non-decomposable Objectives
Jul 09, 2021
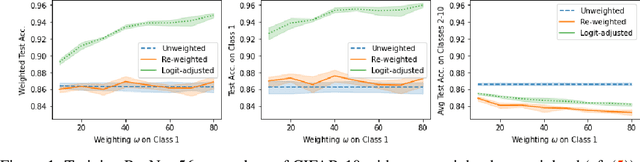

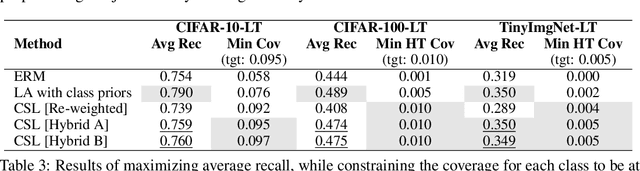
Many modern machine learning applications come with complex and nuanced design goals such as minimizing the worst-case error, satisfying a given precision or recall target, or enforcing group-fairness constraints. Popular techniques for optimizing such non-decomposable objectives reduce the problem into a sequence of cost-sensitive learning tasks, each of which is then solved by re-weighting the training loss with example-specific costs. We point out that the standard approach of re-weighting the loss to incorporate label costs can produce unsatisfactory results when used to train over-parameterized models. As a remedy, we propose new cost-sensitive losses that extend the classical idea of logit adjustment to handle more general cost matrices. Our losses are calibrated, and can be further improved with distilled labels from a teacher model. Through experiments on benchmark image datasets, we showcase the effectiveness of our approach in training ResNet models with common robust and constrained optimization objectives.
Churn Reduction via Distillation
Jun 04, 2021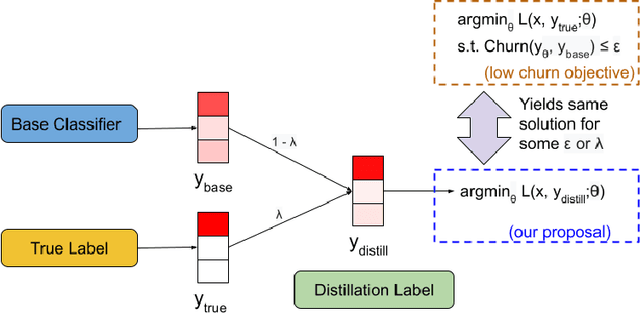
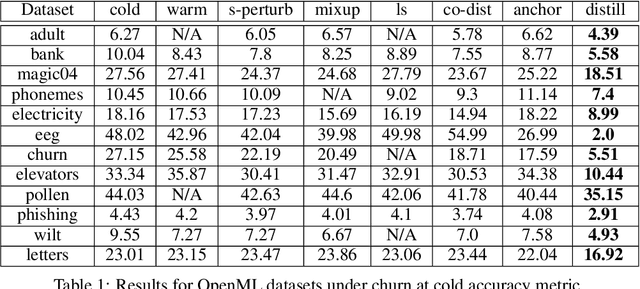
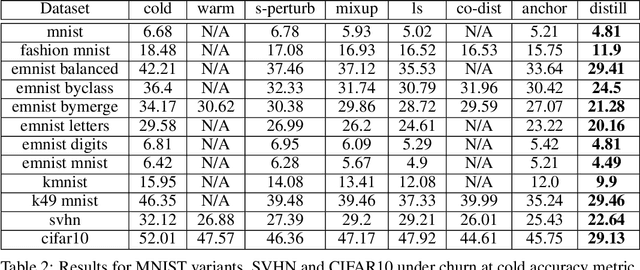
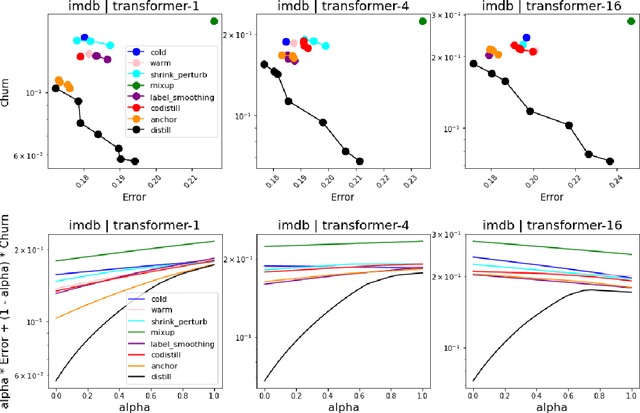
In real-world systems, models are frequently updated as more data becomes available, and in addition to achieving high accuracy, the goal is to also maintain a low difference in predictions compared to the base model (i.e. predictive ``churn''). If model retraining results in vastly different behavior, then it could cause negative effects in downstream systems, especially if this churn can be avoided with limited impact on model accuracy. In this paper, we show an equivalence between training with distillation using the base model as the teacher and training with an explicit constraint on the predictive churn. We then show that distillation performs strongly for low churn training against a number of recent baselines on a wide range of datasets and model architectures, including fully-connected networks, convolutional networks, and transformers.
Optimizing Black-box Metrics with Iterative Example Weighting
Feb 18, 2021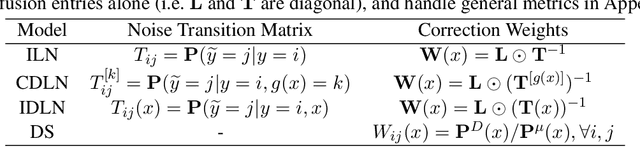
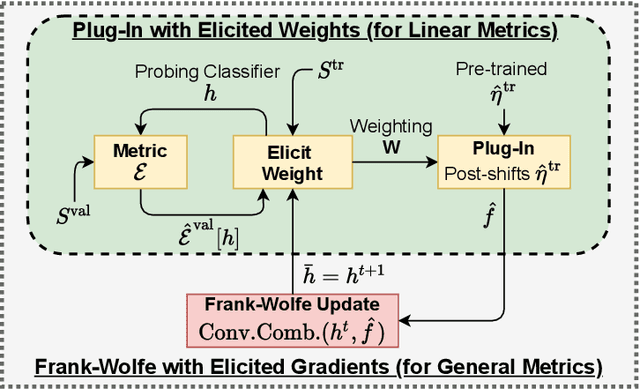
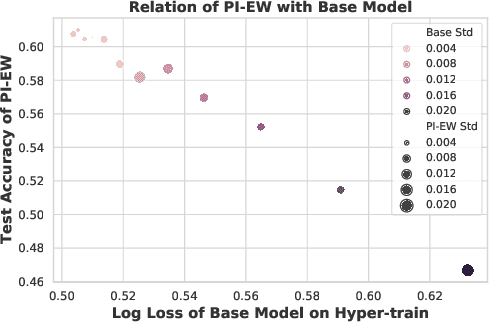
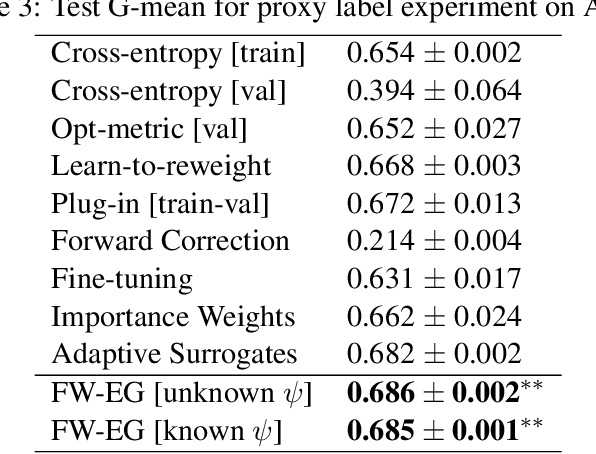
We consider learning to optimize a classification metric defined by a black-box function of the confusion matrix. Such black-box learning settings are ubiquitous, for example, when the learner only has query access to the metric of interest, or in noisy-label and domain adaptation applications where the learner must evaluate the metric via performance evaluation using a small validation sample. Our approach is to adaptively learn example weights on the training dataset such that the resulting weighted objective best approximates the metric on the validation sample. We show how to model and estimate the example weights and use them to iteratively post-shift a pre-trained class probability estimator to construct a classifier. We also analyze the resulting procedure's statistical properties. Experiments on various label noise, domain shift, and fair classification setups confirm that our proposal is better than the individual state-of-the-art baselines for each application.
Distilling Double Descent
Feb 13, 2021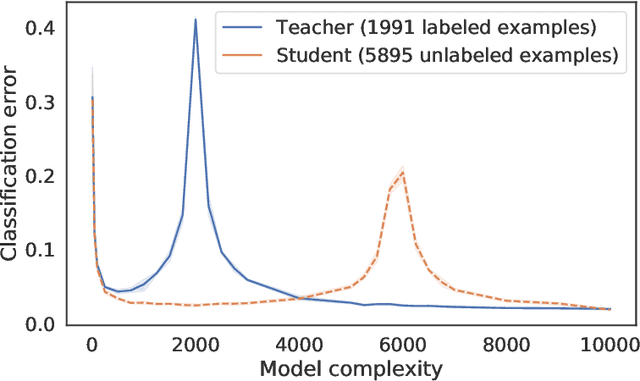
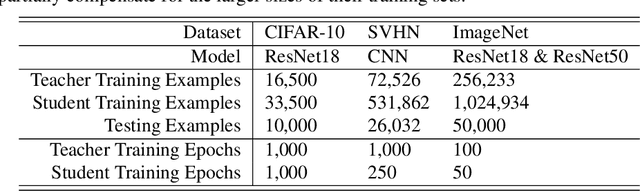
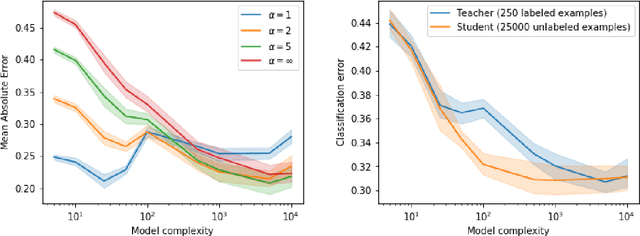
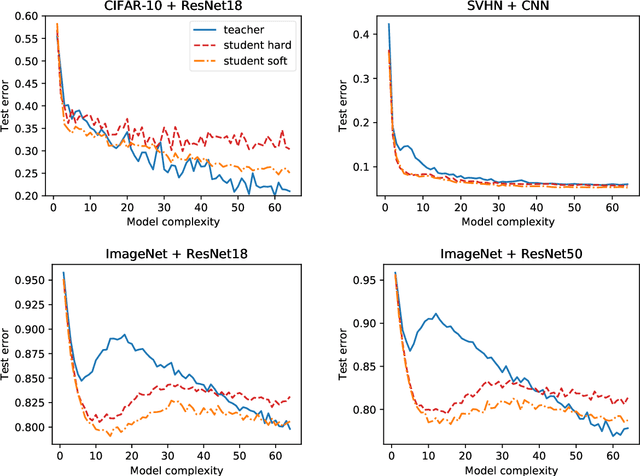
Distillation is the technique of training a "student" model based on examples that are labeled by a separate "teacher" model, which itself is trained on a labeled dataset. The most common explanations for why distillation "works" are predicated on the assumption that student is provided with \emph{soft} labels, \eg probabilities or confidences, from the teacher model. In this work, we show, that, even when the teacher model is highly overparameterized, and provides \emph{hard} labels, using a very large held-out unlabeled dataset to train the student model can result in a model that outperforms more "traditional" approaches. Our explanation for this phenomenon is based on recent work on "double descent". It has been observed that, once a model's complexity roughly exceeds the amount required to memorize the training data, increasing the complexity \emph{further} can, counterintuitively, result in \emph{better} generalization. Researchers have identified several settings in which it takes place, while others have made various attempts to explain it (thus far, with only partial success). In contrast, we avoid these questions, and instead seek to \emph{exploit} this phenomenon by demonstrating that a highly-overparameterized teacher can avoid overfitting via double descent, while a student trained on a larger independent dataset labeled by this teacher will avoid overfitting due to the size of its training set.
Quadratic Metric Elicitation with Application to Fairness
Nov 03, 2020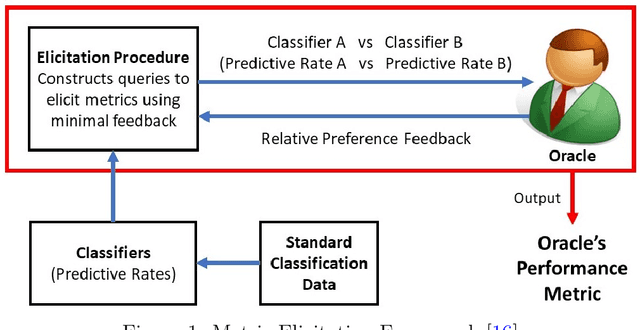
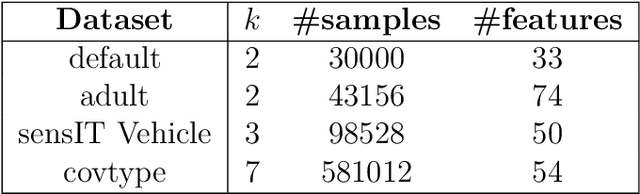
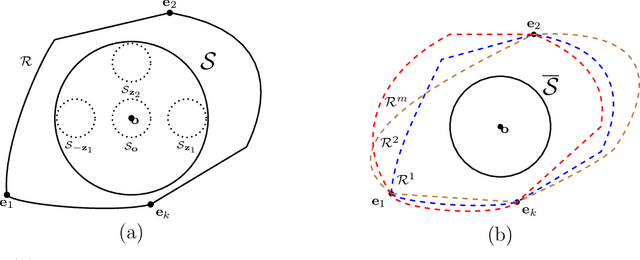
Metric elicitation is a recent framework for eliciting performance metrics that best reflect implicit user preferences. This framework enables a practitioner to adjust the performance metrics based on the application, context, and population at hand. However, available elicitation strategies have been limited to linear (or fractional-linear) functions of predictive rates. In this paper, we develop an approach to elicit from a wider range of complex multiclass metrics defined by quadratic functions of rates by exploiting their local linear structure. We apply this strategy to elicit quadratic metrics for group-based fairness, and also discuss how it can be generalized to higher-order polynomials. Our elicitation strategies require only relative preference feedback and are robust to both feedback and finite sample noise.
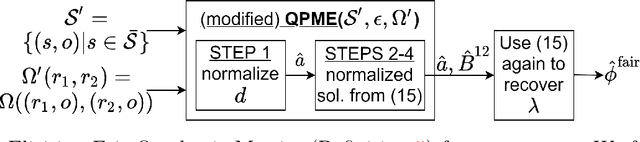
Fair Performance Metric Elicitation
Jun 23, 2020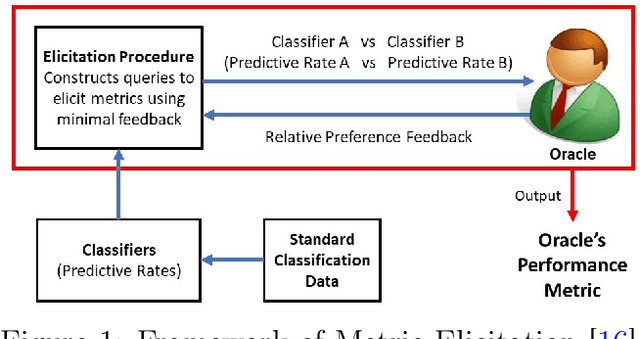


What is a fair performance metric? We consider the choice of fairness metrics through the lens of metric elicitation -- a principled framework for selecting performance metrics that best reflect implicit preferences. The use of metric elicitation enables a practitioner to tune the performance and fairness metrics to the task, context, and population at hand. Specifically, we propose a novel strategy to elicit fair performance metrics for multiclass classification problems with multiple sensitive groups that also includes selecting the trade-off between performance and fairness. The proposed elicitation strategy requires only relative preference feedback and is robust to both finite sample and feedback noise.
Robust Optimization for Fairness with Noisy Protected Groups
Feb 21, 2020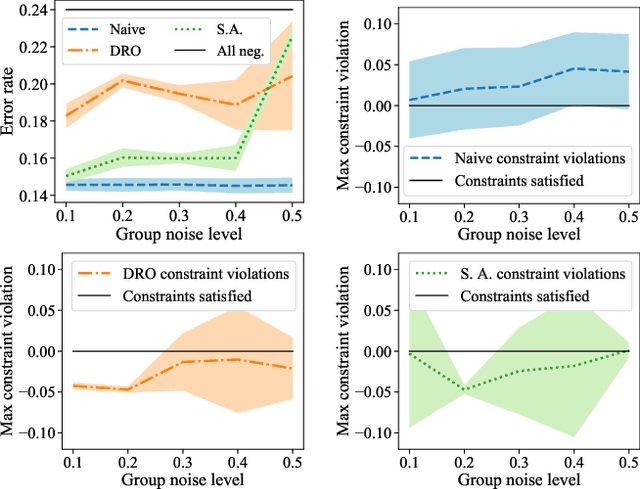
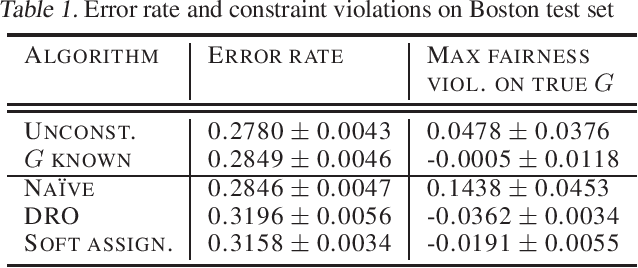

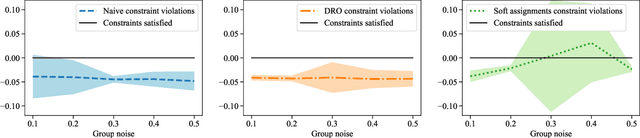
Many existing fairness criteria for machine learning involve equalizing or achieving some metric across \textit{protected groups} such as race or gender groups. However, practitioners trying to audit or enforce such group-based criteria can easily face the problem of noisy or biased protected group information. We study this important practical problem in two ways. First, we study the consequences of na{\"i}vely only relying on noisy protected groups: we provide an upper bound on the fairness violations on the true groups $G$ when the fairness criteria are satisfied on noisy groups $\hat{G}$. Second, we introduce two new approaches using robust optimization that, unlike the na{\"i}ve approach of only relying on $\hat{G}$, are guaranteed to satisfy fairness criteria on the true protected groups $G$ while minimizing a training objective. We provide theoretical guarantees that one such approach converges to an optimal feasible solution. Using two case studies, we empirically show that the robust approaches achieve better true group fairness guarantees than the na{\"i}ve approach.
Optimizing Black-box Metrics with Adaptive Surrogates
Feb 20, 2020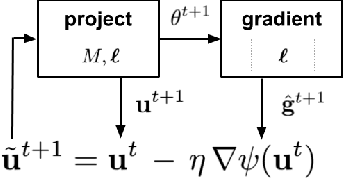
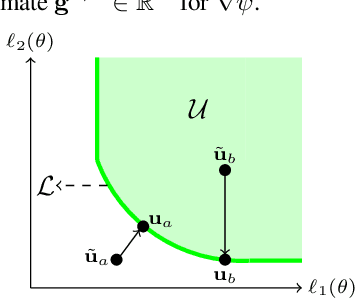
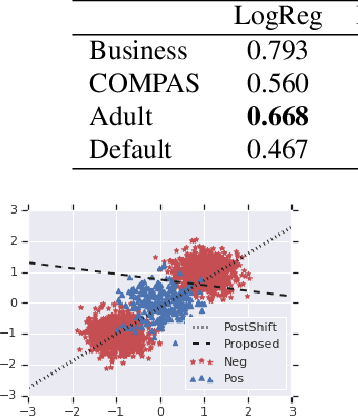
We address the problem of training models with black-box and hard-to-optimize metrics by expressing the metric as a monotonic function of a small number of easy-to-optimize surrogates. We pose the training problem as an optimization over a relaxed surrogate space, which we solve by estimating local gradients for the metric and performing inexact convex projections. We analyze gradient estimates based on finite differences and local linear interpolations, and show convergence of our approach under smoothness assumptions with respect to the surrogates. Experimental results on classification and ranking problems verify the proposal performs on par with methods that know the mathematical formulation, and adds notable value when the form of the metric is unknown.