 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hiding Adversarial Examples from Network Interpretation
Dec 06, 2018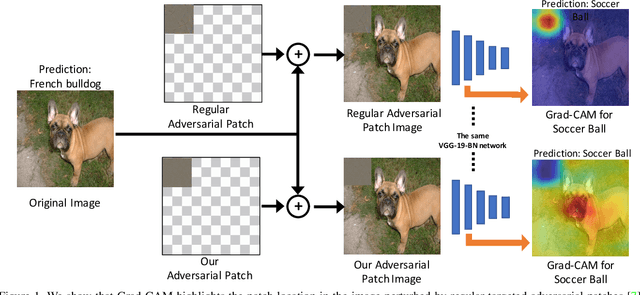

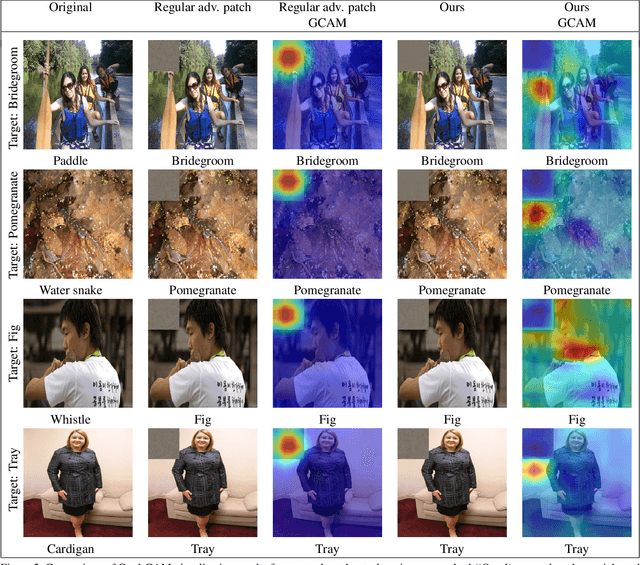
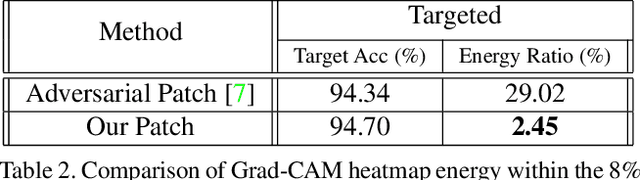
Deep networks have been shown to be fooled rather easily using adversarial attack algorithms. Practical methods such as adversarial patches have been shown to be extremely effective in causing misclassification. However, these patches can be highlighted using standard network interpretation algorithms, thus revealing the identity of the adversary. We show that it is possible to create adversarial patches which not only fool the prediction, but also change what we interpret regarding the cause of prediction. We show that our algorithms can empower adversarial patches, by hiding them from network interpretation tools. We believe our algorithms can facilitate developing more robust network interpretation tools that truly explain the network's underlying decision making process.
Boosting Self-Supervised Learning via Knowledge Transfer
May 01, 2018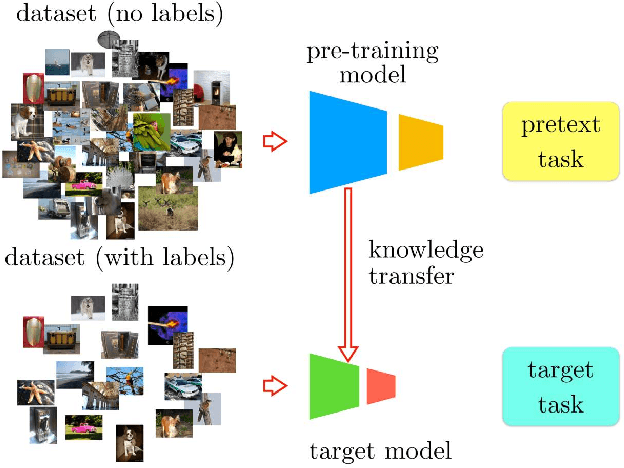

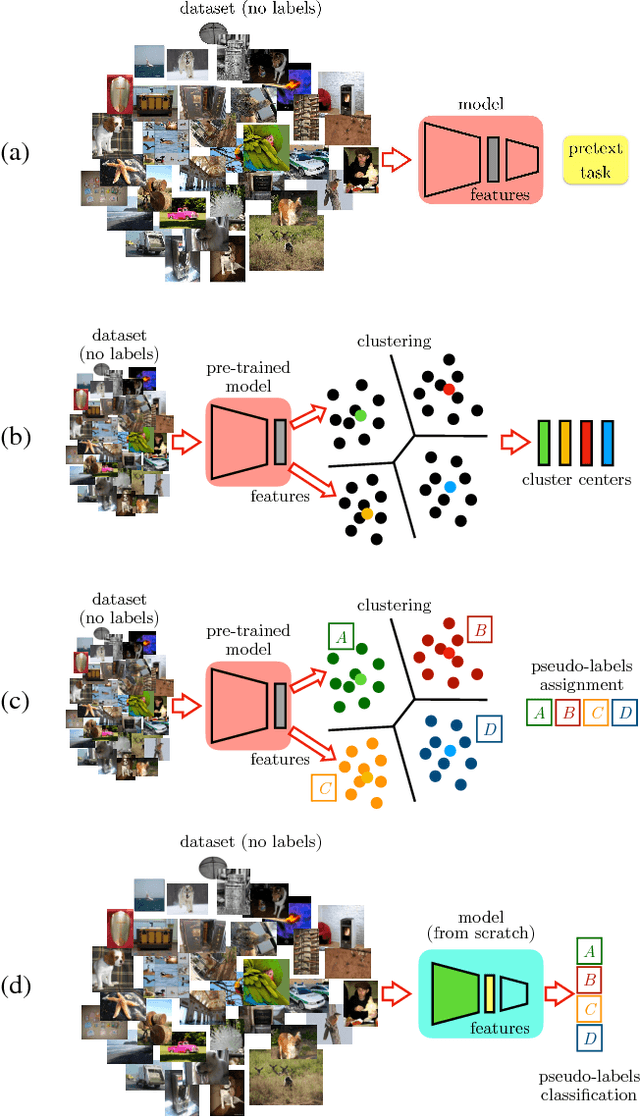

In self-supervised learning, one trains a model to solve a so-called pretext task on a dataset without the need for human annotation. The main objective, however, is to transfer this model to a target domain and task. Currently, the most effective transfer strategy is fine-tuning, which restricts one to use the same model or parts thereof for both pretext and target tasks. In this paper, we present a novel framework for self-supervised learning that overcomes limitations in designing and comparing different tasks, models, and data domains. In particular, our framework decouples the structure of the self-supervised model from the final task-specific fine-tuned model. This allows us to: 1) quantitatively assess previously incompatible models including handcrafted features; 2) show that deeper neural network models can learn better representations from the same pretext task; 3) transfer knowledge learned with a deep model to a shallower one and thus boost its learning. We use this framework to design a novel self-supervised task, which achieves state-of-the-art performance on the common benchmarks in PASCAL VOC 2007, ILSVRC12 and Places by a significant margin. Our learned features shrink the mAP gap between models trained via self-supervised learning and supervised learning from 5.9% to 2.6% in object detection on PASCAL VOC 2007.
Representation Learning by Learning to Count
Aug 22, 2017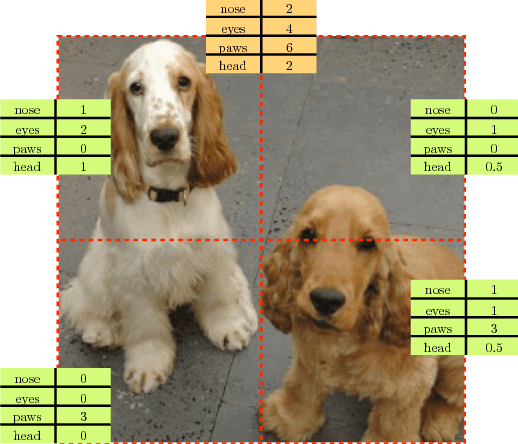
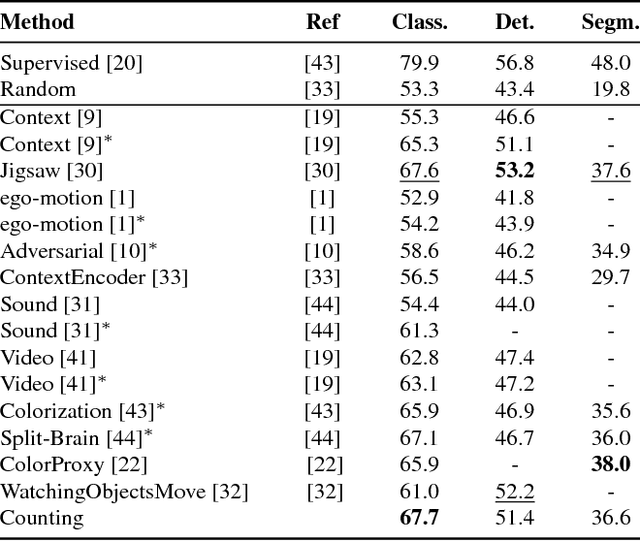
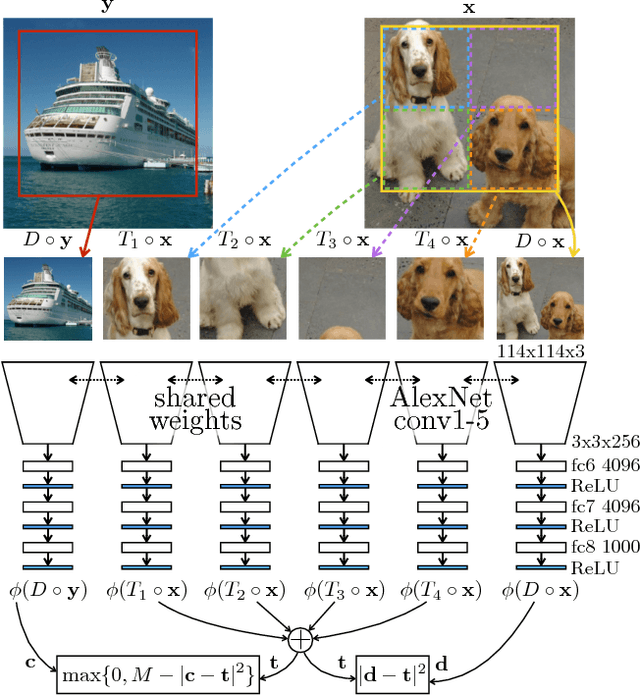
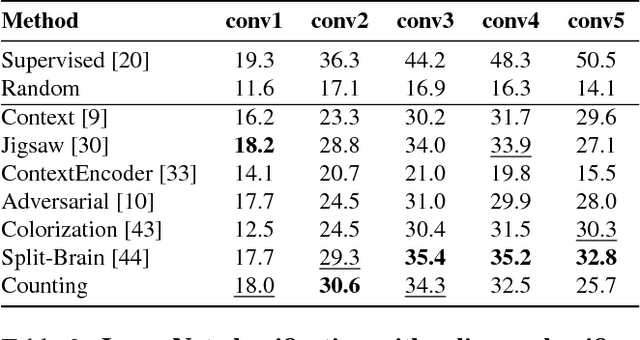
We introduce a novel method for representation learning that uses an artificial supervision signal based on counting visual primitives. This supervision signal is obtained from an equivariance relation, which does not require any manual annotation. We relate transformations of images to transformations of the representations. More specifically, we look for the representation that satisfies such relation rather than the transformations that match a given representation. In this paper, we use two image transformations in the context of counting: scaling and tiling. The first transformation exploits the fact that the number of visual primitives should be invariant to scale. The second transformation allows us to equate the total number of visual primitives in each tile to that in the whole image. These two transformations are combined in one constraint and used to train a neural network with a contrastive loss. The proposed task produces representations that perform on par or exceed the state of the art in transfer learning benchmarks.
Predicting Motivations of Actions by Leveraging Text
Nov 30, 2016


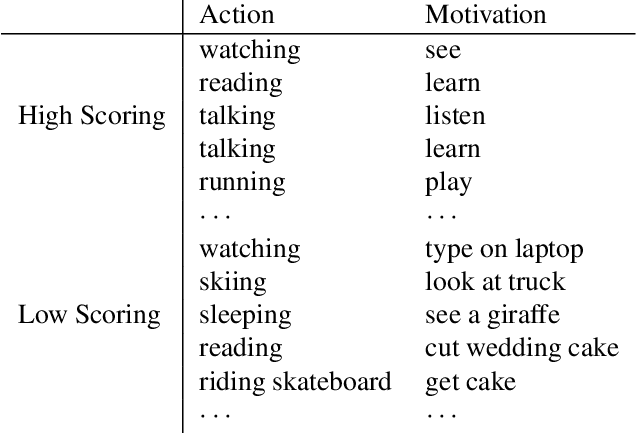
Understanding human actions is a key problem in computer vision. However, recognizing actions is only the first step of understanding what a person is doing. In this paper, we introduce the problem of predicting why a person has performed an action in images. This problem has many applications in human activity understanding, such as anticipating or explaining an action. To study this problem, we introduce a new dataset of people performing actions annotated with likely motivations. However, the information in an image alone may not be sufficient to automatically solve this task. Since humans can rely on their lifetime of experiences to infer motivation, we propose to give computer vision systems access to some of these experiences by using recently developed natural language models to mine knowledge stored in massive amounts of text. While we are still far away from fully understanding motivation, our results suggest that transferring knowledge from language into vision can help machines understand why people in images might be performing an action.
Anticipating Visual Representations from Unlabeled Video
Nov 30, 2016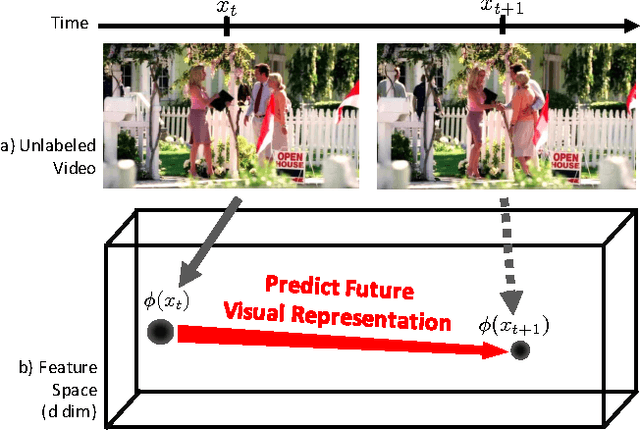
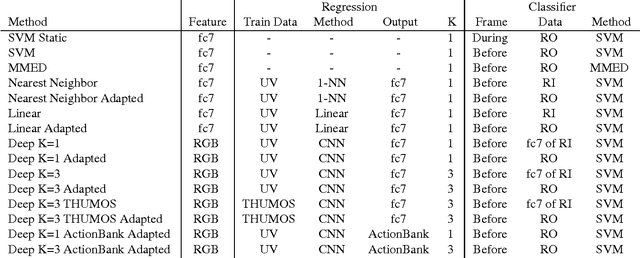
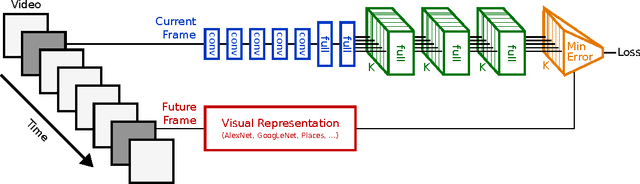
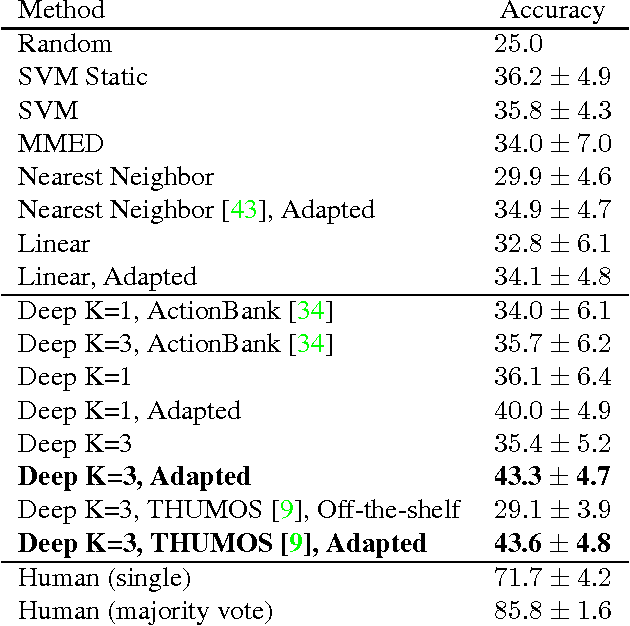
Anticipating actions and objects before they start or appear is a difficult problem in computer vision with several real-world applications. This task is challenging partly because it requires leveraging extensive knowledge of the world that is difficult to write down. We believe that a promising resource for efficiently learning this knowledge is through readily available unlabeled video. We present a framework that capitalizes on temporal structure in unlabeled video to learn to anticipate human actions and objects. The key idea behind our approach is that we can train deep networks to predict the visual representation of images in the future. Visual representations are a promising prediction target because they encode images at a higher semantic level than pixels yet are automatic to compute. We then apply recognition algorithms on our predicted representation to anticipate objects and actions. We experimentally validate this idea on two datasets, anticipating actions one second in the future and objects five seconds in the future.
Weakly Supervised Cascaded Convolutional Networks
Nov 24, 2016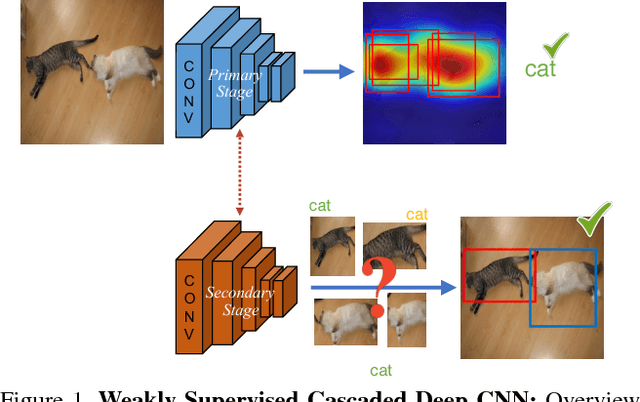
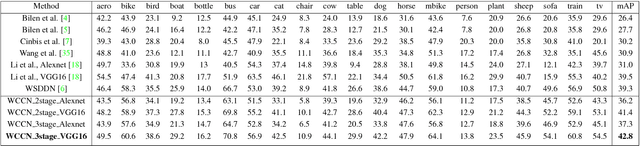
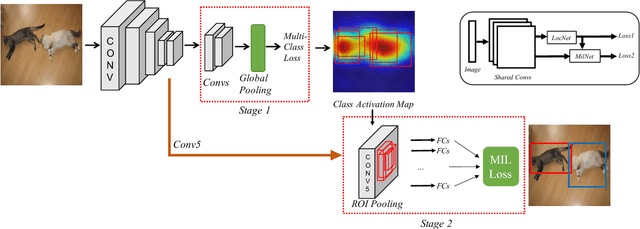
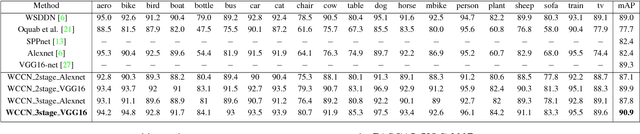
Object detection is a challenging task in visual understanding domain, and even more so if the supervision is to be weak. Recently, few efforts to handle the task without expensive human annotations is established by promising deep neural network. A new architecture of cascaded networks is proposed to learn a convolutional neural network (CNN) under such conditions. We introduce two such architectures, with either two cascade stages or three which are trained in an end-to-end pipeline. The first stage of both architectures extracts best candidate of class specific region proposals by training a fully convolutional network. In the case of the three stage architecture, the middle stage provides object segmentation, using the output of the activation maps of first stage. The final stage of both architectures is a part of a convolutional neural network that performs multiple instance learning on proposals extracted in the previous stage(s). Our experiments on the PASCAL VOC 2007, 2010, 2012 and large scale object datasets, ILSVRC 2013, 2014 datasets show improvements in the areas of weakly-supervised object detection, classification and localization.
Cross-Modal Scene Networks
Oct 27, 2016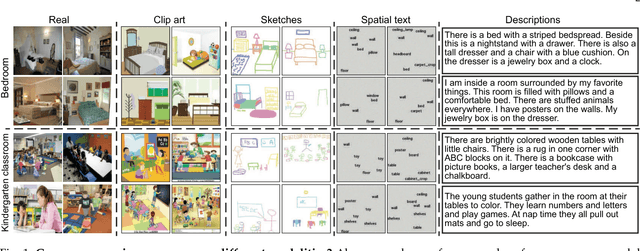
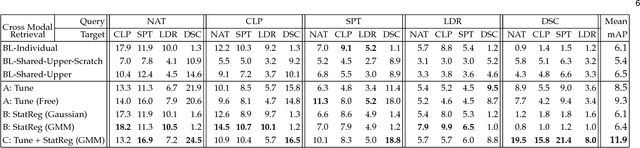
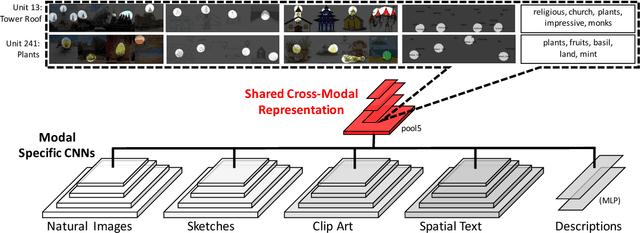
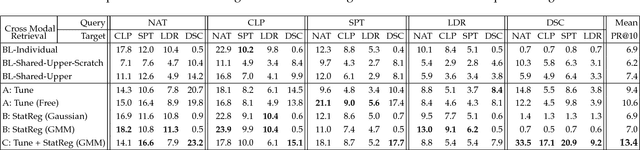
People can recognize scenes across many different modalities beyond natural images. In this paper, we investigate how to learn cross-modal scene representations that transfer across modalities. To study this problem, we introduce a new cross-modal scene dataset. While convolutional neural networks can categorize scenes well, they also learn an intermediate representation not aligned across modalities, which is undesirable for cross-modal transfer applications. We present methods to regularize cross-modal convolutional neural networks so that they have a shared representation that is agnostic of the modality. Our experiments suggest that our scene representation can help transfer representations across modalities for retrieval. Moreover, our visualizations suggest that units emerge in the shared representation that tend to activate on consistent concepts independently of the modality.
Generating Videos with Scene Dynamics
Oct 26, 2016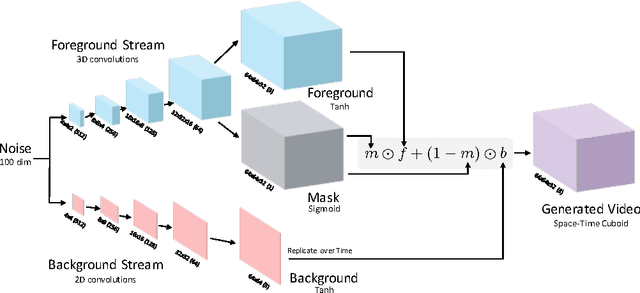
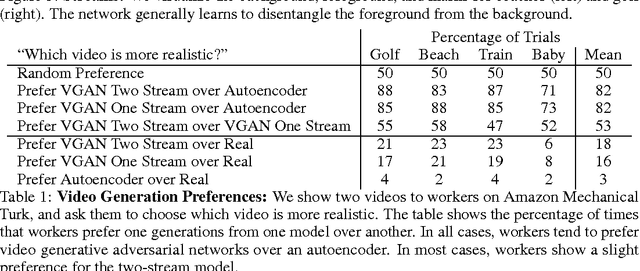


We capitalize on large amounts of unlabeled video in order to learn a model of scene dynamics for both video recognition tasks (e.g. action classification) and video generation tasks (e.g. future prediction). We propose a generative adversarial network for video with a spatio-temporal convolutional architecture that untangles the scene's foreground from the background. Experiments suggest this model can generate tiny videos up to a second at full frame rate better than simple baselines, and we show its utility at predicting plausible futures of static images. Moreover, experiments and visualizations show the model internally learns useful features for recognizing actions with minimal supervision, suggesting scene dynamics are a promising signal for representation learning. We believe generative video models can impact many applications in video understanding and simulation.
Joint Semantic Segmentation and Depth Estimation with Deep Convolutional Networks
Sep 19, 2016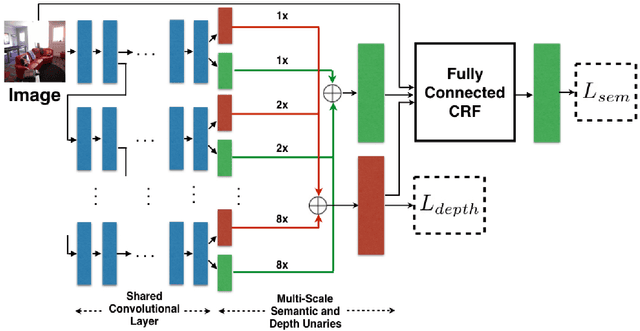
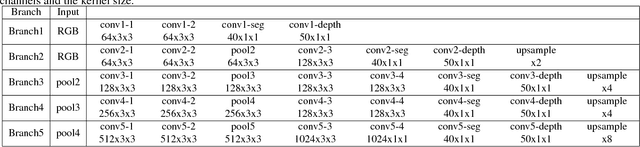

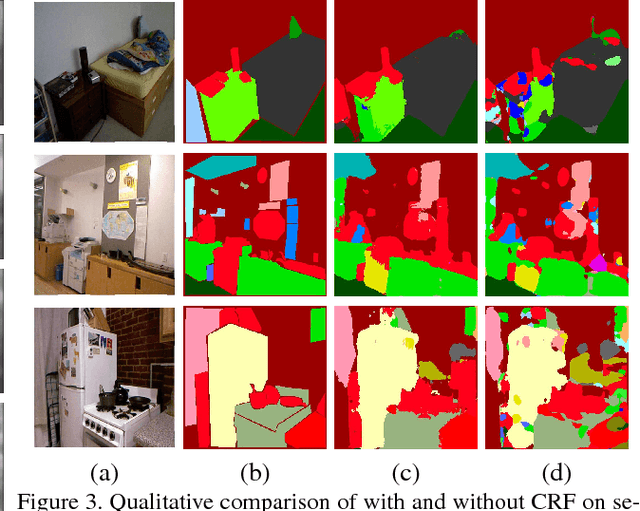
Multi-scale deep CNNs have been used successfully for problems mapping each pixel to a label, such as depth estimation and semantic segmentation. It has also been shown that such architectures are reusable and can be used for multiple tasks. These networks are typically trained independently for each task by varying the output layer(s) and training objective. In this work we present a new model for simultaneous depth estimation and semantic segmentation from a single RGB image. Our approach demonstrates the feasibility of training parts of the model for each task and then fine tuning the full, combined model on both tasks simultaneously using a single loss function. Furthermore we couple the deep CNN with fully connected CRF, which captures the contextual relationships and interactions between the semantic and depth cues improving the accuracy of the final results. The proposed model is trained and evaluated on NYUDepth V2 dataset outperforming the state of the art methods on semantic segmentation and achieving comparable results on the task of depth estimation.
DeepCAMP: Deep Convolutional Action & Attribute Mid-Level Patterns
Aug 10, 2016
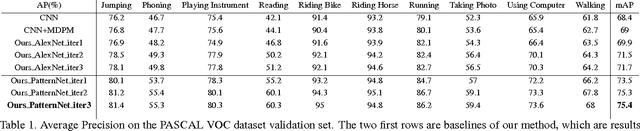
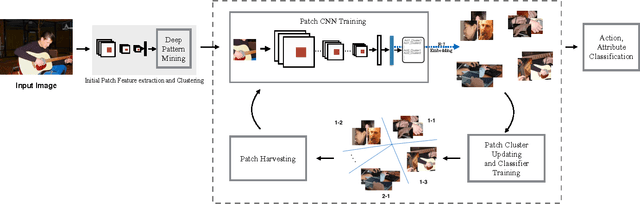
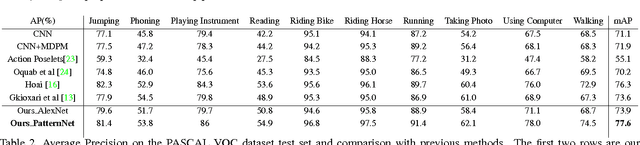
The recognition of human actions and the determination of human attributes are two tasks that call for fine-grained classification. Indeed, often rather small and inconspicuous objects and features have to be detected to tell their classes apart. In order to deal with this challenge, we propose a novel convolutional neural network that mines mid-level image patches that are sufficiently dedicated to resolve the corresponding subtleties. In particular, we train a newly de- signed CNN (DeepPattern) that learns discriminative patch groups. There are two innovative aspects to this. On the one hand we pay attention to contextual information in an origi- nal fashion. On the other hand, we let an iteration of feature learning and patch clustering purify the set of dedicated patches that we use. We validate our method for action clas- sification on two challenging datasets: PASCAL VOC 2012 Action and Stanford 40 Actions, and for attribute recogni- tion we use the Berkeley Attributes of People dataset. Our discriminative mid-level mining CNN obtains state-of-the- art results on these datasets, without a need for annotations about parts and poses.