 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Approximation for Pessimistic Offline Reinforcement Learning
Dec 19, 2023



Deep reinforcement learning (RL) has shown remarkable success in specific offline decision-making scenarios, yet its theoretical guarantees are still under development. Existing works on offline RL theory primarily emphasize a few trivial settings, such as linear MDP or general function approximation with strong assumptions and independent data, which lack guidance for practical use. The coupling of deep learning and Bellman residuals makes this problem challenging, in addition to the difficulty of data dependence. In this paper, we establish a non-asymptotic estimation error of pessimistic offline RL using general neural network approximation with $\mathcal{C}$-mixing data regarding the structure of networks, the dimension of datasets, and the concentrability of data coverage, under mild assumptions. Our result shows that the estimation error consists of two parts: the first converges to zero at a desired rate on the sample size with partially controllable concentrability, and the second becomes negligible if the residual constraint is tight. This result demonstrates the explicit efficiency of deep adversarial offline RL frameworks. We utilize the empirical process tool for $\mathcal{C}$-mixing sequences and the neural network approximation theory for the H\"{o}lder class to achieve this. We also develop methods to bound the Bellman estimation error caused by function approximation with empirical Bellman constraint perturbations. Additionally, we present a result that lessens the curse of dimensionality using data with low intrinsic dimensionality and function classes with low complexity. Our estimation provides valuable insights into the development of deep offline RL and guidance for algorithm model design.
A Finite Expression Method for Solving High-Dimensional Committor Problems
Jun 21, 2023



Transition path theory (TPT) is a mathematical framework for quantifying rare transition events between a pair of selected metastable states $A$ and $B$. Central to TPT is the committor function, which describes the probability to hit the metastable state $B$ prior to $A$ from any given starting point of the phase space. Once the committor is computed, the transition channels and the transition rate can be readily found. The committor is the solution to the backward Kolmogorov equation with appropriate boundary conditions. However, solving it is a challenging task in high dimensions due to the need to mesh a whole region of the ambient space. In this work, we explore the finite expression method (FEX, Liang and Yang (2022)) as a tool for computing the committor. FEX approximates the committor by an algebraic expression involving a fixed finite number of nonlinear functions and binary arithmetic operations. The optimal nonlinear functions, the binary operations, and the numerical coefficients in the expression template are found via reinforcement learning. The FEX-based committor solver is tested on several high-dimensional benchmark problems. It gives comparable or better results than neural network-based solvers. Most importantly, FEX is capable of correctly identifying the algebraic structure of the solution which allows one to reduce the committor problem to a low-dimensional one and find the committor with any desired accuracy.
Spectral Clustering via Orthogonalization-Free Methods
May 16, 2023



Graph Signal Filter used as dimensionality reduction in spectral clustering usually requires expensive eigenvalue estimation. We analyze the filter in an optimization setting and propose to use four orthogonalization-free methods by optimizing objective functions as dimensionality reduction in spectral clustering. The proposed methods do not utilize any orthogonalization, which is known as not well scalable in a parallel computing environment. Our methods theoretically construct adequate feature space, which is, at most, a weighted alteration to the eigenspace of a normalized Laplacian matrix. We numerically hypothesize that the proposed methods are equivalent in clustering quality to the ideal Graph Signal Filter, which exploits the exact eigenvalue needed without expensive eigenvalue estimation. Numerical results show that the proposed methods outperform Power Iteration-based methods and Graph Signal Filter in clustering quality and computation cost. Unlike Power Iteration-based methods and Graph Signal Filter which require random signal input, our methods are able to utilize available initialization in the streaming graph scenarios. Additionally, numerical results show that our methods outperform ARPACK and are faster than LOBPCG in the streaming graph scenarios. We also present numerical results showing the scalability of our methods in multithreading and multiprocessing implementations to facilitate parallel spectral clustering.
Nearly Optimal VC-Dimension and Pseudo-Dimension Bounds for Deep Neural Network Derivatives
May 15, 2023



This paper addresses the problem of nearly optimal Vapnik--Chervonenkis dimension (VC-dimension) and pseudo-dimension estimations of the derivative functions of deep neural networks (DNNs). Two important applications of these estimations include: 1) Establishing a nearly tight approximation result of DNNs in the Sobolev space; 2) Characterizing the generalization error of machine learning methods with loss functions involving function derivatives. This theoretical investigation fills the gap of learning error estimations for a wide range of physics-informed machine learning models and applications including generative models, solving partial differential equations, operator learning, network compression, distillation, regularization, etc.
Finite Expression Methods for Discovering Physical Laws from Data
May 15, 2023



Nonlinear dynamics is a pervasive phenomenon observed in various scientific and engineering disciplines. However, uncovering analytical expressions that describe nonlinear dynamics from limited data remains a challenging and essential task. In this paper, we propose a new deep symbolic learning method called the ``finite expression method'' (FEX) to identify the governing equations within the space of functions containing a finite set of analytic expressions, based on observed dynamic data. The core idea is to leverage FEX to generate analytical expressions of the governing equations by learning the derivatives of partial differential equation (PDE) solutions using convolutions. Our numerical results demonstrate that FEX outperforms all existing methods (such as PDE-Net, SINDy, GP, and SPL) in terms of numerical performance across various problems, including time-dependent PDE problems and nonlinear dynamical systems with time-varying coefficients. Furthermore, the results highlight that FEX exhibits flexibility and expressive power in accurately approximating symbolic governing equations, while maintaining low memory and favorable time complexity.
Convergence Analysis of the Deep Galerkin Method for Weak Solutions
Feb 05, 2023This paper analyzes the convergence rate of a deep Galerkin method for the weak solution (DGMW) of second-order elliptic partial differential equations on $\mathbb{R}^d$ with Dirichlet, Neumann, and Robin boundary conditions, respectively. In DGMW, a deep neural network is applied to parametrize the PDE solution, and a second neural network is adopted to parametrize the test function in the traditional Galerkin formulation. By properly choosing the depth and width of these two networks in terms of the number of training samples $n$, it is shown that the convergence rate of DGMW is $\mathcal{O}(n^{-1/d})$, which is the first convergence result for weak solutions. The main idea of the proof is to divide the error of the DGMW into an approximation error and a statistical error. We derive an upper bound on the approximation error in the $H^{1}$ norm and bound the statistical error via Rademacher complexity.
Deep Operator Learning Lessens the Curse of Dimensionality for PDEs
Jan 28, 2023
Deep neural networks (DNNs) have seen tremendous success in many fields and their developments in PDE-related problems are rapidly growing. This paper provides an estimate for the generalization error of learning Lipschitz operators over Banach spaces using DNNs with applications to various PDE solution operators. The goal is to specify DNN width, depth, and the number of training samples needed to guarantee a certain testing error. Under mild assumptions on data distributions or operator structures, our analysis shows that deep operator learning can have a relaxed dependence on the discretization resolution of PDEs and, hence, lessen the curse of dimensionality in many PDE-related problems. We apply our results to various PDEs, including elliptic equations, parabolic equations, and Burgers equations.
A Distributed Block Chebyshev-Davidson Algorithm for Parallel Spectral Clustering
Dec 08, 2022



We develop a distributed Block Chebyshev-Davidson algorithm to solve large-scale leading eigenvalue problems for spectral analysis in spectral clustering. First, the efficiency of the Chebyshev-Davidson algorithm relies on the prior knowledge of the eigenvalue spectrum, which could be expensive to estimate. This issue can be lessened by the analytic spectrum estimation of the Laplacian or normalized Laplacian matrices in spectral clustering, making the proposed algorithm very efficient for spectral clustering. Second, to make the proposed algorithm capable of analyzing big data, a distributed and parallel version has been developed with attractive scalability. The speedup by parallel computing is approximately equivalent to $\sqrt{p}$, where $p$ denotes the number of processes. Numerical results will be provided to demonstrate its efficiency and advantage over existing algorithms in both sequential and parallel computing.
What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?
Dec 07, 2022



Various types of Multi-Agent Reinforcement Learning (MARL) methods have been developed, assuming that agents' policies are based on true states. Recent works have improved the robustness of MARL under uncertainties from the reward, transition probability, or other partners' policies. However, in real-world multi-agent systems, state estimations may be perturbed by sensor measurement noise or even adversaries. Agents' policies trained with only true state information will deviate from optimal solutions when facing adversarial state perturbations during execution. MARL under adversarial state perturbations has limited study. Hence, in this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to study the fundamental properties of MARL under state uncertainties. We prove that the optimal agent policy and the robust Nash equilibrium do not always exist for an SAMG. Instead, we define the solution concept, robust agent policy, of the proposed SAMG under adversarial state perturbations, where agents want to maximize the worst-case expected state value. We then design a gradient descent ascent-based robust MARL algorithm to learn the robust policies for the MARL agents. Our experiments show that adversarial state perturbations decrease agents' rewards for several baselines from the existing literature, while our algorithm outperforms baselines with state perturbations and significantly improves the robustness of the MARL policies under state uncertainties.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022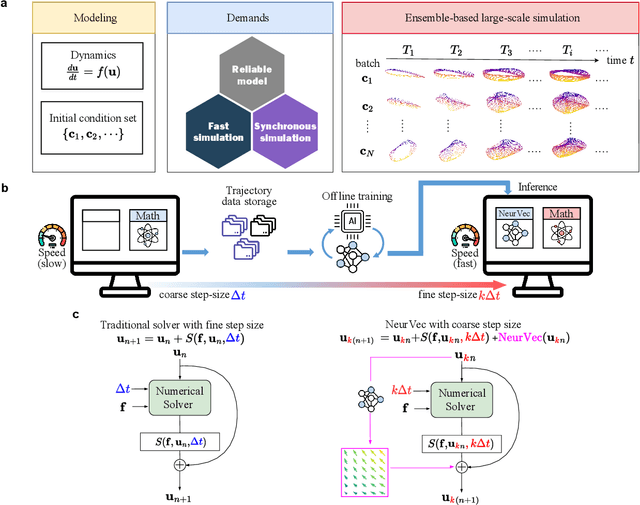

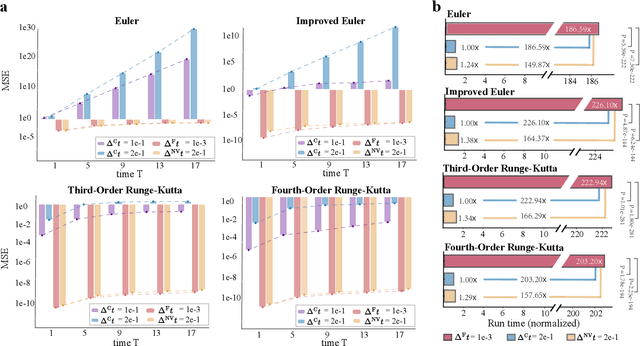
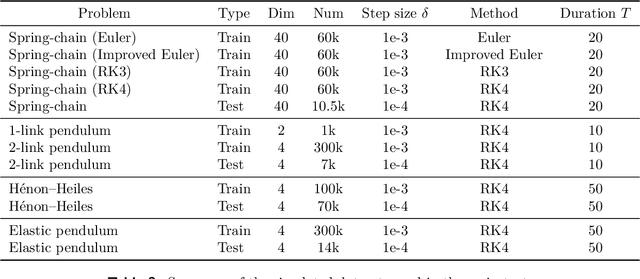
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.