 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Two-Stream Motion and Appearance 3D CNNs for Video Classification
Sep 02, 2016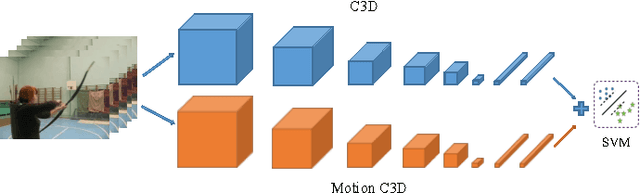
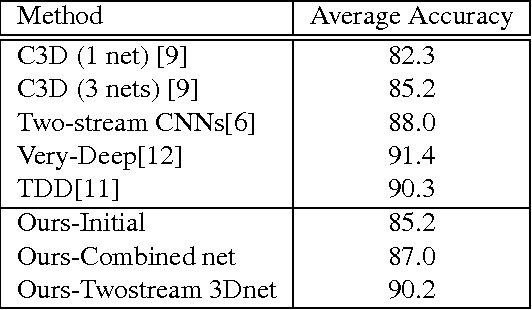
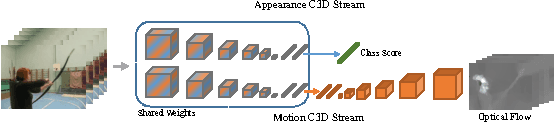
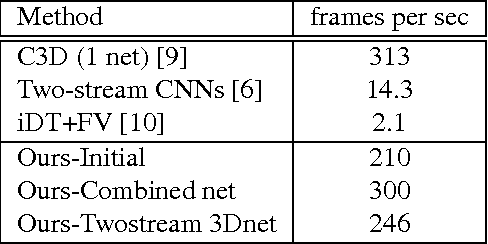
The video and action classification have extremely evolved by deep neural networks specially with two stream CNN using RGB and optical flow as inputs and they present outstanding performance in terms of video analysis. One of the shortcoming of these methods is handling motion information extraction which is done out side of the CNNs and relatively time consuming also on GPUs. So proposing end-to-end methods which are exploring to learn motion representation, like 3D-CNN can achieve faster and accurate performance. We present some novel deep CNNs using 3D architecture to model actions and motion representation in an efficient way to be accurate and also as fast as real-time. Our new networks learn distinctive models to combine deep motion features into appearance model via learning optical flow features inside the network.
DeepCAMP: Deep Convolutional Action & Attribute Mid-Level Patterns
Aug 10, 2016
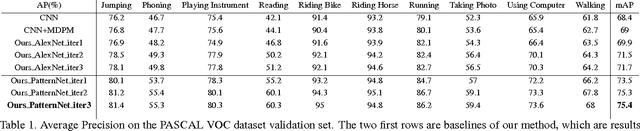
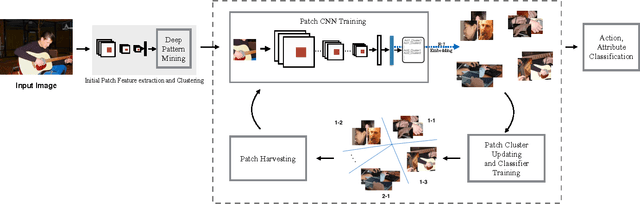
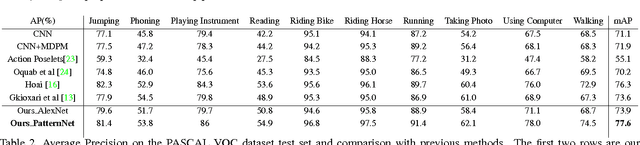
The recognition of human actions and the determination of human attributes are two tasks that call for fine-grained classification. Indeed, often rather small and inconspicuous objects and features have to be detected to tell their classes apart. In order to deal with this challenge, we propose a novel convolutional neural network that mines mid-level image patches that are sufficiently dedicated to resolve the corresponding subtleties. In particular, we train a newly de- signed CNN (DeepPattern) that learns discriminative patch groups. There are two innovative aspects to this. On the one hand we pay attention to contextual information in an origi- nal fashion. On the other hand, we let an iteration of feature learning and patch clustering purify the set of dedicated patches that we use. We validate our method for action clas- sification on two challenging datasets: PASCAL VOC 2012 Action and Stanford 40 Actions, and for attribute recogni- tion we use the Berkeley Attributes of People dataset. Our discriminative mid-level mining CNN obtains state-of-the- art results on these datasets, without a need for annotations about parts and poses.