 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMGFormer: Adaptive Multi-Granular Transformer for Brain Tumor Segmentation with Missing Modalities
Jan 27, 2026Multimodal MRI is essential for brain tumor segmentation, yet missing modalities in clinical practice cause existing methods to exhibit >40% performance variance across modality combinations, rendering them clinically unreliable. We propose AMGFormer, achieving significantly improved stability through three synergistic modules: (1) QuadIntegrator Bridge (QIB) enabling spatially adaptive fusion maintaining consistent predictions regardless of available modalities, (2) Multi-Granular Attention Orchestrator (MGAO) focusing on pathological regions to reduce background sensitivity, and (3) Modality Quality-Aware Enhancement (MQAE) preventing error propagation from corrupted sequences. On BraTS 2018, our method achieves 89.33% WT, 82.70% TC, 67.23% ET Dice scores with <0.5% variance across 15 modality combinations, solving the stability crisis. Single-modality ET segmentation shows 40-81% relative improvements over state-of-the-art methods. The method generalizes to BraTS 2020/2021, achieving up to 92.44% WT, 89.91% TC, 84.57% ET. The model demonstrates potential for clinical deployment with 1.2s inference. Code: https://github.com/guochengxiangives/AMGFormer.
MuVAM: A Multi-View Attention-based Model for Medical Visual Question Answering
Jul 07, 2021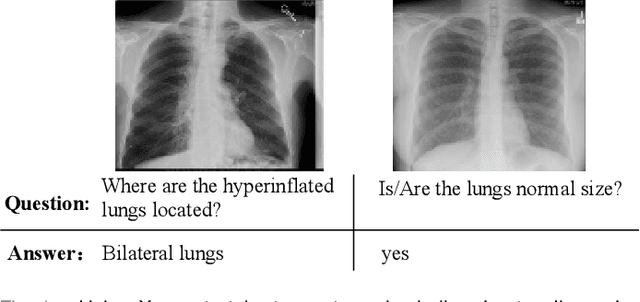
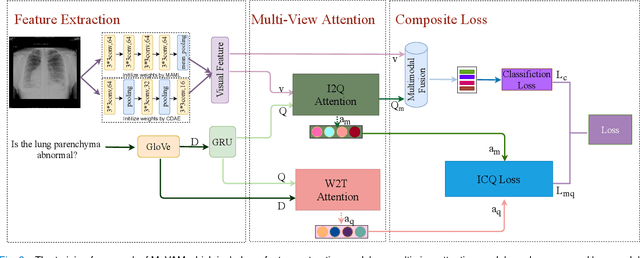
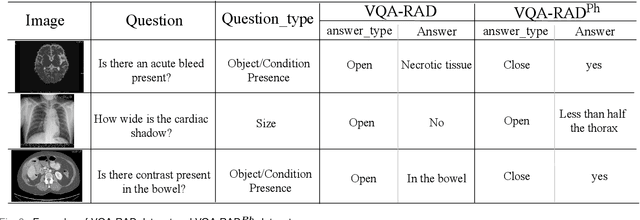
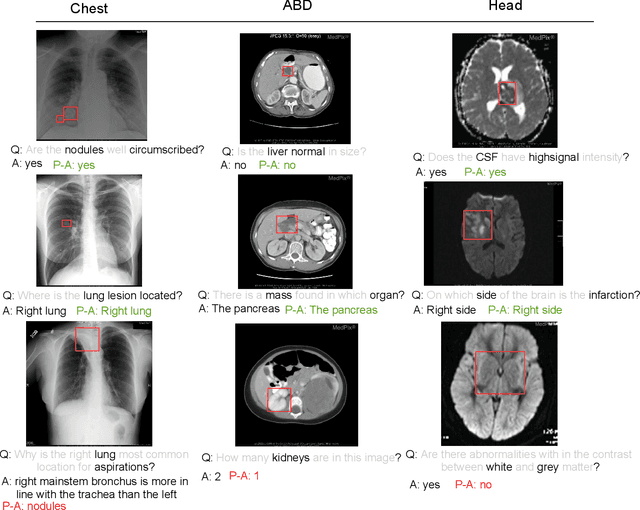
Medical Visual Question Answering (VQA) is a multi-modal challenging task widely considered by research communities of the computer vision and natural language processing. Since most current medical VQA models focus on visual content, ignoring the importance of text, this paper proposes a multi-view attention-based model(MuVAM) for medical visual question answering which integrates the high-level semantics of medical images on the basis of text description. Firstly, different methods are utilized to extract the features of the image and the question for the two modalities of vision and text. Secondly, this paper proposes a multi-view attention mechanism that include Image-to-Question (I2Q) attention and Word-to-Text (W2T) attention. Multi-view attention can correlate the question with image and word in order to better analyze the question and get an accurate answer. Thirdly, a composite loss is presented to predict the answer accurately after multi-modal feature fusion and improve the similarity between visual and textual cross-modal features. It consists of classification loss and image-question complementary (IQC) loss. Finally, for data errors and missing labels in the VQA-RAD dataset, we collaborate with medical experts to correct and complete this dataset and then construct an enhanced dataset, VQA-RADPh. The experiments on these two datasets show that the effectiveness of MuVAM surpasses the state-of-the-art method.