 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction
Apr 08, 2022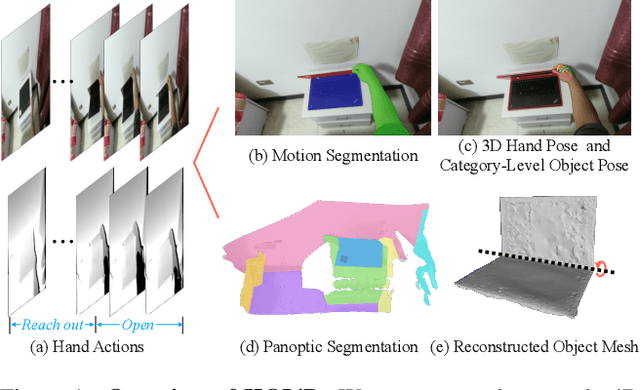

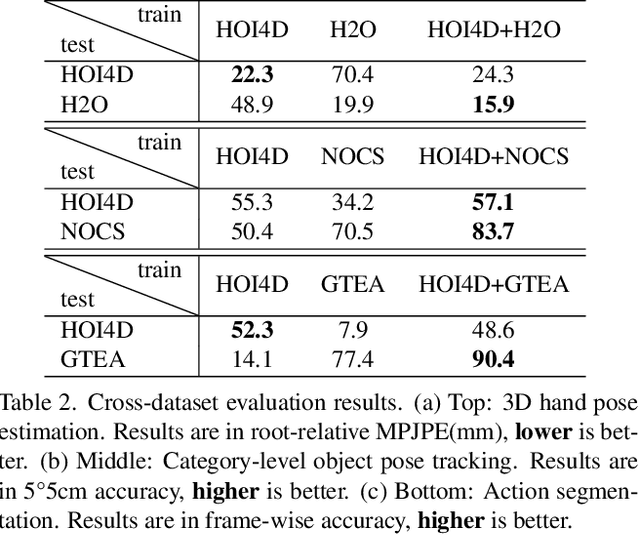
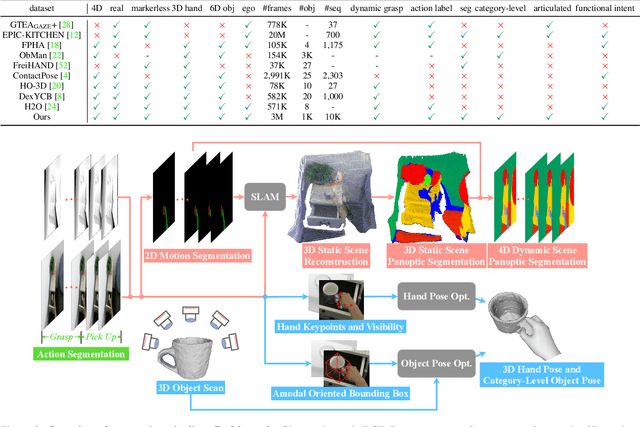
We present HOI4D, a large-scale 4D egocentric dataset with rich annotations, to catalyze the research of category-level human-object interaction. HOI4D consists of 2.4M RGB-D egocentric video frames over 4000 sequences collected by 4 participants interacting with 800 different object instances from 16 categories over 610 different indoor rooms. Frame-wise annotations for panoptic segmentation, motion segmentation, 3D hand pose, category-level object pose and hand action have also been provided, together with reconstructed object meshes and scene point clouds. With HOI4D, we establish three benchmarking tasks to promote category-level HOI from 4D visual signals including semantic segmentation of 4D dynamic point cloud sequences, category-level object pose tracking, and egocentric action segmentation with diverse interaction targets. In-depth analysis shows HOI4D poses great challenges to existing methods and produces great research opportunities.
Learning from Attacks: Attacking Variational Autoencoder for Improving Image Classification
Mar 11, 2022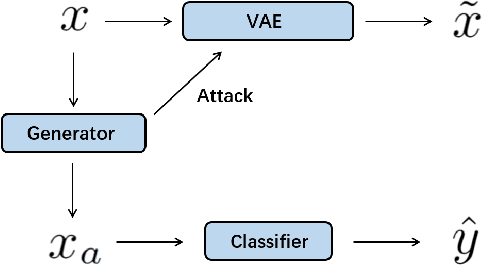
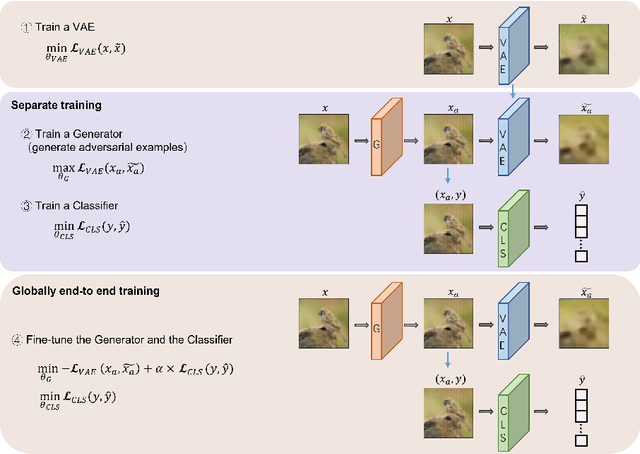
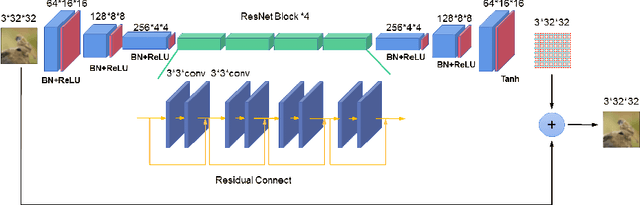
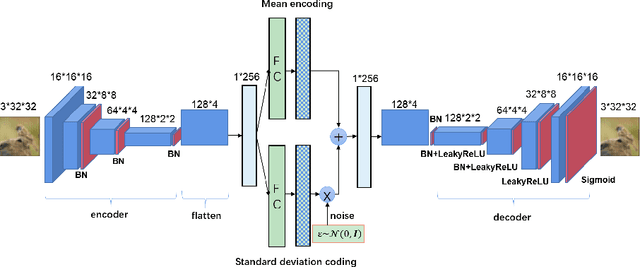
Adversarial attacks are often considered as threats to the robustness of Deep Neural Networks (DNNs). Various defending techniques have been developed to mitigate the potential negative impact of adversarial attacks against task predictions. This work analyzes adversarial attacks from a different perspective. Namely, adversarial examples contain implicit information that is useful to the predictions i.e., image classification, and treat the adversarial attacks against DNNs for data self-expression as extracted abstract representations that are capable of facilitating specific learning tasks. We propose an algorithmic framework that leverages the advantages of the DNNs for data self-expression and task-specific predictions, to improve image classification. The framework jointly learns a DNN for attacking Variational Autoencoder (VAE) networks and a DNN for classification, coined as Attacking VAE for Improve Classification (AVIC). The experiment results show that AVIC can achieve higher accuracy on standard datasets compared to the training with clean examples and the traditional adversarial training.
Learning Category-Level Generalizable Object Manipulation Policy via Generative Adversarial Self-Imitation Learning from Demonstrations
Mar 04, 2022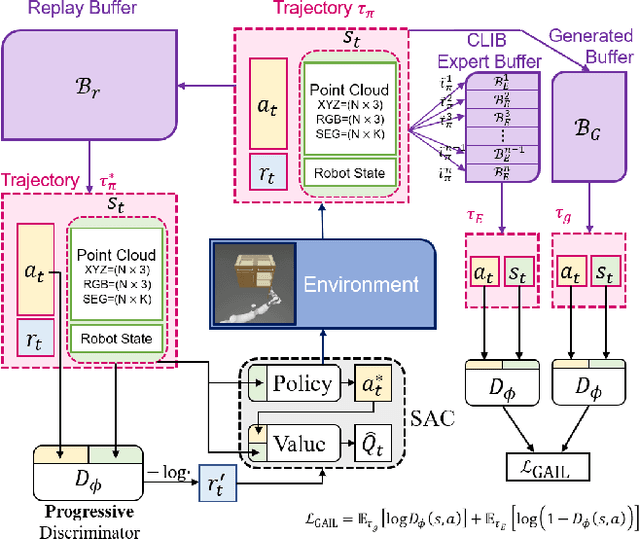
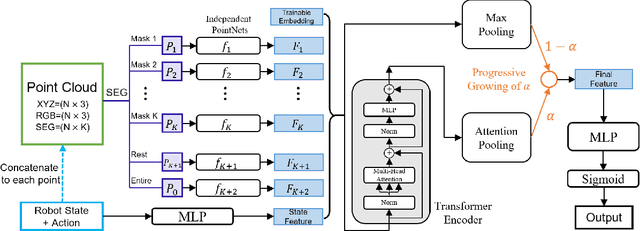
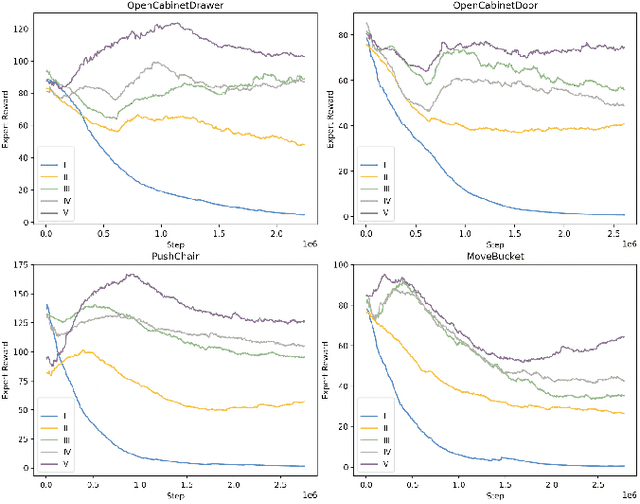
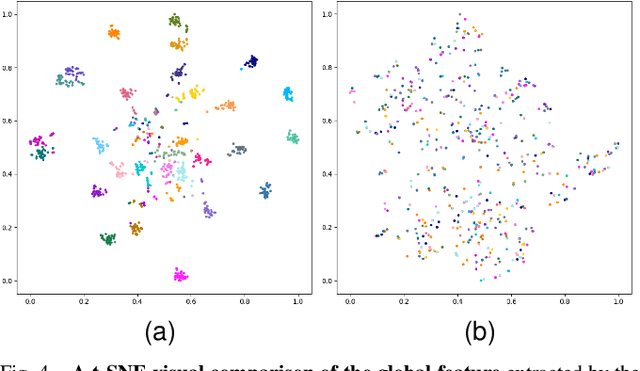
Generalizable object manipulation skills are critical for intelligent and multi-functional robots to work in real-world complex scenes. Despite the recent progress in reinforcement learning, it is still very challenging to learn a generalizable manipulation policy that can handle a category of geometrically diverse articulated objects. In this work, we tackle this category-level object manipulation policy learning problem via imitation learning in a task-agnostic manner, where we assume no handcrafted dense rewards but only a terminal reward. Given this novel and challenging generalizable policy learning problem, we identify several key issues that can fail the previous imitation learning algorithms and hinder the generalization to unseen instances. We then propose several general but critical techniques, including generative adversarial self-imitation learning from demonstrations, progressive growing of discriminator, and instance-balancing for expert buffer, that accurately pinpoints and tackles these issues and can benefit category-level manipulation policy learning regardless of the tasks. Our experiments on ManiSkill benchmarks demonstrate a remarkable improvement on all tasks and our ablation studies further validate the contribution of each proposed technique.
Unsupervised Domain Adaptation with Dynamics-Aware Rewards in Reinforcement Learning
Oct 26, 2021
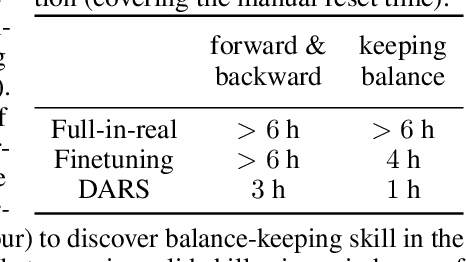
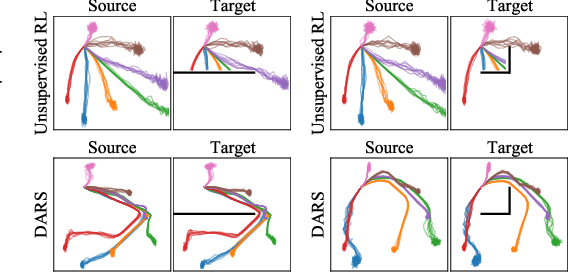
Unsupervised reinforcement learning aims to acquire skills without prior goal representations, where an agent automatically explores an open-ended environment to represent goals and learn the goal-conditioned policy. However, this procedure is often time-consuming, limiting the rollout in some potentially expensive target environments. The intuitive approach of training in another interaction-rich environment disrupts the reproducibility of trained skills in the target environment due to the dynamics shifts and thus inhibits direct transferring. Assuming free access to a source environment, we propose an unsupervised domain adaptation method to identify and acquire skills across dynamics. Particularly, we introduce a KL regularized objective to encourage emergence of skills, rewarding the agent for both discovering skills and aligning its behaviors respecting dynamics shifts. This suggests that both dynamics (source and target) shape the reward to facilitate the learning of adaptive skills. We also conduct empirical experiments to demonstrate that our method can effectively learn skills that can be smoothly deployed in target.
Identifying Influential Users in Unknown Social Networks for Adaptive Incentive Allocation Under Budget Restriction
Jul 14, 2021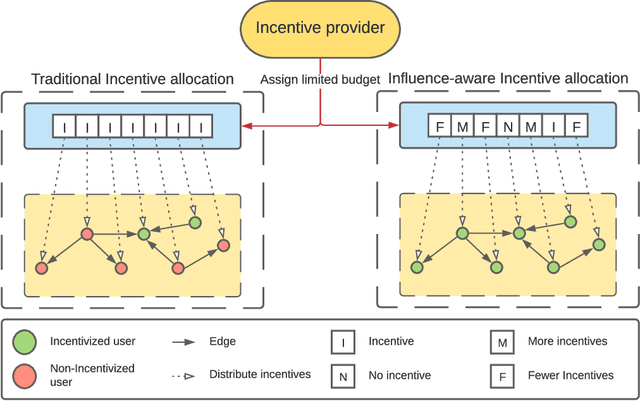
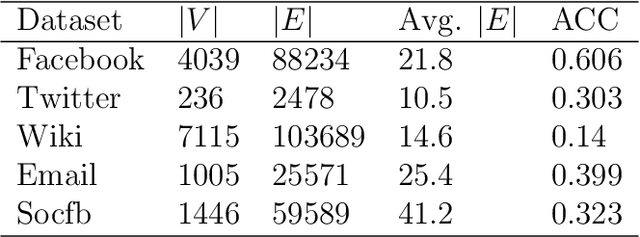
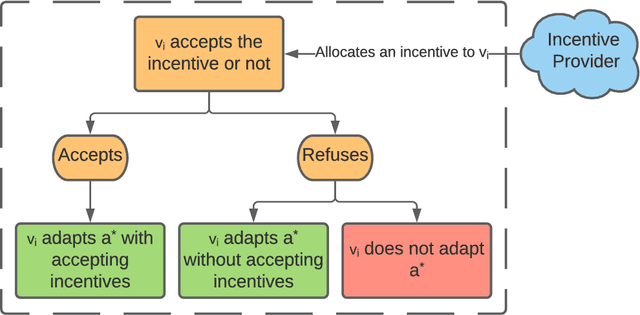
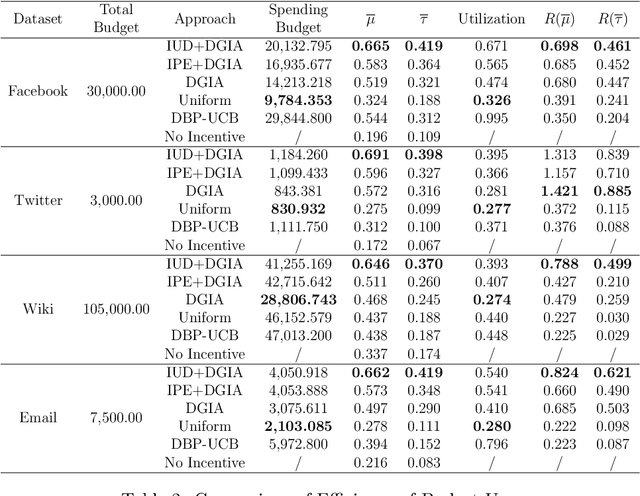
In recent years, recommendation systems have been widely applied in many domains. These systems are impotent in affecting users to choose the behavior that the system expects. Meanwhile, providing incentives has been proven to be a more proactive way to affect users' behaviors. Due to the budget limitation, the number of users who can be incentivized is restricted. In this light, we intend to utilize social influence existing among users to enhance the effect of incentivization. Through incentivizing influential users directly, their followers in the social network are possibly incentivized indirectly. However, in many real-world scenarios, the topological structure of the network is usually unknown, which makes identifying influential users difficult. To tackle the aforementioned challenges, in this paper, we propose a novel algorithm for exploring influential users in unknown networks, which can estimate the influential relationships among users based on their historical behaviors and without knowing the topology of the network. Meanwhile, we design an adaptive incentive allocation approach that determines incentive values based on users' preferences and their influence ability. We evaluate the performance of the proposed approaches by conducting experiments on both synthetic and real-world datasets. The experimental results demonstrate the effectiveness of the proposed approaches.
Deep auxiliary learning for visual localization using colorization task
Jul 01, 2021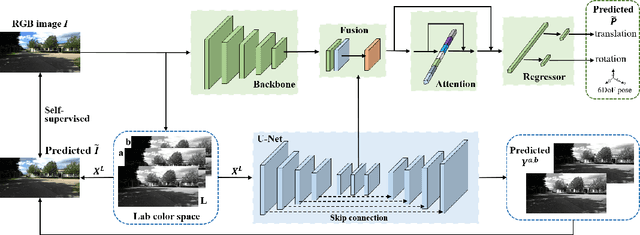
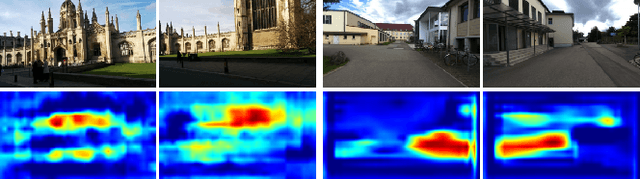
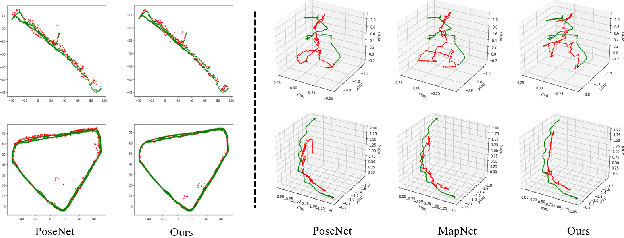

Visual localization is one of the most important components for robotics and autonomous driving. Recently, inspiring results have been shown with CNN-based methods which provide a direct formulation to end-to-end regress 6-DoF absolute pose. Additional information like geometric or semantic constraints is generally introduced to improve performance. Especially, the latter can aggregate high-level semantic information into localization task, but it usually requires enormous manual annotations. To this end, we propose a novel auxiliary learning strategy for camera localization by introducing scene-specific high-level semantics from self-supervised representation learning task. Viewed as a powerful proxy task, image colorization task is chosen as complementary task that outputs pixel-wise color version of grayscale photograph without extra annotations. In our work, feature representations from colorization network are embedded into localization network by design to produce discriminative features for pose regression. Meanwhile an attention mechanism is introduced for the benefit of localization performance. Extensive experiments show that our model significantly improve localization accuracy over state-of-the-arts on both indoor and outdoor datasets.
Analysis and Optimisation of Bellman Residual Errors with Neural Function Approximation
Jun 17, 2021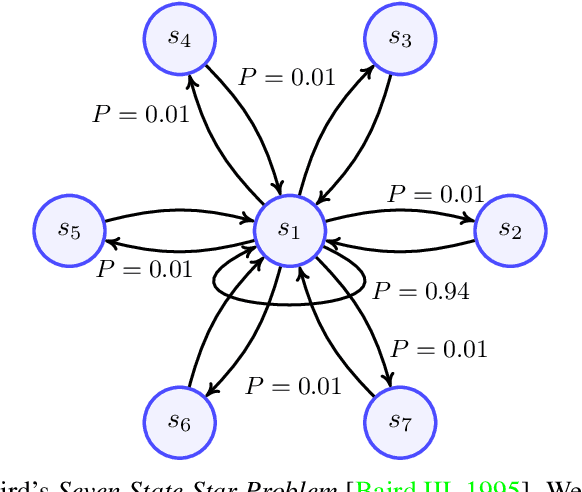
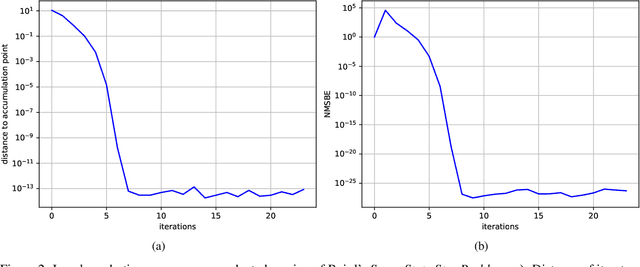
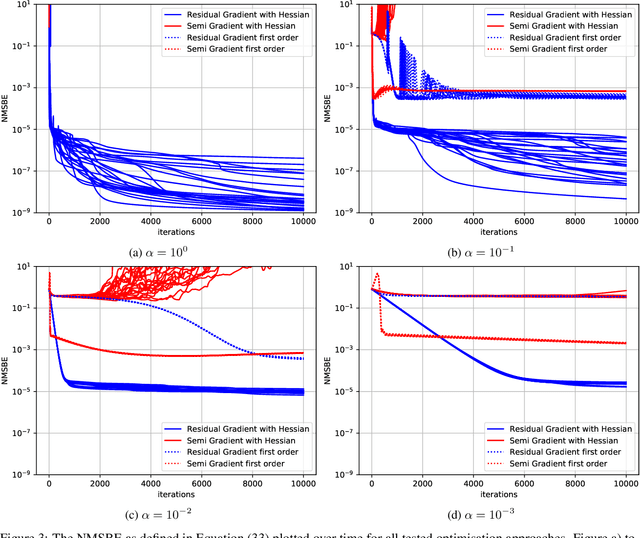
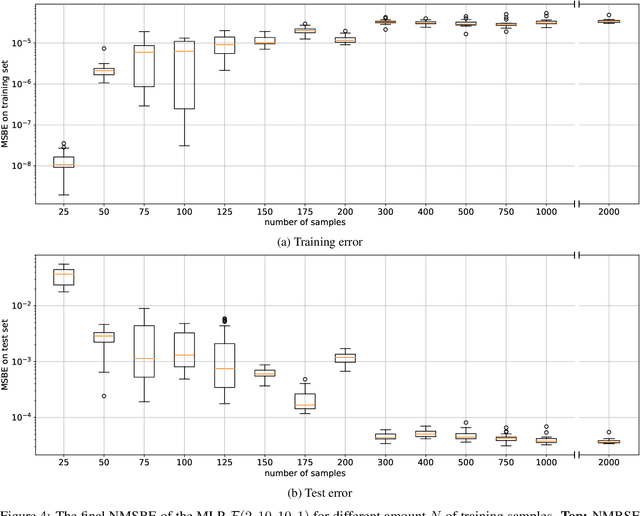
Recent development of Deep Reinforcement Learning has demonstrated superior performance of neural networks in solving challenging problems with large or even continuous state spaces. One specific approach is to deploy neural networks to approximate value functions by minimising the Mean Squared Bellman Error function. Despite great successes of Deep Reinforcement Learning, development of reliable and efficient numerical algorithms to minimise the Bellman Error is still of great scientific interest and practical demand. Such a challenge is partially due to the underlying optimisation problem being highly non-convex or using incorrect gradient information as done in Semi-Gradient algorithms. In this work, we analyse the Mean Squared Bellman Error from a smooth optimisation perspective combined with a Residual Gradient formulation. Our contribution is two-fold. First, we analyse critical points of the error function and provide technical insights on the optimisation procure and design choices for neural networks. When the existence of global minima is assumed and the objective fulfils certain conditions we can eliminate suboptimal local minima when using over-parametrised neural networks. We can construct an efficient Approximate Newton's algorithm based on our analysis and confirm theoretical properties of this algorithm such as being locally quadratically convergent to a global minimum numerically. Second, we demonstrate feasibility and generalisation capabilities of the proposed algorithm empirically using continuous control problems and provide a numerical verification of our critical point analysis. We outline the short coming of Semi-Gradients. To benefit from an approximate Newton's algorithm complete derivatives of the Mean Squared Bellman error must be considered during training.
Dynamic Texture Recognition via Nuclear Distances on Kernelized Scattering Histogram Spaces
Feb 01, 2021
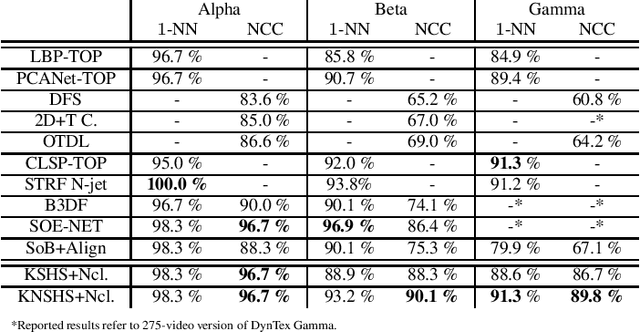
Distance-based dynamic texture recognition is an important research field in multimedia processing with applications ranging from retrieval to segmentation of video data. Based on the conjecture that the most distinctive characteristic of a dynamic texture is the appearance of its individual frames, this work proposes to describe dynamic textures as kernelized spaces of frame-wise feature vectors computed using the Scattering transform. By combining these spaces with a basis-invariant metric, we get a framework that produces competitive results for nearest neighbor classification and state-of-the-art results for nearest class center classification.
* \c{opyright} 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Knowledge as Invariance -- History and Perspectives of Knowledge-augmented Machine Learning
Dec 21, 2020
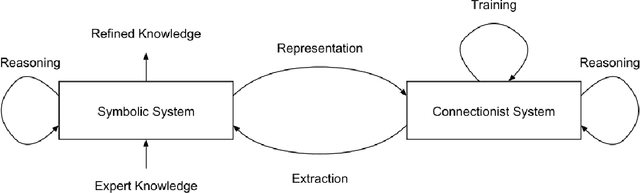
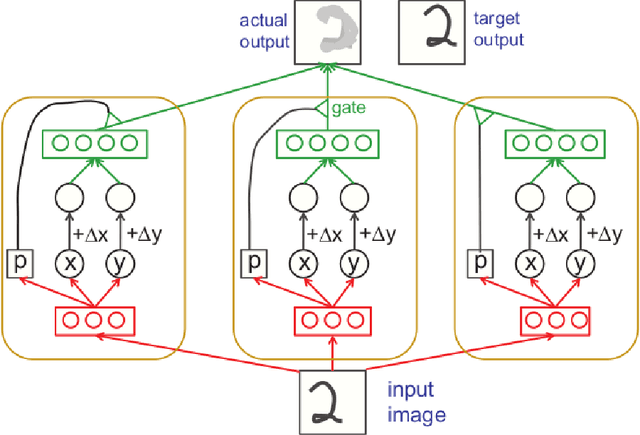
Research in machine learning is at a turning point. While supervised deep learning has conquered the field at a breathtaking pace and demonstrated the ability to solve inference problems with unprecedented accuracy, it still does not quite live up to its name if we think of learning as the process of acquiring knowledge about a subject or problem. Major weaknesses of present-day deep learning models are, for instance, their lack of adaptability to changes of environment or their incapability to perform other kinds of tasks than the one they were trained for. While it is still unclear how to overcome these limitations, one can observe a paradigm shift within the machine learning community, with research interests shifting away from increasing the performance of highly parameterized models to exceedingly specific tasks, and towards employing machine learning algorithms in highly diverse domains. This research question can be approached from different angles. For instance, the field of Informed AI investigates the problem of infusing domain knowledge into a machine learning model, by using techniques such as regularization, data augmentation or post-processing. On the other hand, a remarkable number of works in the recent years has focused on developing models that by themselves guarantee a certain degree of versatility and invariance with respect to the domain or problem at hand. Thus, rather than investigating how to provide domain-specific knowledge to machine learning models, these works explore methods that equip the models with the capability of acquiring the knowledge by themselves. This white paper provides an introduction and discussion of this emerging field in machine learning research. To this end, it reviews the role of knowledge in machine learning, and discusses its relation to the concept of invariance, before providing a literature review of the field.
End-to-End Video Instance Segmentation with Transformers
Dec 04, 2020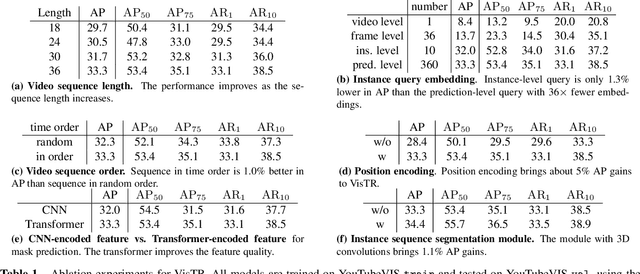
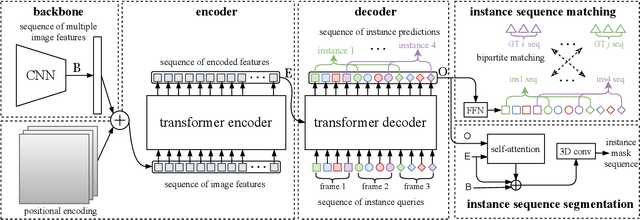
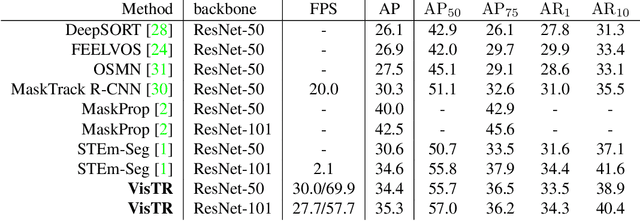

Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.