 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Certified Robustness Against Real-World Distribution Shifts
Jun 09, 2022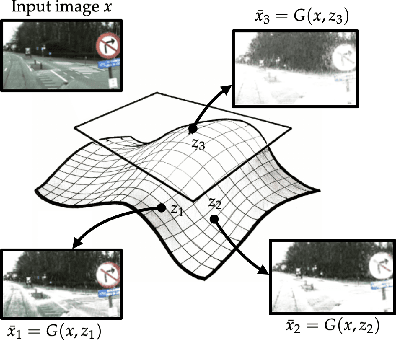
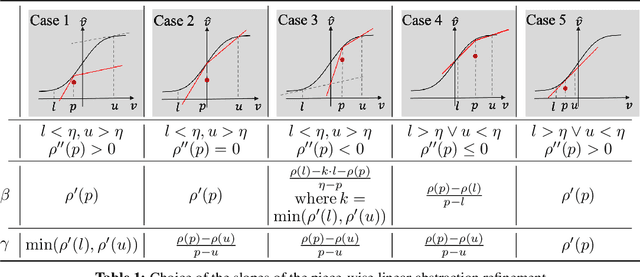
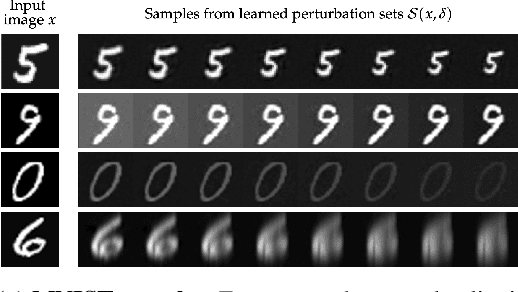
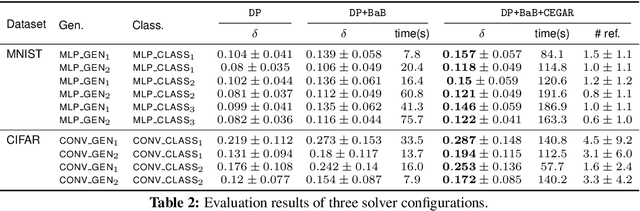
We consider the problem of certifying the robustness of deep neural networks against real-world distribution shifts. To do so, we bridge the gap between hand-crafted specifications and realistic deployment settings by proposing a novel neural-symbolic verification framework, in which we train a generative model to learn perturbations from data and define specifications with respect to the output of the learned model. A unique challenge arising from this setting is that existing verifiers cannot tightly approximate sigmoid activations, which are fundamental to many state-of-the-art generative models. To address this challenge, we propose a general meta-algorithm for handling sigmoid activations which leverages classical notions of counter-example-guided abstraction refinement. The key idea is to "lazily" refine the abstraction of sigmoid functions to exclude spurious counter-examples found in the previous abstraction, thus guaranteeing progress in the verification process while keeping the state-space small. Experiments on the MNIST and CIFAR-10 datasets show that our framework significantly outperforms existing methods on a range of challenging distribution shifts.
Collaborative Learning of Distributions under Heterogeneity and Communication Constraints
Jun 07, 2022
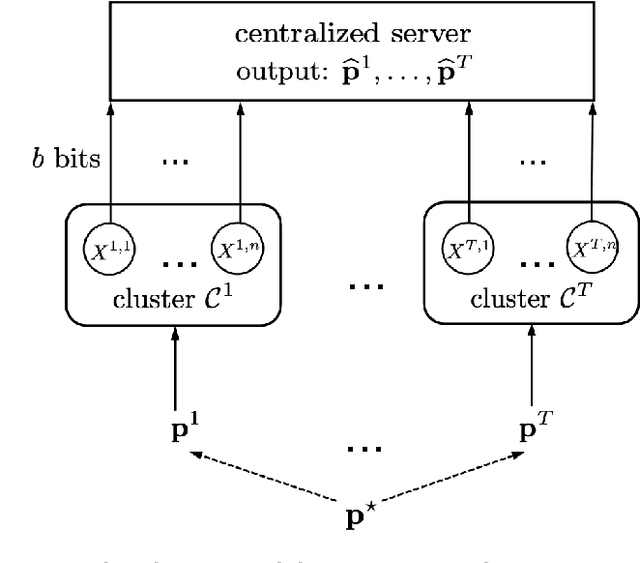
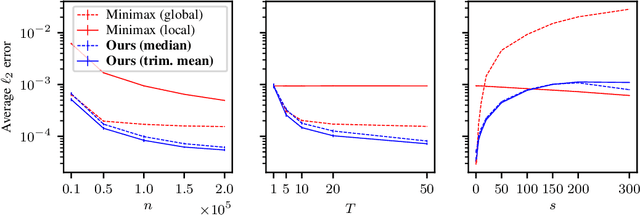
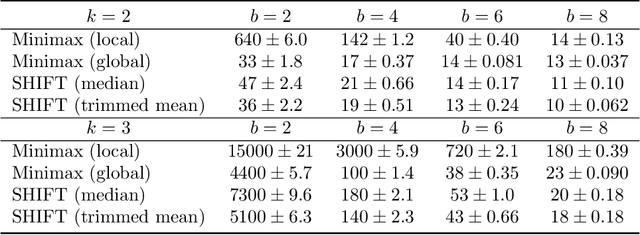
In modern machine learning, users often have to collaborate to learn the distribution of the data. Communication can be a significant bottleneck. Prior work has studied homogeneous users -- i.e., whose data follow the same discrete distribution -- and has provided optimal communication-efficient methods for estimating that distribution. However, these methods rely heavily on homogeneity, and are less applicable in the common case when users' discrete distributions are heterogeneous. Here we consider a natural and tractable model of heterogeneity, where users' discrete distributions only vary sparsely, on a small number of entries. We propose a novel two-stage method named SHIFT: First, the users collaborate by communicating with the server to learn a central distribution; relying on methods from robust statistics. Then, the learned central distribution is fine-tuned to estimate their respective individual distribution. We show that SHIFT is minimax optimal in our model of heterogeneity and under communication constraints. Further, we provide experimental results using both synthetic data and $n$-gram frequency estimation in the text domain, which corroborate its efficiency.
Collaborative Linear Bandits with Adversarial Agents: Near-Optimal Regret Bounds
Jun 06, 2022
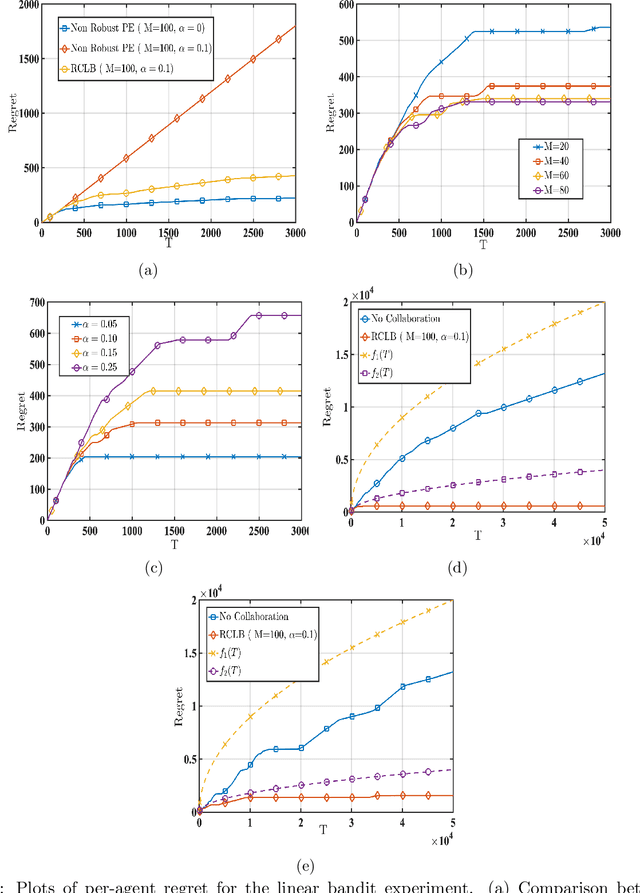
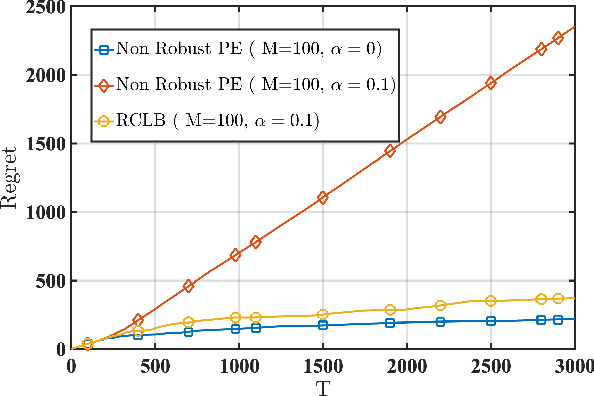
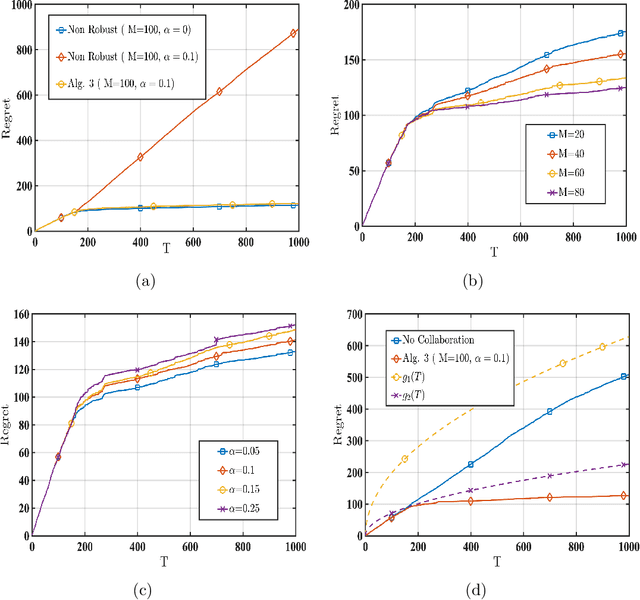
We consider a linear stochastic bandit problem involving $M$ agents that can collaborate via a central server to minimize regret. A fraction $\alpha$ of these agents are adversarial and can act arbitrarily, leading to the following tension: while collaboration can potentially reduce regret, it can also disrupt the process of learning due to adversaries. In this work, we provide a fundamental understanding of this tension by designing new algorithms that balance the exploration-exploitation trade-off via carefully constructed robust confidence intervals. We also complement our algorithms with tight analyses. First, we develop a robust collaborative phased elimination algorithm that achieves $\tilde{O}\left(\alpha+ 1/\sqrt{M}\right) \sqrt{dT}$ regret for each good agent; here, $d$ is the model-dimension and $T$ is the horizon. For small $\alpha$, our result thus reveals a clear benefit of collaboration despite adversaries. Using an information-theoretic argument, we then prove a matching lower bound, thereby providing the first set of tight, near-optimal regret bounds for collaborative linear bandits with adversaries. Furthermore, by leveraging recent advances in high-dimensional robust statistics, we significantly extend our algorithmic ideas and results to (i) the generalized linear bandit model that allows for non-linear observation maps; and (ii) the contextual bandit setting that allows for time-varying feature vectors.
Straggler-Resilient Personalized Federated Learning
Jun 05, 2022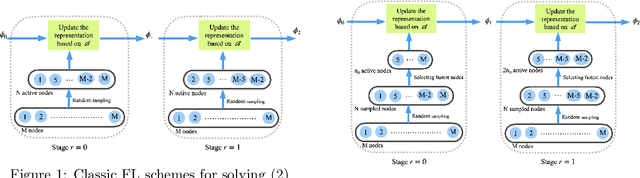
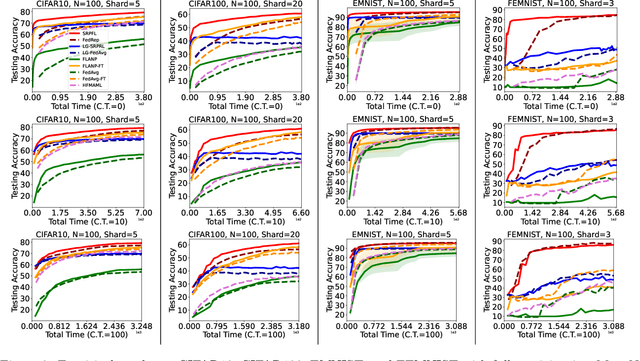
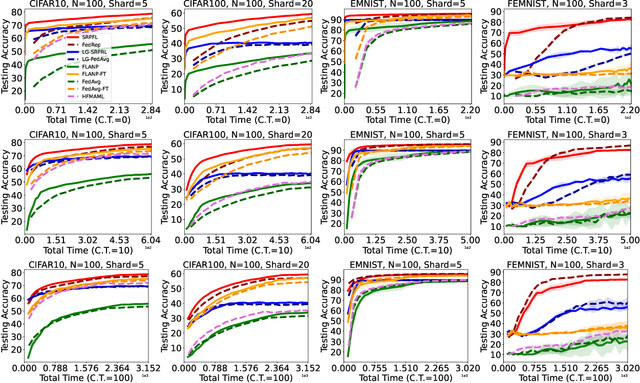
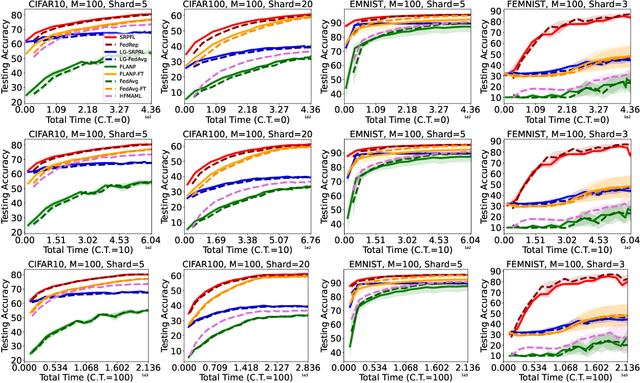
Federated Learning is an emerging learning paradigm that allows training models from samples distributed across a large network of clients while respecting privacy and communication restrictions. Despite its success, federated learning faces several challenges related to its decentralized nature. In this work, we develop a novel algorithmic procedure with theoretical speedup guarantees that simultaneously handles two of these hurdles, namely (i) data heterogeneity, i.e., data distributions can vary substantially across clients, and (ii) system heterogeneity, i.e., the computational power of the clients could differ significantly. Our method relies on ideas from representation learning theory to find a global common representation using all clients' data and learn a user-specific set of parameters leading to a personalized solution for each client. Furthermore, our method mitigates the effects of stragglers by adaptively selecting clients based on their computational characteristics and statistical significance, thus achieving, for the first time, near optimal sample complexity and provable logarithmic speedup. Experimental results support our theoretical findings showing the superiority of our method over alternative personalized federated schemes in system and data heterogeneous environments.
Self-Consistency of the Fokker-Planck Equation
Jun 02, 2022

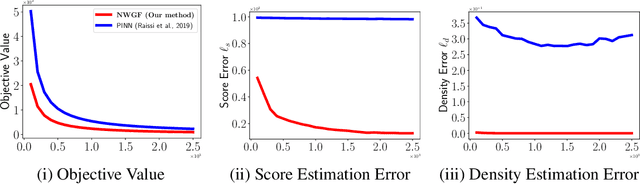
The Fokker-Planck equation (FPE) is the partial differential equation that governs the density evolution of the It\^o process and is of great importance to the literature of statistical physics and machine learning. The FPE can be regarded as a continuity equation where the change of the density is completely determined by a time varying velocity field. Importantly, this velocity field also depends on the current density function. As a result, the ground-truth velocity field can be shown to be the solution of a fixed-point equation, a property that we call self-consistency. In this paper, we exploit this concept to design a potential function of the hypothesis velocity fields, and prove that, if such a function diminishes to zero during the training procedure, the trajectory of the densities generated by the hypothesis velocity fields converges to the solution of the FPE in the Wasserstein-2 sense. The proposed potential function is amenable to neural-network based parameterization as the stochastic gradient with respect to the parameter can be efficiently computed. Once a parameterized model, such as Neural Ordinary Differential Equation is trained, we can generate the entire trajectory to the FPE.
FedAvg with Fine Tuning: Local Updates Lead to Representation Learning
May 27, 2022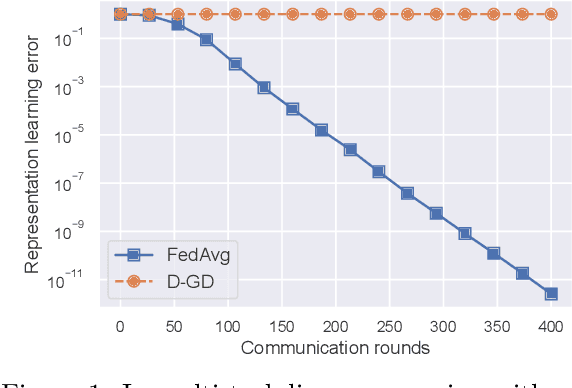

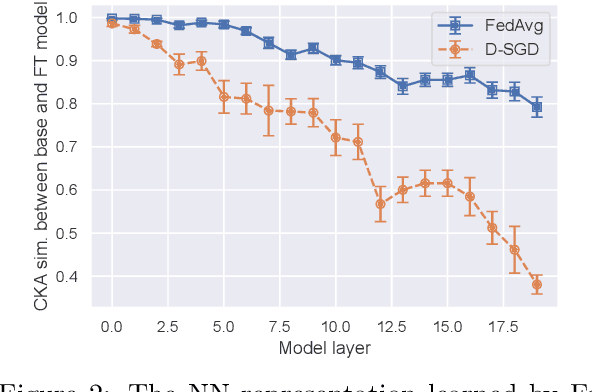
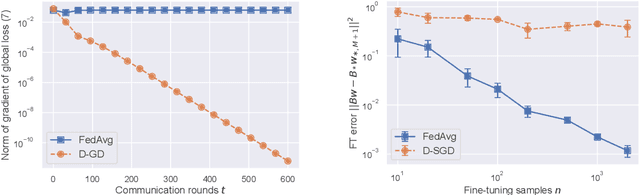
The Federated Averaging (FedAvg) algorithm, which consists of alternating between a few local stochastic gradient updates at client nodes, followed by a model averaging update at the server, is perhaps the most commonly used method in Federated Learning. Notwithstanding its simplicity, several empirical studies have illustrated that the output model of FedAvg, after a few fine-tuning steps, leads to a model that generalizes well to new unseen tasks. This surprising performance of such a simple method, however, is not fully understood from a theoretical point of view. In this paper, we formally investigate this phenomenon in the multi-task linear representation setting. We show that the reason behind generalizability of the FedAvg's output is its power in learning the common data representation among the clients' tasks, by leveraging the diversity among client data distributions via local updates. We formally establish the iteration complexity required by the clients for proving such result in the setting where the underlying shared representation is a linear map. To the best of our knowledge, this is the first such result for any setting. We also provide empirical evidence demonstrating FedAvg's representation learning ability in federated image classification with heterogeneous data.
Distributed Statistical Min-Max Learning in the Presence of Byzantine Agents
Apr 07, 2022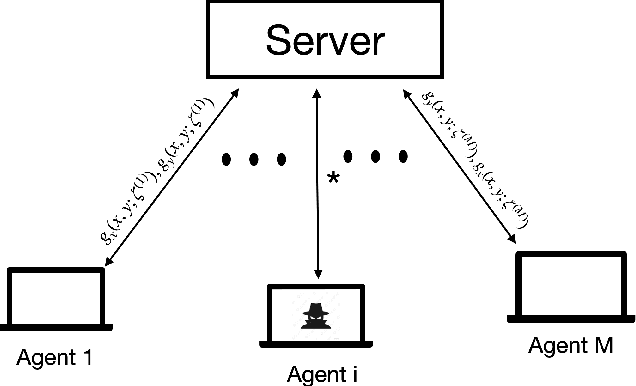
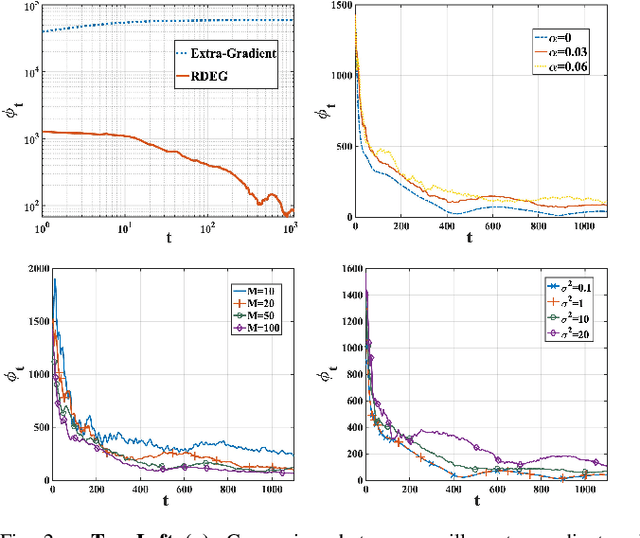
Recent years have witnessed a growing interest in the topic of min-max optimization, owing to its relevance in the context of generative adversarial networks (GANs), robust control and optimization, and reinforcement learning. Motivated by this line of work, we consider a multi-agent min-max learning problem, and focus on the emerging challenge of contending with worst-case Byzantine adversarial agents in such a setup. By drawing on recent results from robust statistics, we design a robust distributed variant of the extra-gradient algorithm - a popular algorithmic approach for min-max optimization. Our main contribution is to provide a crisp analysis of the proposed robust extra-gradient algorithm for smooth convex-concave and smooth strongly convex-strongly concave functions. Specifically, we establish statistical rates of convergence to approximate saddle points. Our rates are near-optimal, and reveal both the effect of adversarial corruption and the benefit of collaboration among the non-faulty agents. Notably, this is the first paper to provide formal theoretical guarantees for large-scale distributed min-max learning in the presence of adversarial agents.
Neural Estimation of the Rate-Distortion Function With Applications to Operational Source Coding
Apr 04, 2022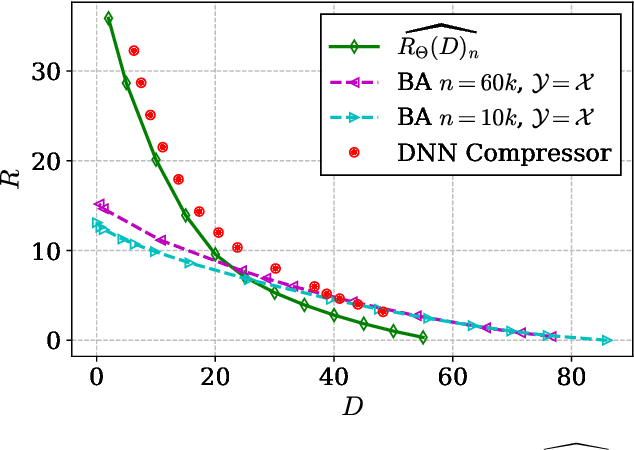
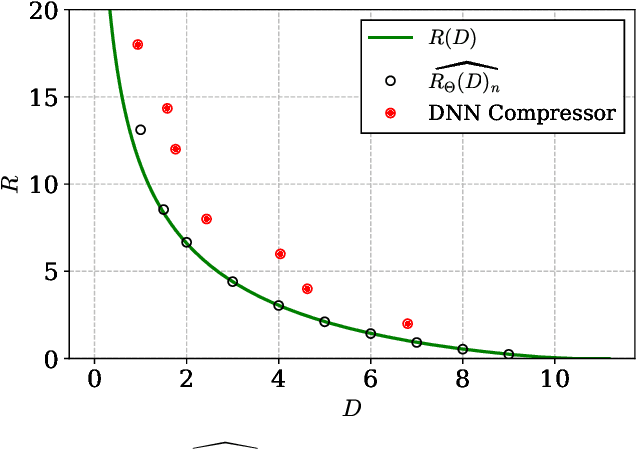
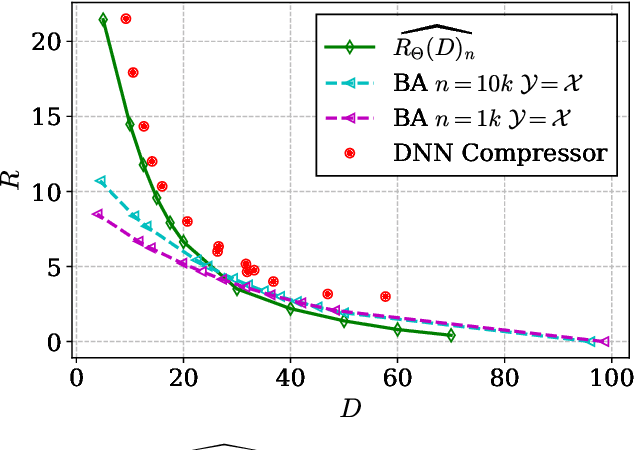

A fundamental question in designing lossy data compression schemes is how well one can do in comparison with the rate-distortion function, which describes the known theoretical limits of lossy compression. Motivated by the empirical success of deep neural network (DNN) compressors on large, real-world data, we investigate methods to estimate the rate-distortion function on such data, which would allow comparison of DNN compressors with optimality. While one could use the empirical distribution of the data and apply the Blahut-Arimoto algorithm, this approach presents several computational challenges and inaccuracies when the datasets are large and high-dimensional, such as the case of modern image datasets. Instead, we re-formulate the rate-distortion objective, and solve the resulting functional optimization problem using neural networks. We apply the resulting rate-distortion estimator, called NERD, on popular image datasets, and provide evidence that NERD can accurately estimate the rate-distortion function. Using our estimate, we show that the rate-distortion achievable by DNN compressors are within several bits of the rate-distortion function for real-world datasets. Additionally, NERD provides access to the rate-distortion achieving channel, as well as samples from its output marginal. Therefore, using recent results in reverse channel coding, we describe how NERD can be used to construct an operational one-shot lossy compression scheme with guarantees on the achievable rate and distortion. Experimental results demonstrate competitive performance with DNN compressors.
Chordal Sparsity for Lipschitz Constant Estimation of Deep Neural Networks
Apr 02, 2022
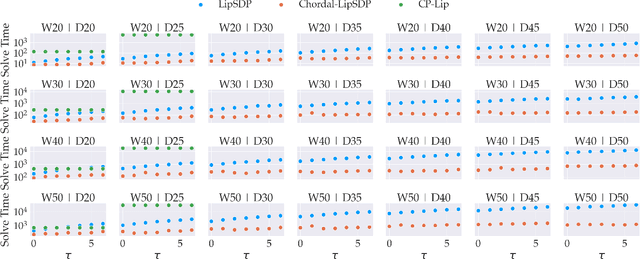
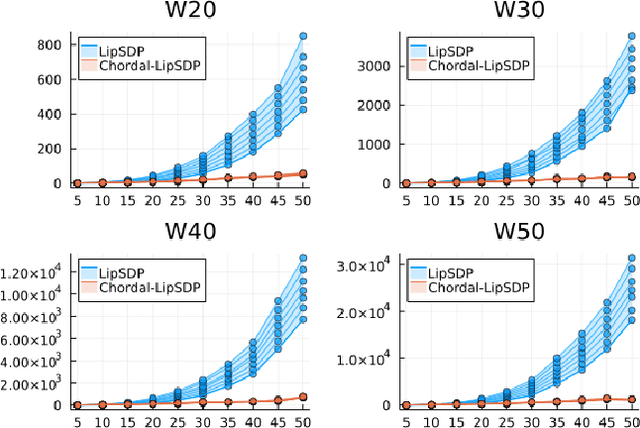
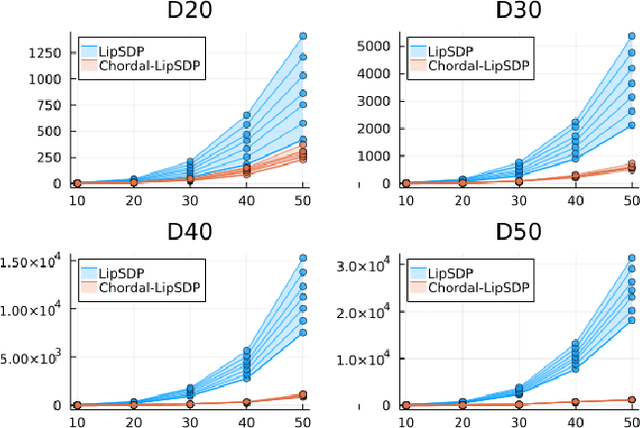
Lipschitz constants of neural networks allow for guarantees of robustness in image classification, safety in controller design, and generalizability beyond the training data. As calculating Lipschitz constants is NP-hard, techniques for estimating Lipschitz constants must navigate the trade-off between scalability and accuracy. In this work, we significantly push the scalability frontier of a semidefinite programming technique known as LipSDP while achieving zero accuracy loss. We first show that LipSDP has chordal sparsity, which allows us to derive a chordally sparse formulation that we call Chordal-LipSDP. The key benefit is that the main computational bottleneck of LipSDP, a large semidefinite constraint, is now decomposed into an equivalent collection of smaller ones: allowing Chordal-LipSDP to outperform LipSDP particularly as the network depth grows. Moreover, our formulation uses a tunable sparsity parameter that enables one to gain tighter estimates without incurring a significant computational cost. We illustrate the scalability of our approach through extensive numerical experiments.
T-Cal: An optimal test for the calibration of predictive models
Mar 25, 2022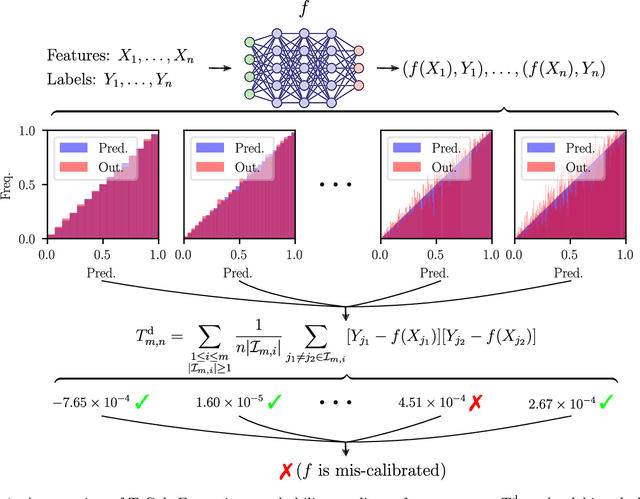
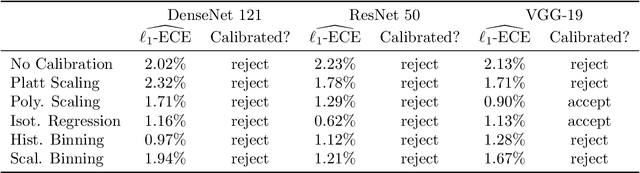
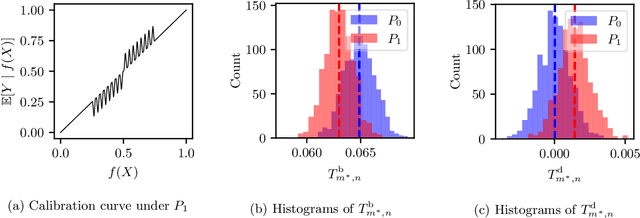
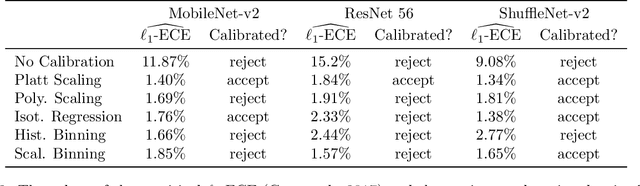
The prediction accuracy of machine learning methods is steadily increasing, but the calibration of their uncertainty predictions poses a significant challenge. Numerous works focus on obtaining well-calibrated predictive models, but less is known about reliably assessing model calibration. This limits our ability to know when algorithms for improving calibration have a real effect, and when their improvements are merely artifacts due to random noise in finite datasets. In this work, we consider detecting mis-calibration of predictive models using a finite validation dataset as a hypothesis testing problem. The null hypothesis is that the predictive model is calibrated, while the alternative hypothesis is that the deviation from calibration is sufficiently large. We find that detecting mis-calibration is only possible when the conditional probabilities of the classes are sufficiently smooth functions of the predictions. When the conditional class probabilities are H\"older continuous, we propose T-Cal, a minimax optimal test for calibration based on a debiased plug-in estimator of the $\ell_2$-Expected Calibration Error (ECE). We further propose Adaptive T-Cal, a version that is adaptive to unknown smoothness. We verify our theoretical findings with a broad range of experiments, including with several popular deep neural net architectures and several standard post-hoc calibration methods. T-Cal is a practical general-purpose tool, which -- combined with classical tests for discrete-valued predictors -- can be used to test the calibration of virtually any probabilistic classification method.