 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization for Stochastic Shortest Path
Feb 07, 2022Policy optimization is among the most popular and successful reinforcement learning algorithms, and there is increasing interest in understanding its theoretical guarantees. In this work, we initiate the study of policy optimization for the stochastic shortest path (SSP) problem, a goal-oriented reinforcement learning model that strictly generalizes the finite-horizon model and better captures many applications. We consider a wide range of settings, including stochastic and adversarial environments under full information or bandit feedback, and propose a policy optimization algorithm for each setting that makes use of novel correction terms and/or variants of dilated bonuses (Luo et al., 2021). For most settings, our algorithm is shown to achieve a near-optimal regret bound. One key technical contribution of this work is a new approximation scheme to tackle SSP problems that we call \textit{stacked discounted approximation} and use in all our proposed algorithms. Unlike the finite-horizon approximation that is heavily used in recent SSP algorithms, our new approximation enables us to learn a near-stationary policy with only logarithmic changes during an episode and could lead to an exponential improvement in space complexity.
Kernelized Multiplicative Weights for 0/1-Polyhedral Games: Bridging the Gap Between Learning in Extensive-Form and Normal-Form Games
Feb 01, 2022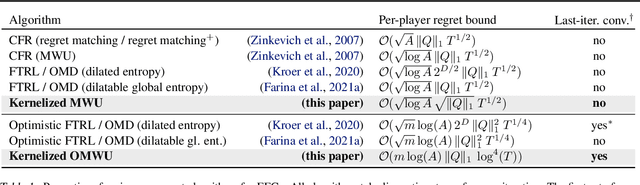
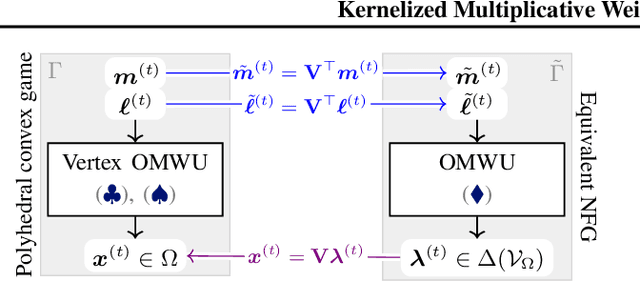
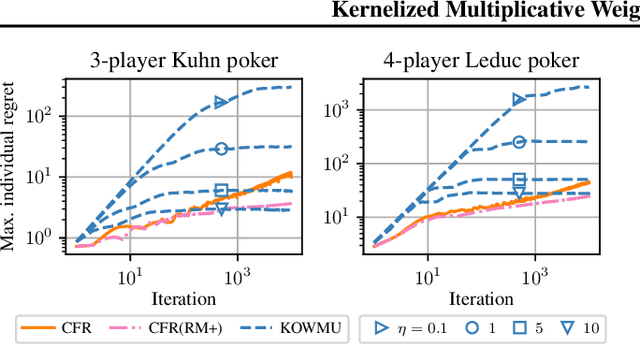
While extensive-form games (EFGs) can be converted into normal-form games (NFGs), doing so comes at the cost of an exponential blowup of the strategy space. So, progress on NFGs and EFGs has historically followed separate tracks, with the EFG community often having to catch up with advances (e.g., last-iterate convergence and predictive regret bounds) from the larger NFG community. In this paper we show that the Optimistic Multiplicative Weights Update (OMWU) algorithm -- the premier learning algorithm for NFGs -- can be simulated on the normal-form equivalent of an EFG in linear time per iteration in the game tree size using a kernel trick. The resulting algorithm, Kernelized OMWU (KOMWU), applies more broadly to all convex games whose strategy space is a polytope with 0/1 integral vertices, as long as the kernel can be evaluated efficiently. In the particular case of EFGs, KOMWU closes several standing gaps between NFG and EFG learning, by enabling direct, black-box transfer to EFGs of desirable properties of learning dynamics that were so far known to be achievable only in NFGs. Specifically, KOMWU gives the first algorithm that guarantees at the same time last-iterate convergence, lower dependence on the size of the game tree than all prior algorithms, and $\tilde{\mathcal{O}}(1)$ regret when followed by all players.
Learning Infinite-Horizon Average-Reward Markov Decision Processes with Constraints
Jan 31, 2022We study regret minimization for infinite-horizon average-reward Markov Decision Processes (MDPs) under cost constraints. We start by designing a policy optimization algorithm with carefully designed action-value estimator and bonus term, and show that for ergodic MDPs, our algorithm ensures $\widetilde{O}(\sqrt{T})$ regret and constant constraint violation, where $T$ is the total number of time steps. This strictly improves over the algorithm of (Singh et al., 2020), whose regret and constraint violation are both $\widetilde{O}(T^{2/3})$. Next, we consider the most general class of weakly communicating MDPs. Through a finite-horizon approximation, we develop another algorithm with $\widetilde{O}(T^{2/3})$ regret and constraint violation, which can be further improved to $\widetilde{O}(\sqrt{T})$ via a simple modification, albeit making the algorithm computationally inefficient. As far as we know, these are the first set of provable algorithms for weakly communicating MDPs with cost constraints.
Near-Optimal Regret for Adversarial MDP with Delayed Bandit Feedback
Jan 31, 2022The standard assumption in reinforcement learning (RL) is that agents observe feedback for their actions immediately. However, in practice feedback is often observed in delay. This paper studies online learning in episodic Markov decision process (MDP) with unknown transitions, adversarially changing costs, and unrestricted delayed bandit feedback. More precisely, the feedback for the agent in episode $k$ is revealed only in the end of episode $k + d^k$, where the delay $d^k$ can be changing over episodes and chosen by an oblivious adversary. We present the first algorithms that achieve near-optimal $\sqrt{K + D}$ regret, where $K$ is the number of episodes and $D = \sum_{k=1}^K d^k$ is the total delay, significantly improving upon the best known regret bound of $(K + D)^{2/3}$.
No-Regret Learning in Time-Varying Zero-Sum Games
Jan 30, 2022
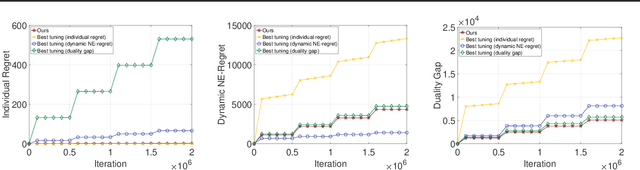
Learning from repeated play in a fixed two-player zero-sum game is a classic problem in game theory and online learning. We consider a variant of this problem where the game payoff matrix changes over time, possibly in an adversarial manner. We first present three performance measures to guide the algorithmic design for this problem: 1) the well-studied individual regret, 2) an extension of duality gap, and 3) a new measure called dynamic Nash Equilibrium regret, which quantifies the cumulative difference between the player's payoff and the minimax game value. Next, we develop a single parameter-free algorithm that simultaneously enjoys favorable guarantees under all these three performance measures. These guarantees are adaptive to different non-stationarity measures of the payoff matrices and, importantly, recover the best known results when the payoff matrix is fixed. Our algorithm is based on a two-layer structure with a meta-algorithm learning over a group of black-box base-learners satisfying a certain property, along with several novel ingredients specifically designed for the time-varying game setting. Empirical results further validate the effectiveness of our algorithm.
Improved No-Regret Algorithms for Stochastic Shortest Path with Linear MDP
Dec 18, 2021We introduce two new no-regret algorithms for the stochastic shortest path (SSP) problem with a linear MDP that significantly improve over the only existing results of (Vial et al., 2021). Our first algorithm is computationally efficient and achieves a regret bound $\widetilde{O}\left(\sqrt{d^3B_{\star}^2T_{\star} K}\right)$, where $d$ is the dimension of the feature space, $B_{\star}$ and $T_{\star}$ are upper bounds of the expected costs and hitting time of the optimal policy respectively, and $K$ is the number of episodes. The same algorithm with a slight modification also achieves logarithmic regret of order $O\left(\frac{d^3B_{\star}^4}{c_{\min}^2\text{gap}_{\min}}\ln^5\frac{dB_{\star} K}{c_{\min}} \right)$, where $\text{gap}_{\min}$ is the minimum sub-optimality gap and $c_{\min}$ is the minimum cost over all state-action pairs. Our result is obtained by developing a simpler and improved analysis for the finite-horizon approximation of (Cohen et al., 2021) with a smaller approximation error, which might be of independent interest. On the other hand, using variance-aware confidence sets in a global optimization problem, our second algorithm is computationally inefficient but achieves the first "horizon-free" regret bound $\widetilde{O}(d^{3.5}B_{\star}\sqrt{K})$ with no polynomial dependency on $T_{\star}$ or $1/c_{\min}$, almost matching the $\Omega(dB_{\star}\sqrt{K})$ lower bound from (Min et al., 2021).
Policy Optimization in Adversarial MDPs: Improved Exploration via Dilated Bonuses
Jul 18, 2021Policy optimization is a widely-used method in reinforcement learning. Due to its local-search nature, however, theoretical guarantees on global optimality often rely on extra assumptions on the Markov Decision Processes (MDPs) that bypass the challenge of global exploration. To eliminate the need of such assumptions, in this work, we develop a general solution that adds dilated bonuses to the policy update to facilitate global exploration. To showcase the power and generality of this technique, we apply it to several episodic MDP settings with adversarial losses and bandit feedback, improving and generalizing the state-of-the-art. Specifically, in the tabular case, we obtain $\widetilde{\mathcal{O}}(\sqrt{T})$ regret where $T$ is the number of episodes, improving the $\widetilde{\mathcal{O}}({T}^{2/3})$ regret bound by Shani et al. (2020). When the number of states is infinite, under the assumption that the state-action values are linear in some low-dimensional features, we obtain $\widetilde{\mathcal{O}}({T}^{2/3})$ regret with the help of a simulator, matching the result of Neu and Olkhovskaya (2020) while importantly removing the need of an exploratory policy that their algorithm requires. When a simulator is unavailable, we further consider a linear MDP setting and obtain $\widetilde{\mathcal{O}}({T}^{14/15})$ regret, which is the first result for linear MDPs with adversarial losses and bandit feedback.
Last-iterate Convergence in Extensive-Form Games
Jun 27, 2021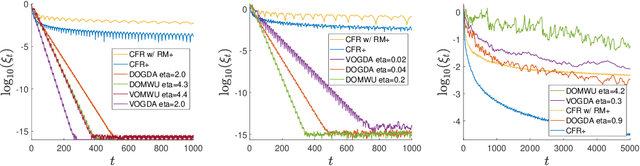
Regret-based algorithms are highly efficient at finding approximate Nash equilibria in sequential games such as poker games. However, most regret-based algorithms, including counterfactual regret minimization (CFR) and its variants, rely on iterate averaging to achieve convergence. Inspired by recent advances on last-iterate convergence of optimistic algorithms in zero-sum normal-form games, we study this phenomenon in sequential games, and provide a comprehensive study of last-iterate convergence for zero-sum extensive-form games with perfect recall (EFGs), using various optimistic regret-minimization algorithms over treeplexes. This includes algorithms using the vanilla entropy or squared Euclidean norm regularizers, as well as their dilated versions which admit more efficient implementation. In contrast to CFR, we show that all of these algorithms enjoy last-iterate convergence, with some of them even converging exponentially fast. We also provide experiments to further support our theoretical results.
Implicit Finite-Horizon Approximation and Efficient Optimal Algorithms for Stochastic Shortest Path
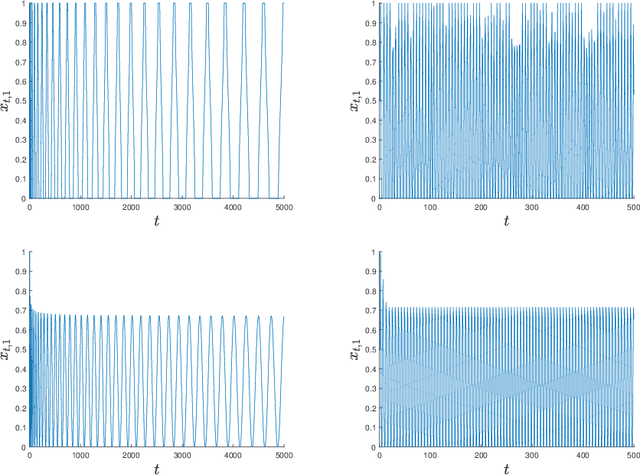
Jun 15, 2021
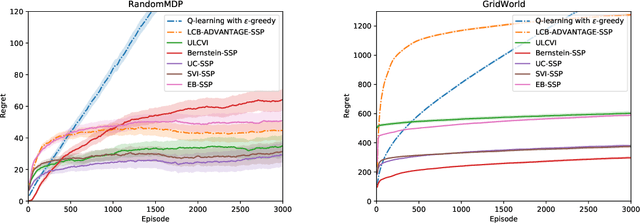
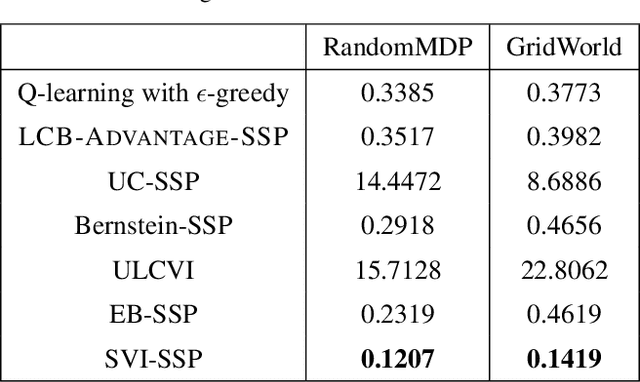
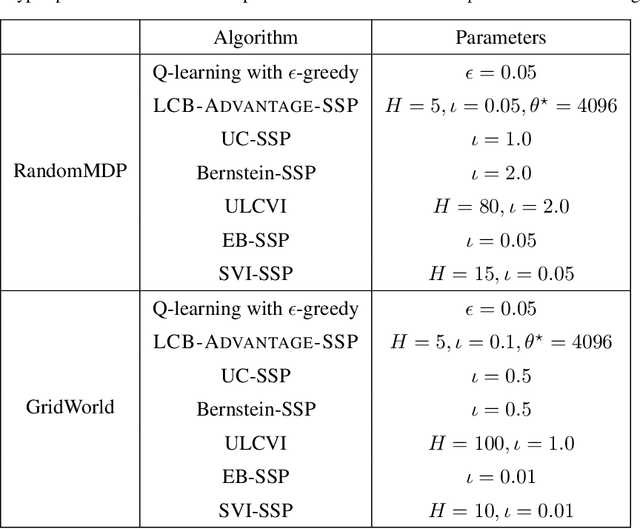
We introduce a generic template for developing regret minimization algorithms in the Stochastic Shortest Path (SSP) model, which achieves minimax optimal regret as long as certain properties are ensured. The key of our analysis is a new technique called implicit finite-horizon approximation, which approximates the SSP model by a finite-horizon counterpart only in the analysis without explicit implementation. Using this template, we develop two new algorithms: the first one is model-free (the first in the literature to our knowledge) and minimax optimal under strictly positive costs; the second one is model-based and minimax optimal even with zero-cost state-action pairs, matching the best existing result from [Tarbouriech et al., 2021b]. Importantly, both algorithms admit highly sparse updates, making them computationally more efficient than all existing algorithms. Moreover, both can be made completely parameter-free.
Online Learning for Stochastic Shortest Path Model via Posterior Sampling
Jun 09, 2021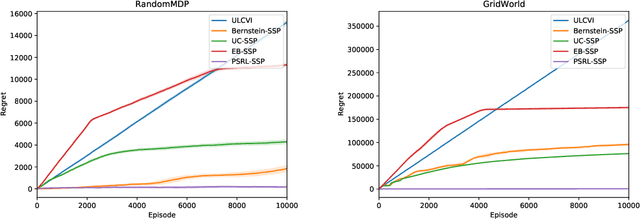
We consider the problem of online reinforcement learning for the Stochastic Shortest Path (SSP) problem modeled as an unknown MDP with an absorbing state. We propose PSRL-SSP, a simple posterior sampling-based reinforcement learning algorithm for the SSP problem. The algorithm operates in epochs. At the beginning of each epoch, a sample is drawn from the posterior distribution on the unknown model dynamics, and the optimal policy with respect to the drawn sample is followed during that epoch. An epoch completes if either the number of visits to the goal state in the current epoch exceeds that of the previous epoch, or the number of visits to any of the state-action pairs is doubled. We establish a Bayesian regret bound of $O(B_\star S\sqrt{AK})$, where $B_\star$ is an upper bound on the expected cost of the optimal policy, $S$ is the size of the state space, $A$ is the size of the action space, and $K$ is the number of episodes. The algorithm only requires the knowledge of the prior distribution, and has no hyper-parameters to tune. It is the first such posterior sampling algorithm and outperforms numerically previously proposed optimism-based algorithms.