 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe intriguing role of module criticality in the generalization of deep networks
Dec 04, 2019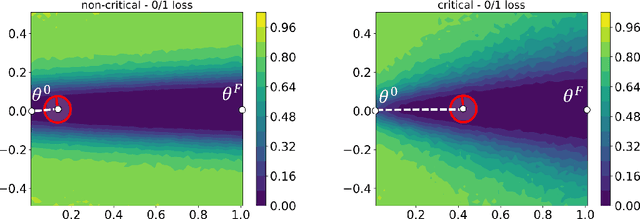
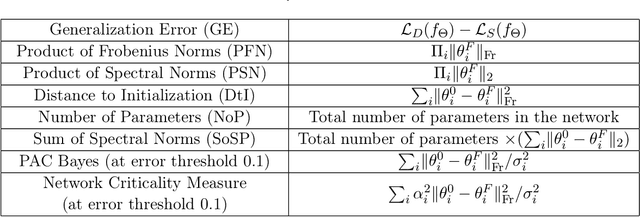
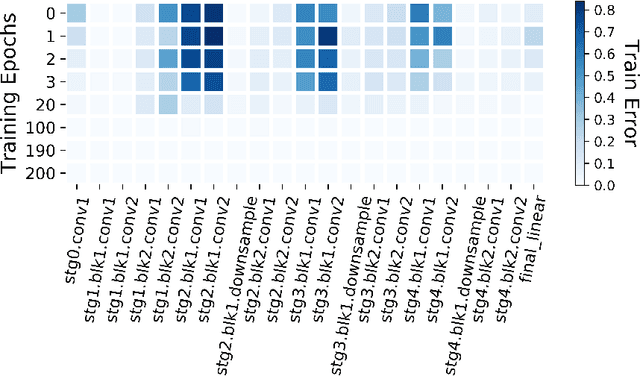
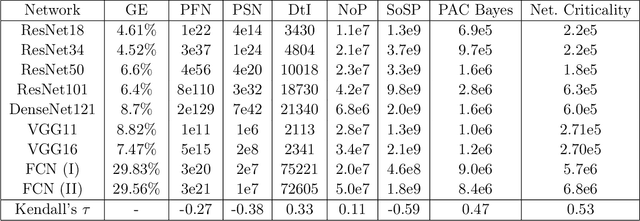
We study the phenomenon that some modules of deep neural networks (DNNs) are more critical than others. Meaning that rewinding their parameter values back to initialization, while keeping other modules fixed at the trained parameters, results in a large drop in the network's performance. Our analysis reveals interesting properties of the loss landscape which leads us to propose a complexity measure, called module criticality, based on the shape of the valleys that connects the initial and final values of the module parameters. We formulate how generalization relates to the module criticality, and show that this measure is able to explain the superior generalization performance of some architectures over others, whereas earlier measures fail to do so.
Size-free generalization bounds for convolutional neural networks
Jun 12, 2019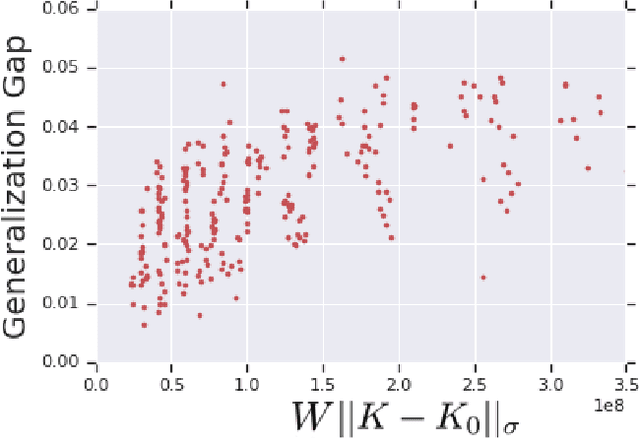
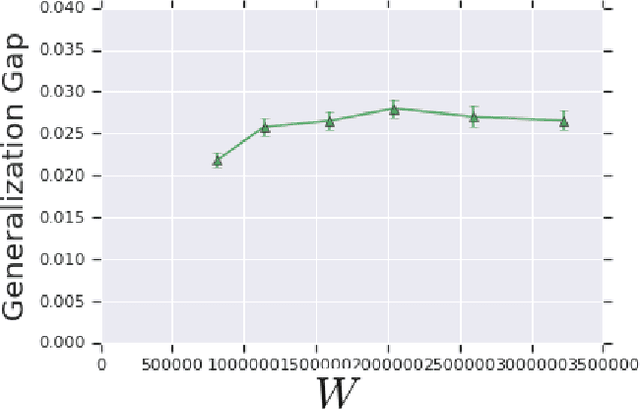
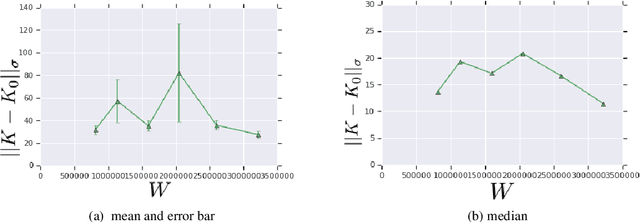
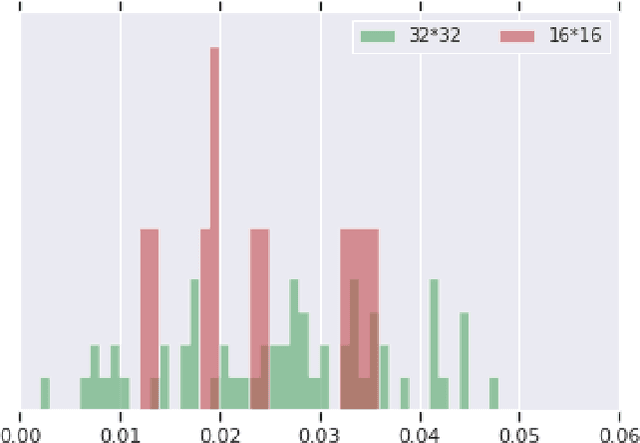
We prove bounds on the generalization error of convolutional networks. The bounds are in terms of the training loss, the number of parameters, the Lipschitz constant of the loss and the distance from the weights to the initial weights. They are independent of the number of pixels in the input, and the height and width of hidden feature maps. We present experiments with CIFAR-10 and a scaled-down variant, along with varying hyperparameters of a deep convolutional network, comparing our bounds with practical generalization gaps.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
On the effect of the activation function on the distribution of hidden nodes in a deep network
Jan 07, 2019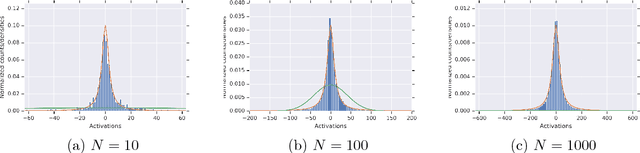
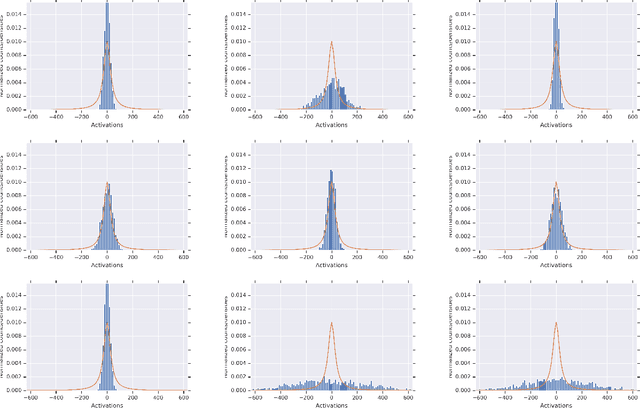
We analyze the joint probability distribution on the lengths of the vectors of hidden variables in different layers of a fully connected deep network, when the weights and biases are chosen randomly according to Gaussian distributions, and the input is in $\{ -1, 1\}^N$. We show that, if the activation function $\phi$ satisfies a minimal set of assumptions, satisfied by all activation functions that we know that are used in practice, then, as the width of the network gets large, the `length process' converges in probability to a length map that is determined as a simple function of the variances of the random weights and biases, and the activation function $\phi$. We also show that this convergence may fail for $\phi$ that violate our assumptions.
The Singular Values of Convolutional Layers
May 26, 2018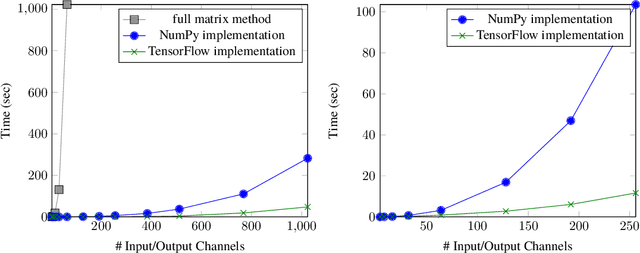
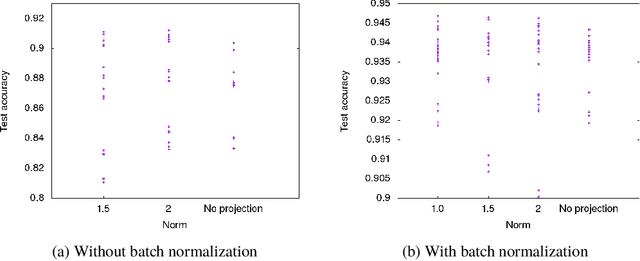
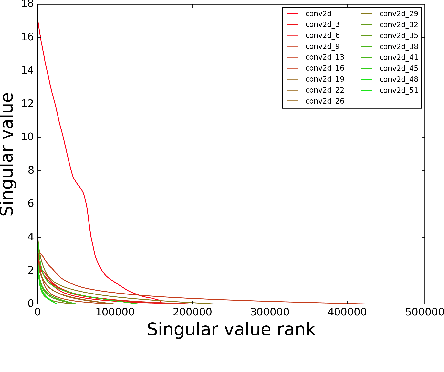
We characterize the singular values of the linear transformation associated with a convolution applied to a two-dimensional feature map with multiple channels. Our characterization enables efficient computation of the singular values of convolutional layers used in popular deep neural network architectures. It also leads to an algorithm for projecting a convolutional layer onto the set of layers obeying a bound on the operator norm of the layer. We show that this is an effective regularizer; periodically applying these projections during training improves the test error of a residual network on CIFAR-10 from 6.2\% to 5.3\%.
Knowledge Completion for Generics using Guided Tensor Factorization
Mar 28, 2018Given a knowledge base or KB containing (noisy) facts about common nouns or generics, such as "all trees produce oxygen" or "some animals live in forests", we consider the problem of inferring additional such facts at a precision similar to that of the starting KB. Such KBs capture general knowledge about the world, and are crucial for various applications such as question answering. Different from commonly studied named entity KBs such as Freebase, generics KBs involve quantification, have more complex underlying regularities, tend to be more incomplete, and violate the commonly used locally closed world assumption (LCWA). We show that existing KB completion methods struggle with this new task, and present the first approach that is successful. Our results demonstrate that external information, such as relation schemas and entity taxonomies, if used appropriately, can be a surprisingly powerful tool in this setting. First, our simple yet effective knowledge guided tensor factorization approach achieves state-of-the-art results on two generics KBs (80% precise) for science, doubling their size at 74%-86% precision. Second, our novel taxonomy guided, submodular, active learning method for collecting annotations about rare entities (e.g., oriole, a bird) is 6x more effective at inferring further new facts about them than multiple active learning baselines.
Training Input-Output Recurrent Neural Networks through Spectral Methods
Oct 31, 2016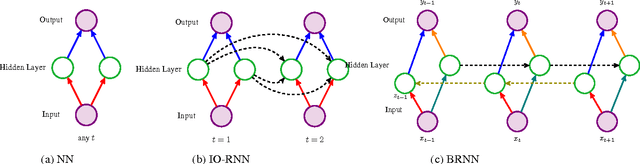
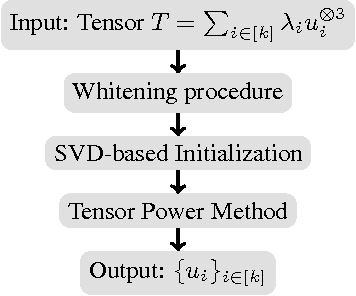
We consider the problem of training input-output recurrent neural networks (RNN) for sequence labeling tasks. We propose a novel spectral approach for learning the network parameters. It is based on decomposition of the cross-moment tensor between the output and a non-linear transformation of the input, based on score functions. We guarantee consistent learning with polynomial sample and computational complexity under transparent conditions such as non-degeneracy of model parameters, polynomial activations for the neurons, and a Markovian evolution of the input sequence. We also extend our results to Bidirectional RNN which uses both previous and future information to output the label at each time point, and is employed in many NLP tasks such as POS tagging.
Provable Tensor Methods for Learning Mixtures of Generalized Linear Models
Jan 13, 2016We consider the problem of learning mixtures of generalized linear models (GLM) which arise in classification and regression problems. Typical learning approaches such as expectation maximization (EM) or variational Bayes can get stuck in spurious local optima. In contrast, we present a tensor decomposition method which is guaranteed to correctly recover the parameters. The key insight is to employ certain feature transformations of the input, which depend on the input generative model. Specifically, we employ score function tensors of the input and compute their cross-correlation with the response variable. We establish that the decomposition of this tensor consistently recovers the parameters, under mild non-degeneracy conditions. We demonstrate that the computational and sample complexity of our method is a low order polynomial of the input and the latent dimensions.
Beating the Perils of Non-Convexity: Guaranteed Training of Neural Networks using Tensor Methods
Jan 12, 2016

Training neural networks is a challenging non-convex optimization problem, and backpropagation or gradient descent can get stuck in spurious local optima. We propose a novel algorithm based on tensor decomposition for guaranteed training of two-layer neural networks. We provide risk bounds for our proposed method, with a polynomial sample complexity in the relevant parameters, such as input dimension and number of neurons. While learning arbitrary target functions is NP-hard, we provide transparent conditions on the function and the input for learnability. Our training method is based on tensor decomposition, which provably converges to the global optimum, under a set of mild non-degeneracy conditions. It consists of simple embarrassingly parallel linear and multi-linear operations, and is competitive with standard stochastic gradient descent (SGD), in terms of computational complexity. Thus, we propose a computationally efficient method with guaranteed risk bounds for training neural networks with one hidden layer.
Multi-Step Stochastic ADMM in High Dimensions: Applications to Sparse Optimization and Noisy Matrix Decomposition
Jul 07, 2015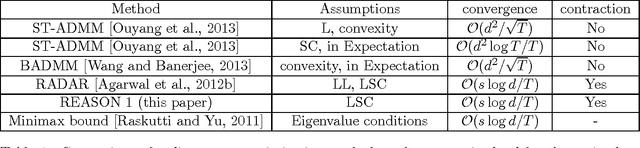
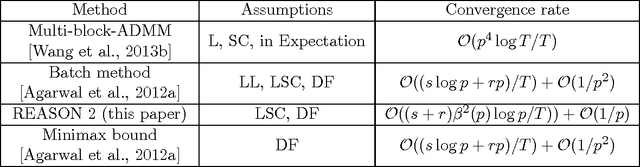
We propose an efficient ADMM method with guarantees for high-dimensional problems. We provide explicit bounds for the sparse optimization problem and the noisy matrix decomposition problem. For sparse optimization, we establish that the modified ADMM method has an optimal convergence rate of $\mathcal{O}(s\log d/T)$, where $s$ is the sparsity level, $d$ is the data dimension and $T$ is the number of steps. This matches with the minimax lower bounds for sparse estimation. For matrix decomposition into sparse and low rank components, we provide the first guarantees for any online method, and prove a convergence rate of $\tilde{\mathcal{O}}((s+r)\beta^2(p) /T) + \mathcal{O}(1/p)$ for a $p\times p$ matrix, where $s$ is the sparsity level, $r$ is the rank and $\Theta(\sqrt{p})\leq \beta(p)\leq \Theta(p)$. Our guarantees match the minimax lower bound with respect to $s,r$ and $T$. In addition, we match the minimax lower bound with respect to the matrix dimension $p$, i.e. $\beta(p)=\Theta(\sqrt{p})$, for many important statistical models including the independent noise model, the linear Bayesian network and the latent Gaussian graphical model under some conditions. Our ADMM method is based on epoch-based annealing and consists of inexpensive steps which involve projections on to simple norm balls. Experiments show that for both sparse optimization and matrix decomposition problems, our algorithm outperforms the state-of-the-art methods. In particular, we reach higher accuracy with same time complexity.