 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Shot Learning with Imprinted Weights
Apr 06, 2018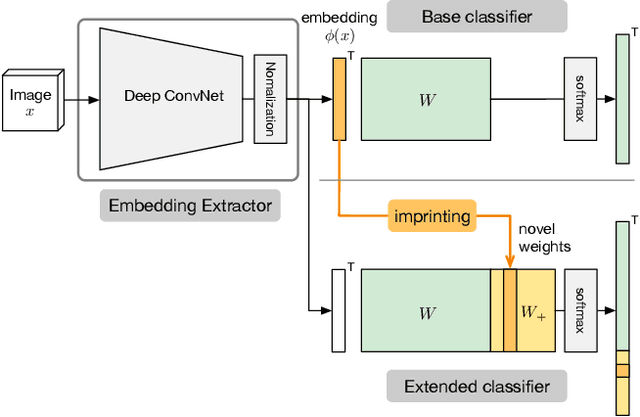
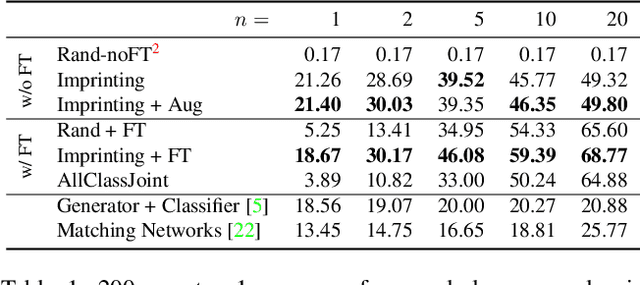
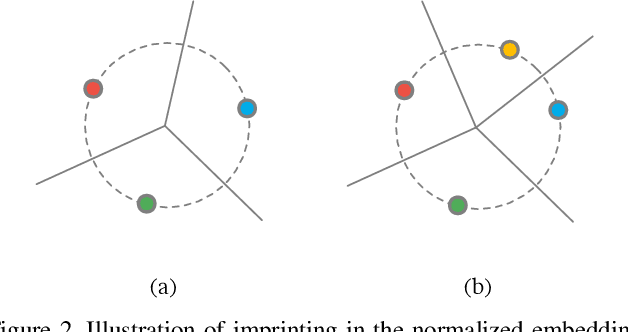
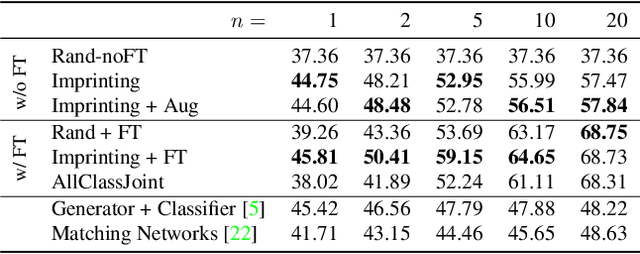
Human vision is able to immediately recognize novel visual categories after seeing just one or a few training examples. We describe how to add a similar capability to ConvNet classifiers by directly setting the final layer weights from novel training examples during low-shot learning. We call this process weight imprinting as it directly sets weights for a new category based on an appropriately scaled copy of the embedding layer activations for that training example. The imprinting process provides a valuable complement to training with stochastic gradient descent, as it provides immediate good classification performance and an initialization for any further fine-tuning in the future. We show how this imprinting process is related to proxy-based embeddings. However, it differs in that only a single imprinted weight vector is learned for each novel category, rather than relying on a nearest-neighbor distance to training instances as typically used with embedding methods. Our experiments show that using averaging of imprinted weights provides better generalization than using nearest-neighbor instance embeddings.
Scene-centric Joint Parsing of Cross-view Videos
Feb 05, 2018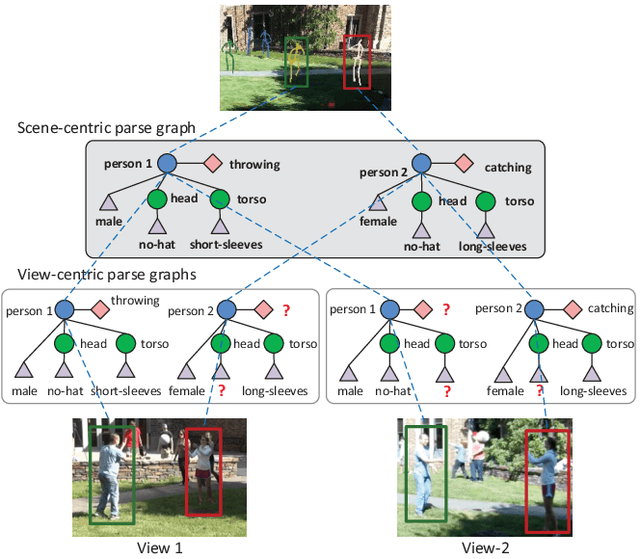
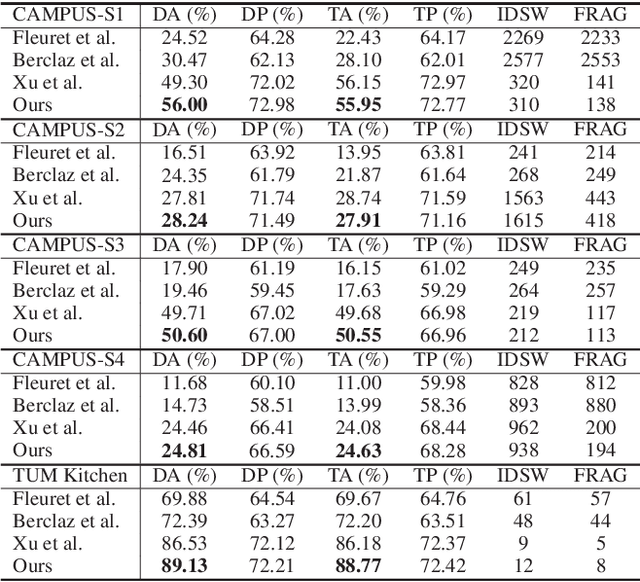
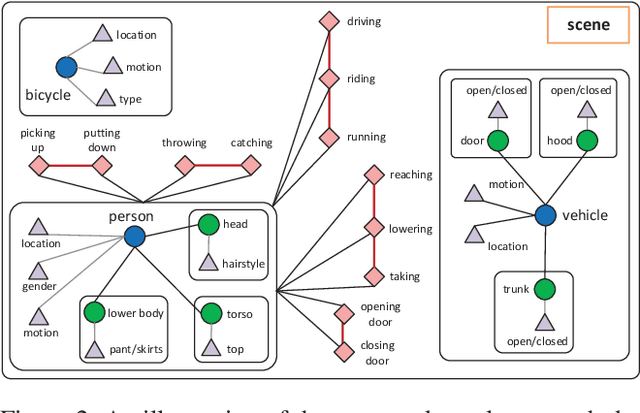

Cross-view video understanding is an important yet under-explored area in computer vision. In this paper, we introduce a joint parsing framework that integrates view-centric proposals into scene-centric parse graphs that represent a coherent scene-centric understanding of cross-view scenes. Our key observations are that overlapping fields of views embed rich appearance and geometry correlations and that knowledge fragments corresponding to individual vision tasks are governed by consistency constraints available in commonsense knowledge. The proposed joint parsing framework represents such correlations and constraints explicitly and generates semantic scene-centric parse graphs. Quantitative experiments show that scene-centric predictions in the parse graph outperform view-centric predictions.
Lift-Based Bidding in Ad Selection
Feb 13, 2016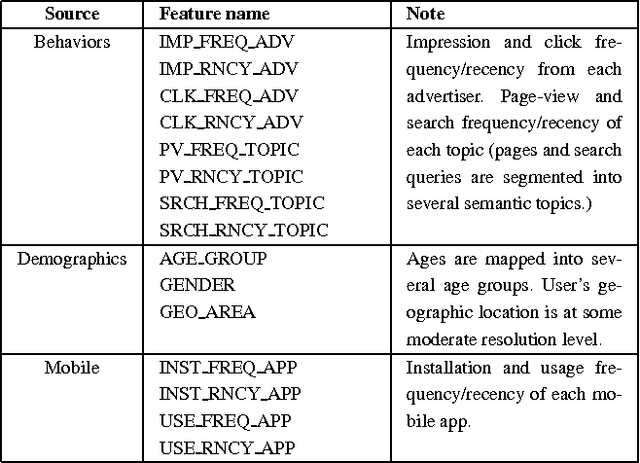
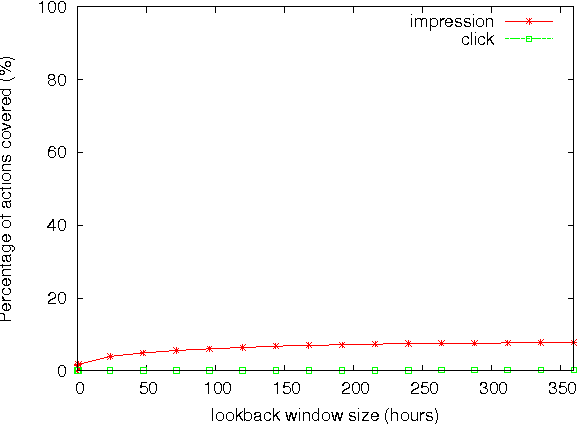
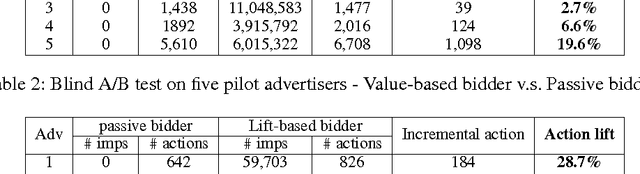
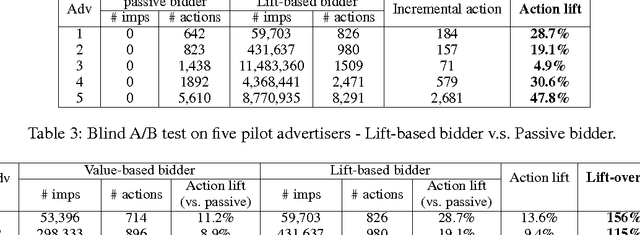
Real-time bidding (RTB) has become one of the largest online advertising markets in the world. Today the bid price per ad impression is typically decided by the expected value of how it can lead to a desired action event (e.g., registering an account or placing a purchase order) to the advertiser. However, this industry standard approach to decide the bid price does not consider the actual effect of the ad shown to the user, which should be measured based on the performance lift among users who have been or have not been exposed to a certain treatment of ads. In this paper, we propose a new bidding strategy and prove that if the bid price is decided based on the performance lift rather than absolute performance value, advertisers can actually gain more action events. We describe the modeling methodology to predict the performance lift and demonstrate the actual performance gain through blind A/B test with real ad campaigns in an industry-leading Demand-Side Platform (DSP). We also discuss the relationship between attribution models and bidding strategies. We prove that, to move the DSPs to bid based on performance lift, they should be rewarded according to the relative performance lift they contribute.
A Restricted Visual Turing Test for Deep Scene and Event Understanding
Dec 16, 2015
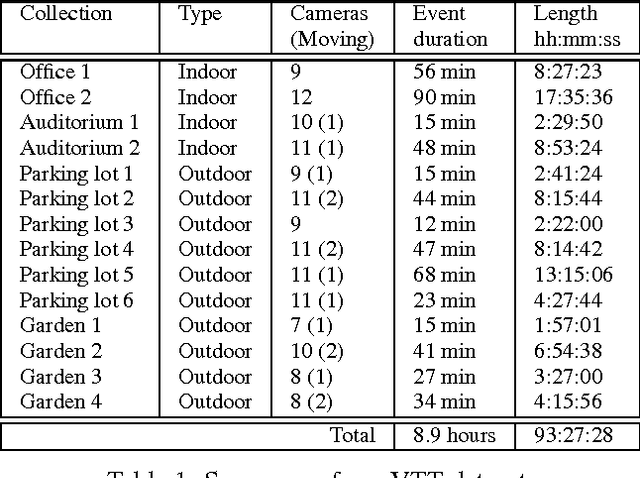
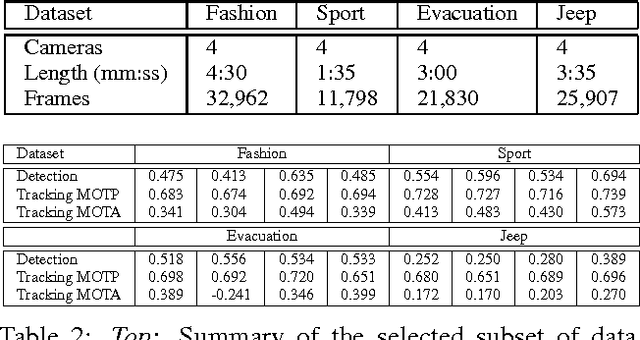
This paper presents a restricted visual Turing test (VTT) for story-line based deep understanding in long-term and multi-camera captured videos. Given a set of videos of a scene (such as a multi-room office, a garden, and a parking lot.) and a sequence of story-line based queries, the task is to provide answers either simply in binary form "true/false" (to a polar query) or in an accurate natural language description (to a non-polar query). Queries, polar or non-polar, consist of view-based queries which can be answered from a particular camera view and scene-centered queries which involves joint inference across different cameras. The story lines are collected to cover spatial, temporal and causal understanding of input videos. The data and queries distinguish our VTT from recently proposed visual question answering in images and video captioning. A vision system is proposed to perform joint video and query parsing which integrates different vision modules, a knowledge base and a query engine. The system provides unified interfaces for different modules so that individual modules can be reconfigured to test a new method. We provide a benchmark dataset and a toolkit for ontology guided story-line query generation which consists of about 93.5 hours videos captured in four different locations and 3,426 queries split into 127 story lines. We also provide a baseline implementation and result analyses.
Joint Image-Text News Topic Detection and Tracking with And-Or Graph Representation
Dec 15, 2015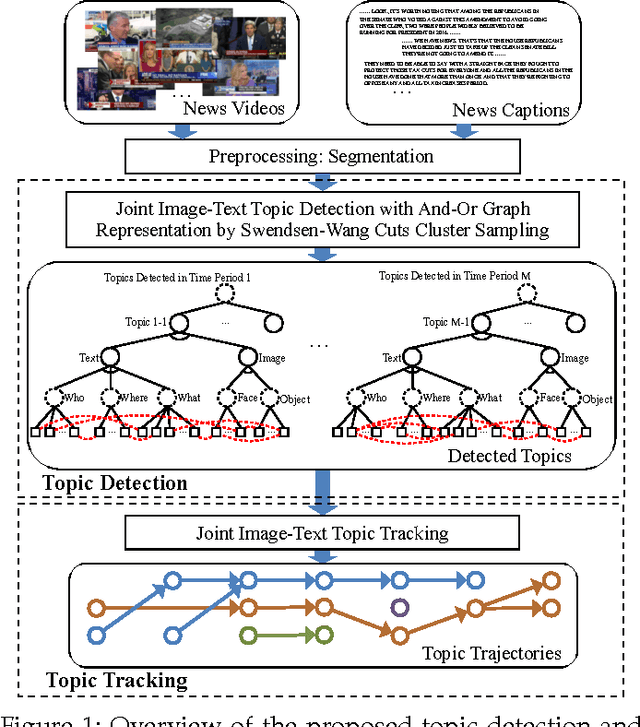
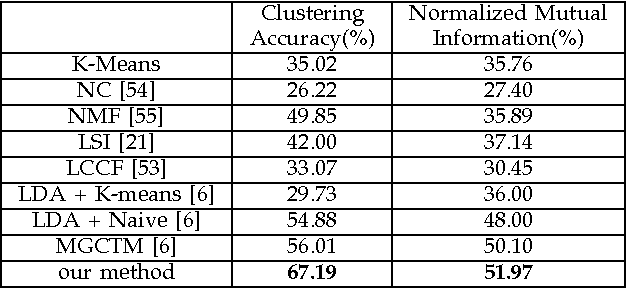
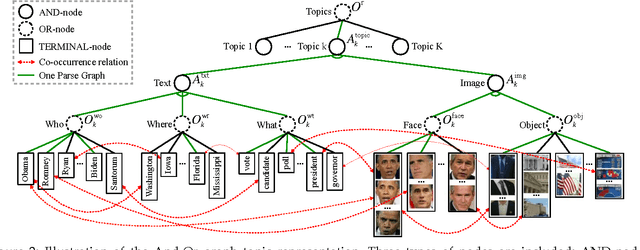
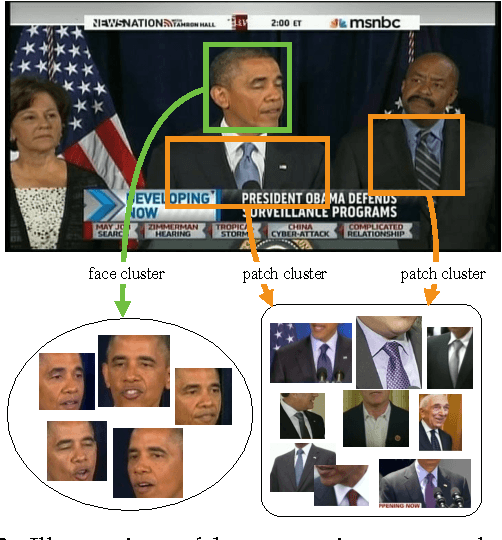
In this paper, we aim to develop a method for automatically detecting and tracking topics in broadcast news. We present a hierarchical And-Or graph (AOG) to jointly represent the latent structure of both texts and visuals. The AOG embeds a context sensitive grammar that can describe the hierarchical composition of news topics by semantic elements about people involved, related places and what happened, and model contextual relationships between elements in the hierarchy. We detect news topics through a cluster sampling process which groups stories about closely related events. Swendsen-Wang Cuts (SWC), an effective cluster sampling algorithm, is adopted for traversing the solution space and obtaining optimal clustering solutions by maximizing a Bayesian posterior probability. Topics are tracked to deal with the continuously updated news streams. We generate topic trajectories to show how topics emerge, evolve and disappear over time. The experimental results show that our method can explicitly describe the textual and visual data in news videos and produce meaningful topic trajectories. Our method achieves superior performance compared to state-of-the-art methods on both a public dataset Reuters-21578 and a self-collected dataset named UCLA Broadcast News Dataset.
Smart Pacing for Effective Online Ad Campaign Optimization
Jun 18, 2015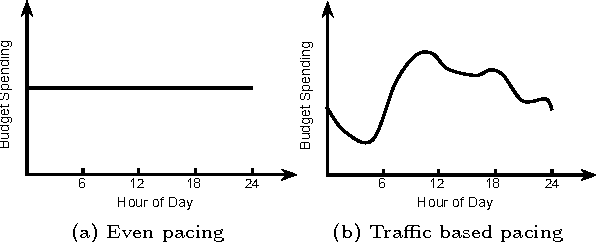

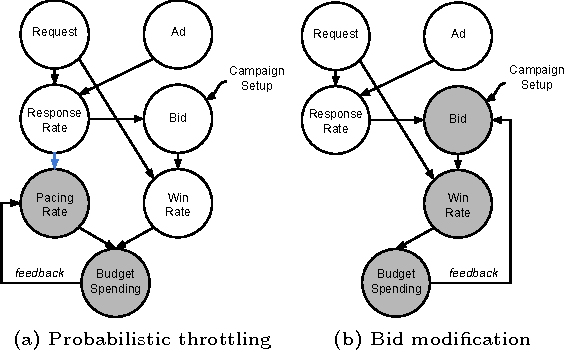
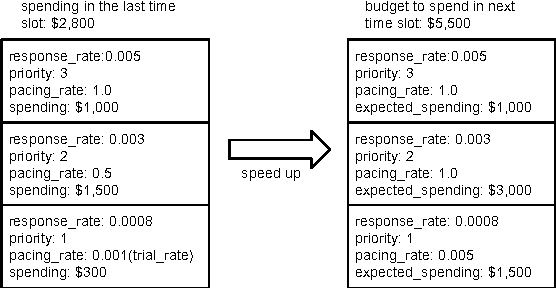
In targeted online advertising, advertisers look for maximizing campaign performance under delivery constraint within budget schedule. Most of the advertisers typically prefer to impose the delivery constraint to spend budget smoothly over the time in order to reach a wider range of audiences and have a sustainable impact. Since lots of impressions are traded through public auctions for online advertising today, the liquidity makes price elasticity and bid landscape between demand and supply change quite dynamically. Therefore, it is challenging to perform smooth pacing control and maximize campaign performance simultaneously. In this paper, we propose a smart pacing approach in which the delivery pace of each campaign is learned from both offline and online data to achieve smooth delivery and optimal performance goals. The implementation of the proposed approach in a real DSP system is also presented. Experimental evaluations on both real online ad campaigns and offline simulations show that our approach can effectively improve campaign performance and achieve delivery goals.