 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypergraph Optimization for Multi-structural Geometric Model Fitting
Feb 13, 2020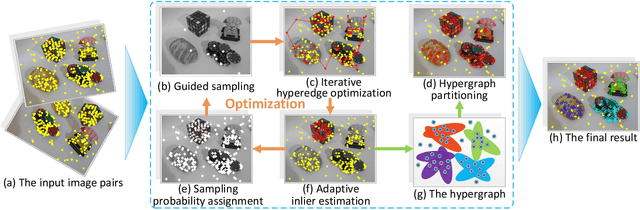
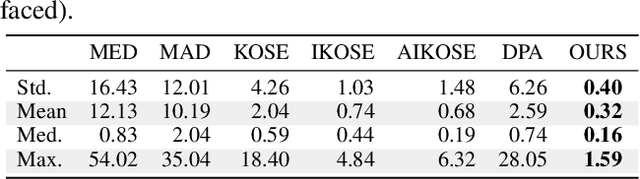
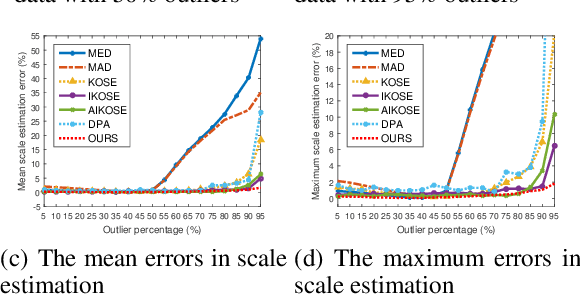
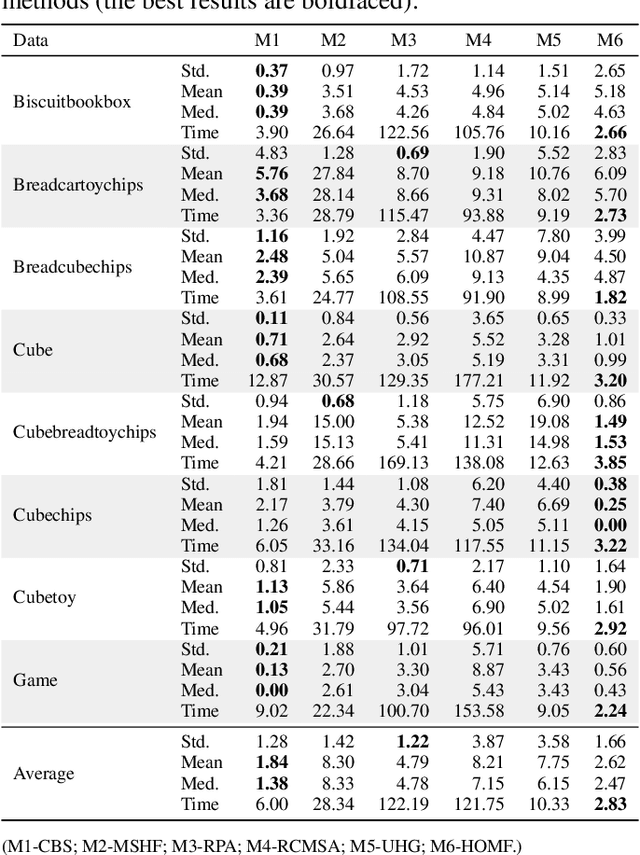
Recently, some hypergraph-based methods have been proposed to deal with the problem of model fitting in computer vision, mainly due to the superior capability of hypergraph to represent the complex relationship between data points. However, a hypergraph becomes extremely complicated when the input data include a large number of data points (usually contaminated with noises and outliers), which will significantly increase the computational burden. In order to overcome the above problem, we propose a novel hypergraph optimization based model fitting (HOMF) method to construct a simple but effective hypergraph. Specifically, HOMF includes two main parts: an adaptive inlier estimation algorithm for vertex optimization and an iterative hyperedge optimization algorithm for hyperedge optimization. The proposed method is highly efficient, and it can obtain accurate model fitting results within a few iterations. Moreover, HOMF can then directly apply spectral clustering, to achieve good fitting performance. Extensive experimental results show that HOMF outperforms several state-of-the-art model fitting methods on both synthetic data and real images, especially in sampling efficiency and in handling data with severe outliers.
Deep Multi-task Multi-label CNN for Effective Facial Attribute Classification
Feb 10, 2020
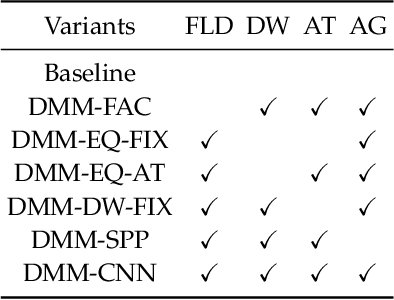
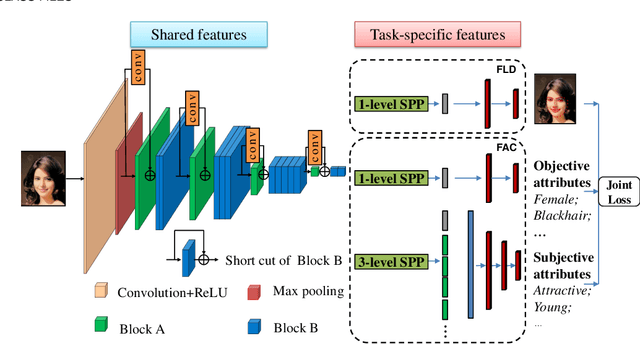
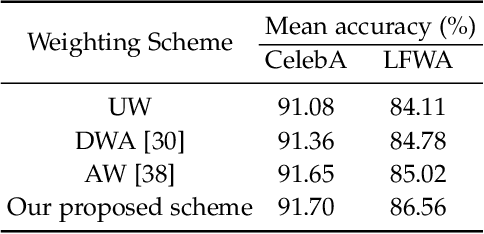
Facial Attribute Classification (FAC) has attracted increasing attention in computer vision and pattern recognition. However, state-of-the-art FAC methods perform face detection/alignment and FAC independently. The inherent dependencies between these tasks are not fully exploited. In addition, most methods predict all facial attributes using the same CNN network architecture, which ignores the different learning complexities of facial attributes. To address the above problems, we propose a novel deep multi-task multi-label CNN, termed DMM-CNN, for effective FAC. Specifically, DMM-CNN jointly optimizes two closely-related tasks (i.e., facial landmark detection and FAC) to improve the performance of FAC by taking advantage of multi-task learning. To deal with the diverse learning complexities of facial attributes, we divide the attributes into two groups: objective attributes and subjective attributes. Two different network architectures are respectively designed to extract features for two groups of attributes, and a novel dynamic weighting scheme is proposed to automatically assign the loss weight to each facial attribute during training. Furthermore, an adaptive thresholding strategy is developed to effectively alleviate the problem of class imbalance for multi-label learning. Experimental results on the challenging CelebA and LFWA datasets show the superiority of the proposed DMM-CNN method compared with several state-of-the-art FAC methods.
Joint Deep Learning of Facial Expression Synthesis and Recognition
Feb 06, 2020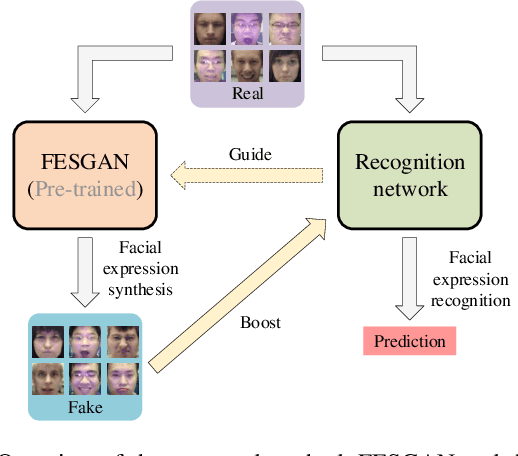
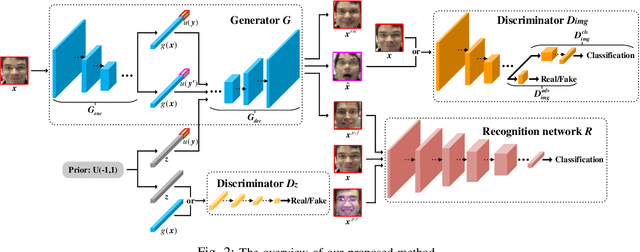
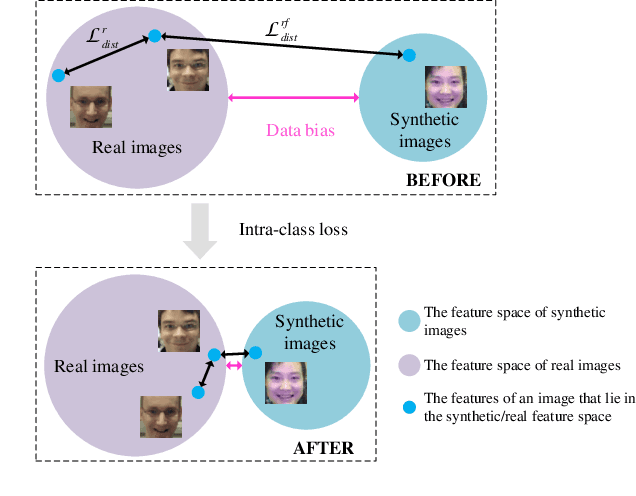

Recently, deep learning based facial expression recognition (FER) methods have attracted considerable attention and they usually require large-scale labelled training data. Nonetheless, the publicly available facial expression databases typically contain a small amount of labelled data. In this paper, to overcome the above issue, we propose a novel joint deep learning of facial expression synthesis and recognition method for effective FER. More specifically, the proposed method involves a two-stage learning procedure. Firstly, a facial expression synthesis generative adversarial network (FESGAN) is pre-trained to generate facial images with different facial expressions. To increase the diversity of the training images, FESGAN is elaborately designed to generate images with new identities from a prior distribution. Secondly, an expression recognition network is jointly learned with the pre-trained FESGAN in a unified framework. In particular, the classification loss computed from the recognition network is used to simultaneously optimize the performance of both the recognition network and the generator of FESGAN. Moreover, in order to alleviate the problem of data bias between the real images and the synthetic images, we propose an intra-class loss with a novel real data-guided back-propagation (RDBP) algorithm to reduce the intra-class variations of images from the same class, which can significantly improve the final performance. Extensive experimental results on public facial expression databases demonstrate the superiority of the proposed method compared with several state-of-the-art FER methods.
Hallucinated Adversarial Learning for Robust Visual Tracking
Jun 17, 2019
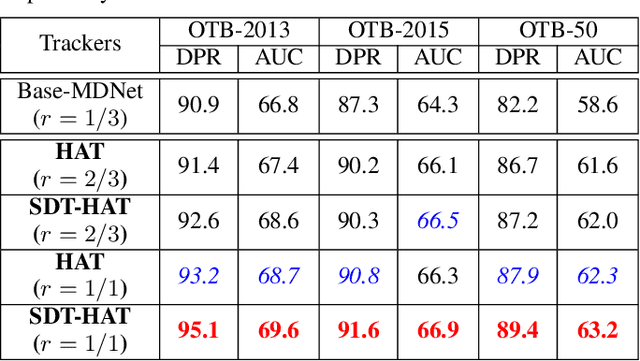
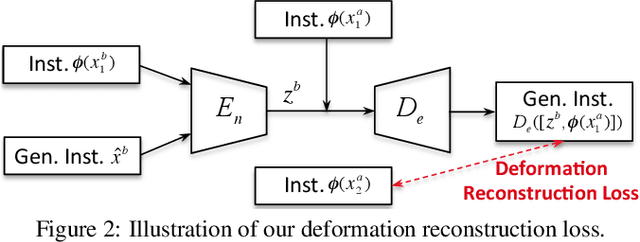
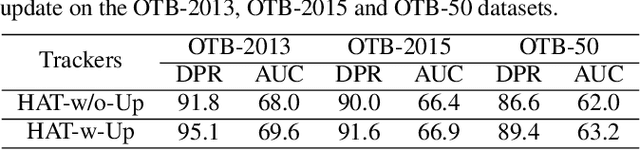
Humans can easily learn new concepts from just a single exemplar, mainly due to their remarkable ability to imagine or hallucinate what the unseen exemplar may look like in different settings. Incorporating such an ability to hallucinate diverse new samples of the tracked instance can help the trackers alleviate the over-fitting problem in the low-data tracking regime. To achieve this, we propose an effective adversarial approach, denoted as adversarial "hallucinator" (AH), for robust visual tracking. The proposed AH is designed to firstly learn transferable non-linear deformations between a pair of same-identity instances, and then apply these deformations to an unseen tracked instance in order to generate diverse positive training samples. By incorporating AH into an online tracking-by-detection framework, we propose the hallucinated adversarial tracker (HAT), which jointly optimizes AH with an online classifier (e.g., MDNet) in an end-to-end manner. In addition, a novel selective deformation transfer (SDT) method is presented to better select the deformations which are more suitable for transfer. Extensive experiments on 3 popular benchmarks demonstrate that our HAT achieves the state-of-the-art performance.
DSNet: Deep and Shallow Feature Learning for Efficient Visual Tracking
Nov 06, 2018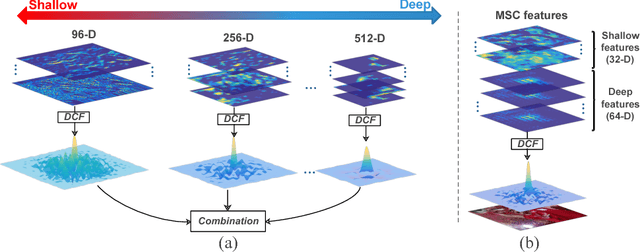
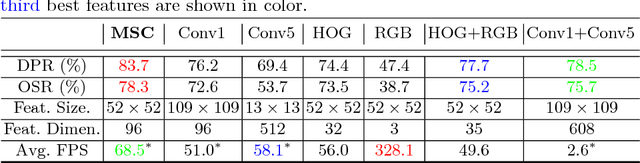
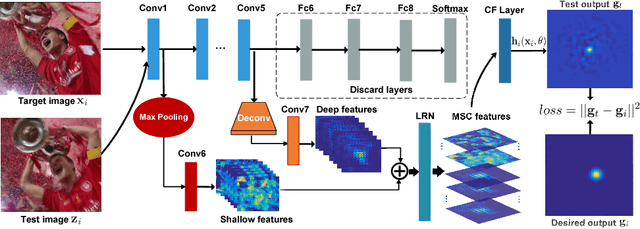
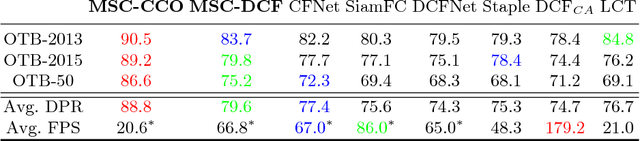
In recent years, Discriminative Correlation Filter (DCF) based tracking methods have achieved great success in visual tracking. However, the multi-resolution convolutional feature maps trained from other tasks like image classification, cannot be naturally used in the conventional DCF formulation. Furthermore, these high-dimensional feature maps significantly increase the tracking complexity and thus limit the tracking speed. In this paper, we present a deep and shallow feature learning network, namely DSNet, to learn the multi-level same-resolution compressed (MSC) features for efficient online tracking, in an end-to-end offline manner. Specifically, the proposed DSNet compresses multi-level convolutional features to uniform spatial resolution features. The learned MSC features effectively encode both appearance and semantic information of objects in the same-resolution feature maps, thus enabling an elegant combination of the MSC features with any DCF-based methods. Additionally, a channel reliability measurement (CRM) method is presented to further refine the learned MSC features. We demonstrate the effectiveness of the MSC features learned from the proposed DSNet on two DCF tracking frameworks: the basic DCF framework and the continuous convolution operator framework. Extensive experiments show that the learned MSC features have the appealing advantage of allowing the equipped DCF-based tracking methods to perform favorably against the state-of-the-art methods while running at high frame rates.
Multi-task Learning of Cascaded CNN for Facial Attribute Classification
May 03, 2018
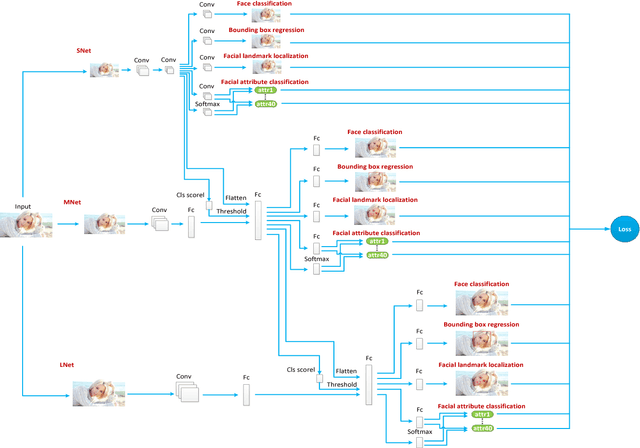
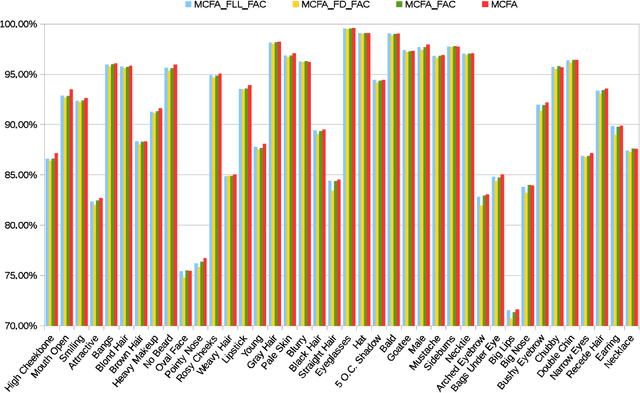

Recently, facial attribute classification (FAC) has attracted significant attention in the computer vision community. Great progress has been made along with the availability of challenging FAC datasets. However, conventional FAC methods usually firstly pre-process the input images (i.e., perform face detection and alignment) and then predict facial attributes. These methods ignore the inherent dependencies among these tasks (i.e., face detection, facial landmark localization and FAC). Moreover, some methods using convolutional neural network are trained based on the fixed loss weights without considering the differences between facial attributes. In order to address the above problems, we propose a novel multi-task learning of cas- caded convolutional neural network method, termed MCFA, for predicting multiple facial attributes simultaneously. Specifically, the proposed method takes advantage of three cascaded sub-networks (i.e., S_Net, M_Net and L_Net corresponding to the neural networks under different scales) to jointly train multiple tasks in a coarse-to-fine manner, which can achieve end-to-end optimization. Furthermore, the proposed method automatically assigns the loss weight to each facial attribute based on a novel dynamic weighting scheme, thus making the proposed method concentrate on predicting the more difficult facial attributes. Experimental results show that the proposed method outperforms several state-of-the-art FAC methods on the challenging CelebA and LFWA datasets.
Multi-label Learning Based Deep Transfer Neural Network for Facial Attribute Classification
May 03, 2018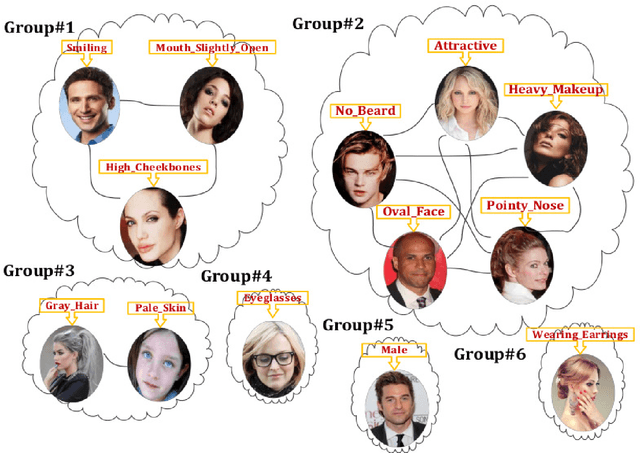
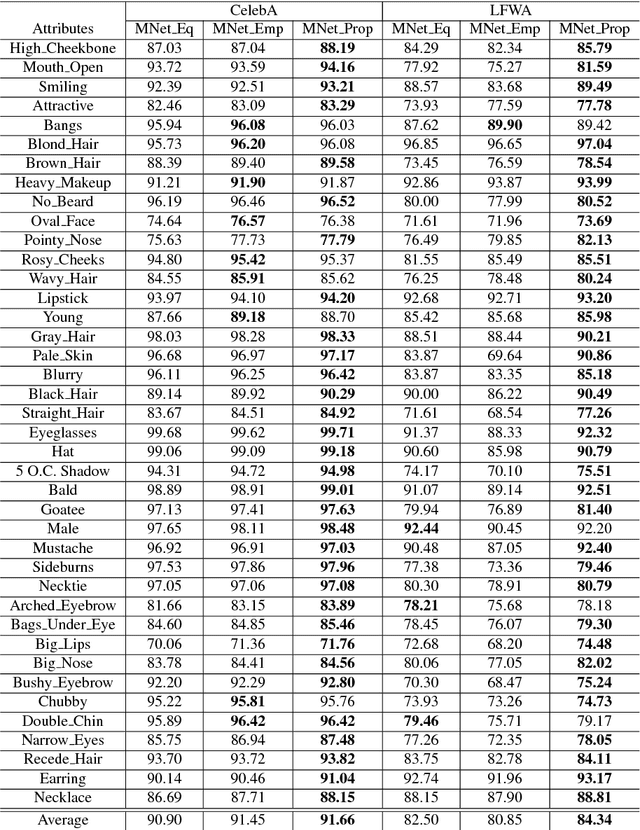
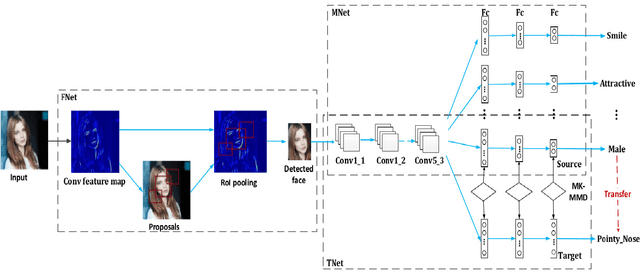
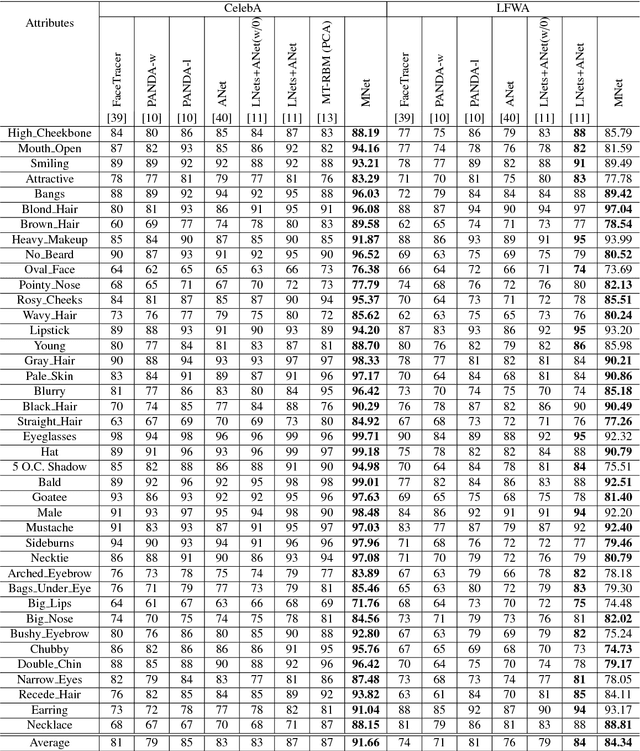
Deep Neural Network (DNN) has recently achieved outstanding performance in a variety of computer vision tasks, including facial attribute classification. The great success of classifying facial attributes with DNN often relies on a massive amount of labelled data. However, in real-world applications, labelled data are only provided for some commonly used attributes (such as age, gender); whereas, unlabelled data are available for other attributes (such as attraction, hairline). To address the above problem, we propose a novel deep transfer neural network method based on multi-label learning for facial attribute classification, termed FMTNet, which consists of three sub-networks: the Face detection Network (FNet), the Multi-label learning Network (MNet) and the Transfer learning Network (TNet). Firstly, based on the Faster Region-based Convolutional Neural Network (Faster R-CNN), FNet is fine-tuned for face detection. Then, MNet is fine-tuned by FNet to predict multiple attributes with labelled data, where an effective loss weight scheme is developed to explicitly exploit the correlation between facial attributes based on attribute grouping. Finally, based on MNet, TNet is trained by taking advantage of unsupervised domain adaptation for unlabelled facial attribute classification. The three sub-networks are tightly coupled to perform effective facial attribute classification. A distinguishing characteristic of the proposed FMTNet method is that the three sub-networks (FNet, MNet and TNet) are constructed in a similar network structure. Extensive experimental results on challenging face datasets demonstrate the effectiveness of our proposed method compared with several state-of-the-art methods.
Superpixel-guided Two-view Deterministic Geometric Model Fitting
May 03, 2018
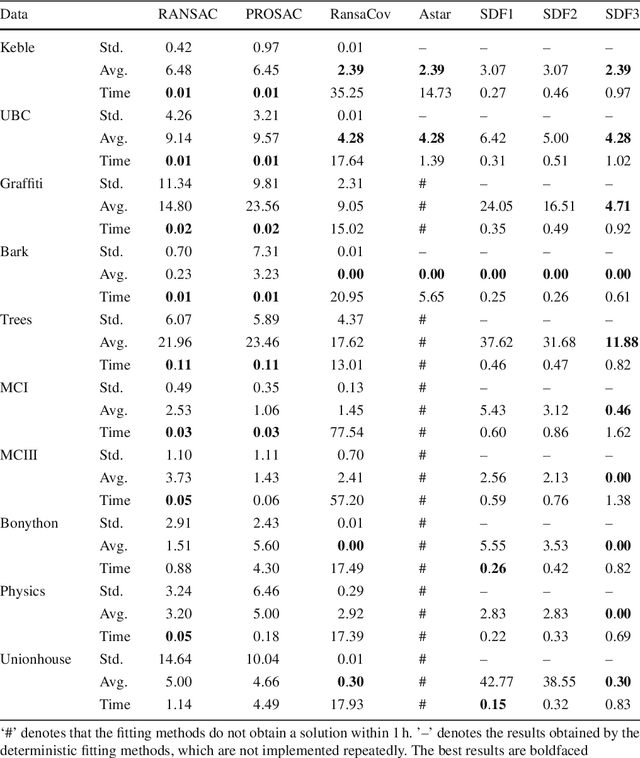
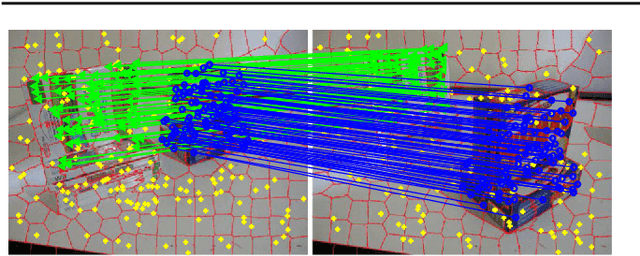
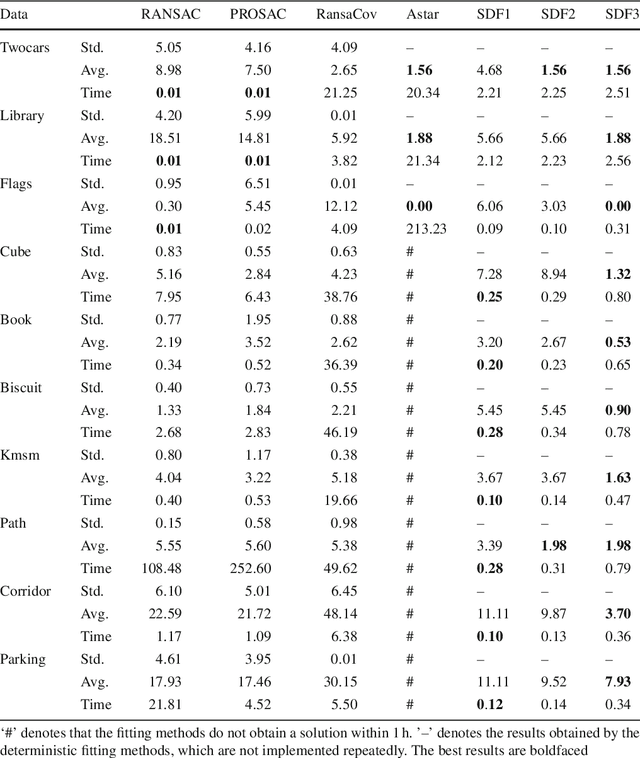
Geometric model fitting is a fundamental research topic in computer vision and it aims to fit and segment multiple-structure data. In this paper, we propose a novel superpixel-guided two-view geometric model fitting method (called SDF), which can obtain reliable and consistent results for real images. Specifically, SDF includes three main parts: a deterministic sampling algorithm, a model hypothesis updating strategy and a novel model selection algorithm. The proposed deterministic sampling algorithm generates a set of initial model hypotheses according to the prior information of superpixels. Then the proposed updating strategy further improves the quality of model hypotheses. After that, by analyzing the properties of the updated model hypotheses, the proposed model selection algorithm extends the conventional "fit-and-remove" framework to estimate model instances in multiple-structure data. The three parts are tightly coupled to boost the performance of SDF in both speed and accuracy, and SDF has the deterministic nature. Experimental results show that the proposed SDF has significant advantages over several state-of-the-art fitting methods when it is applied to real images with single-structure and multiple-structure data.
A Fast Face Detection Method via Convolutional Neural Network
Mar 27, 2018
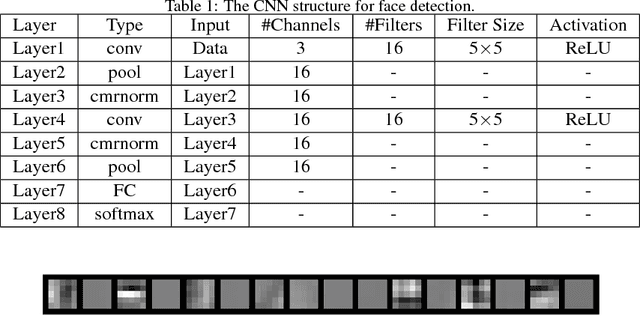
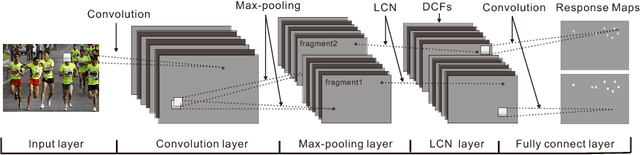
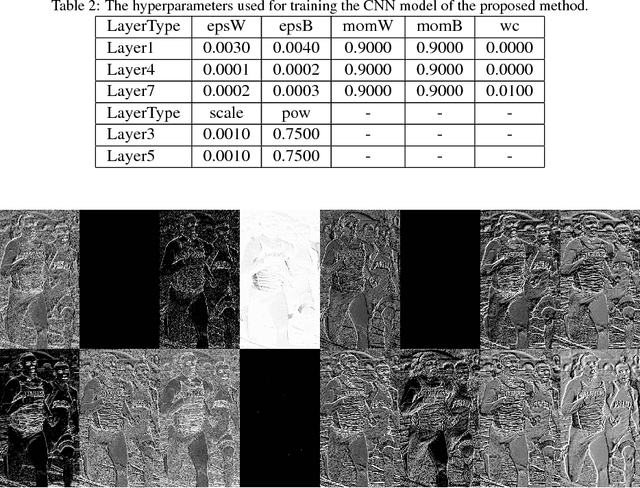
Current face or object detection methods via convolutional neural network (such as OverFeat, R-CNN and DenseNet) explicitly extract multi-scale features based on an image pyramid. However, such a strategy increases the computational burden for face detection. In this paper, we propose a fast face detection method based on discriminative complete features (DCFs) extracted by an elaborately designed convolutional neural network, where face detection is directly performed on the complete feature maps. DCFs have shown the ability of scale invariance, which is beneficial for face detection with high speed and promising performance. Therefore, extracting multi-scale features on an image pyramid employed in the conventional methods is not required in the proposed method, which can greatly improve its efficiency for face detection. Experimental results on several popular face detection datasets show the efficiency and the effectiveness of the proposed method for face detection.
A New Target-specific Object Proposal Generation Method for Visual Tracking
Mar 27, 2018

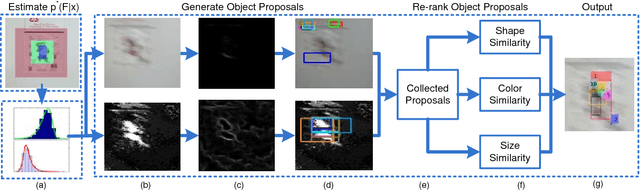

Object proposal generation methods have been widely applied to many computer vision tasks. However, existing object proposal generation methods often suffer from the problems of motion blur, low contrast, deformation, etc., when they are applied to video related tasks. In this paper, we propose an effective and highly accurate target-specific object proposal generation (TOPG) method, which takes full advantage of the context information of a video to alleviate these problems. Specifically, we propose to generate target-specific object proposals by integrating the information of two important objectness cues: colors and edges, which are complementary to each other for different challenging environments in the process of generating object proposals. As a result, the recall of the proposed TOPG method is significantly increased. Furthermore, we propose an object proposal ranking strategy to increase the rank accuracy of the generated object proposals. The proposed TOPG method has yielded significant recall gain (about 20%-60% higher) compared with several state-of-the-art object proposal methods on several challenging visual tracking datasets. Then, we apply the proposed TOPG method to the task of visual tracking and propose a TOPG-based tracker (called as TOPGT), where TOPG is used as a sample selection strategy to select a small number of high-quality target candidates from the generated object proposals. Since the object proposals generated by the proposed TOPG cover many hard negative samples and positive samples, these object proposals can not only be used for training an effective classifier, but also be used as target candidates for visual tracking. Experimental results show the superior performance of TOPGT for visual tracking compared with several other state-of-the-art visual trackers (about 3%-11% higher than the winner of the VOT2015 challenge in term of distance precision).