 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating High Energy Physics Data Analysis with LLM-Powered Agents
Dec 08, 2025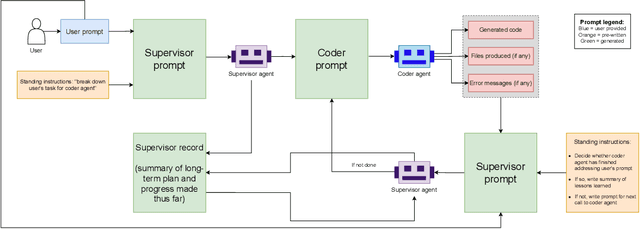
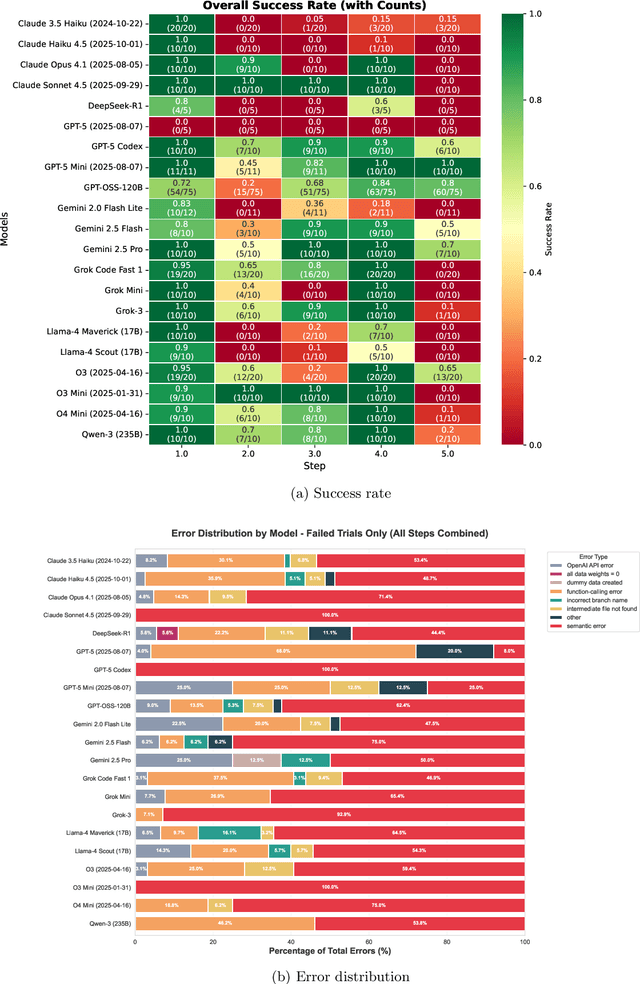
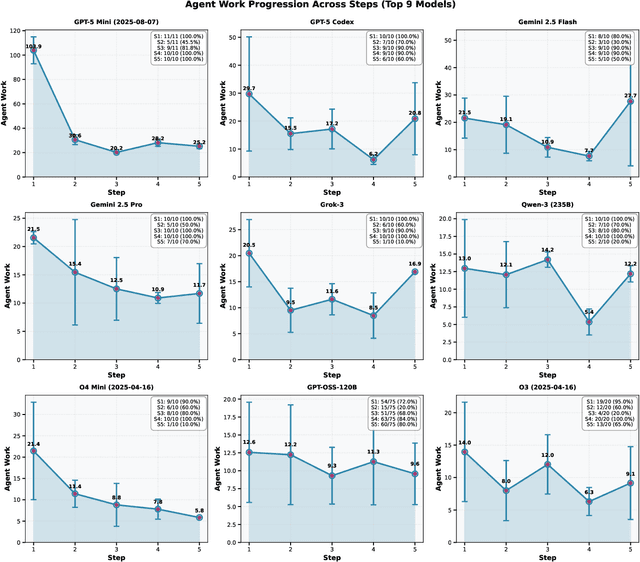
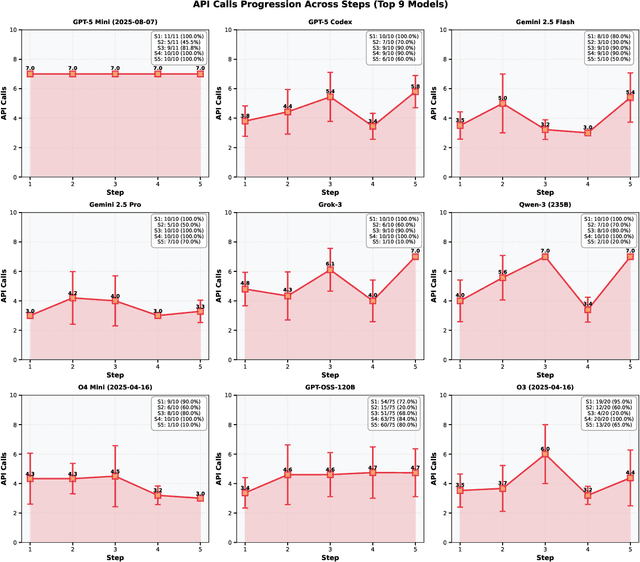
We present a proof-of-principle study demonstrating the use of large language model (LLM) agents to automate a representative high energy physics (HEP) analysis. Using the Higgs boson diphoton cross-section measurement as a case study with ATLAS Open Data, we design a hybrid system that combines an LLM-based supervisor-coder agent with the Snakemake workflow manager. In this architecture, the workflow manager enforces reproducibility and determinism, while the agent autonomously generates, executes, and iteratively corrects analysis code in response to user instructions. We define quantitative evaluation metrics including success rate, error distribution, costs per specific task, and average number of API calls, to assess agent performance across multi-stage workflows. To characterize variability across architectures, we benchmark a representative selection of state-of-the-art LLMs spanning the Gemini and GPT-5 series, the Claude family, and leading open-weight models. While the workflow manager ensures deterministic execution of all analysis steps, the final outputs still show stochastic variation. Although we set the temperature to zero, other sampling parameters (e.g., top-p, top-k) remained at their defaults, and some reasoning-oriented models internally adjust these settings. Consequently, the models do not produce fully deterministic results. This study establishes the first LLM-agent-driven automated data-analysis framework in HEP, enabling systematic benchmarking of model capabilities, stability, and limitations in real-world scientific computing environments. The baseline code used in this work is available at https://huggingface.co/HWresearch/LLM4HEP. This work was accepted as a poster at the Machine Learning and the Physical Sciences (ML4PS) workshop at NeurIPS 2025. The initial submission was made on August 30, 2025.
Pretrained Event Classification Model for High Energy Physics Analysis
Dec 14, 2024



We introduce a foundation model for event classification in high-energy physics, built on a Graph Neural Network architecture and trained on 120 million simulated proton-proton collision events spanning 12 distinct physics processes. The model is pretrained to learn a general and robust representation of collision data using challenging multiclass and multilabel classification tasks. Its performance is evaluated across five event classification tasks, which include both physics processes used during pretraining and new processes not encountered during pretraining. Fine-tuning the pretrained model significantly improves classification performance, particularly in scenarios with limited training data, demonstrating gains in both accuracy and computational efficiency. To investigate the underlying mechanisms behind these performance improvements, we employ a representational similarity evaluation framework based on Centered Kernel Alignment. This analysis reveals notable differences in the learned representations of fine-tuned pretrained models compared to baseline models trained from scratch.
Reconstruction of Differentially Private Text Sanitization via Large Language Models
Oct 16, 2024



Differential privacy (DP) is the de facto privacy standard against privacy leakage attacks, including many recently discovered ones against large language models (LLMs). However, we discovered that LLMs could reconstruct the altered/removed privacy from given DP-sanitized prompts. We propose two attacks (black-box and white-box) based on the accessibility to LLMs and show that LLMs could connect the pair of DP-sanitized text and the corresponding private training data of LLMs by giving sample text pairs as instructions (in the black-box attacks) or fine-tuning data (in the white-box attacks). To illustrate our findings, we conduct comprehensive experiments on modern LLMs (e.g., LLaMA-2, LLaMA-3, ChatGPT-3.5, ChatGPT-4, ChatGPT-4o, Claude-3, Claude-3.5, OPT, GPT-Neo, GPT-J, Gemma-2, and Pythia) using commonly used datasets (such as WikiMIA, Pile-CC, and Pile-Wiki) against both word-level and sentence-level DP. The experimental results show promising recovery rates, e.g., the black-box attacks against the word-level DP over WikiMIA dataset gave 72.18% on LLaMA-2 (70B), 82.39% on LLaMA-3 (70B), 75.35% on Gemma-2, 91.2% on ChatGPT-4o, and 94.01% on Claude-3.5 (Sonnet). More urgently, this study indicates that these well-known LLMs have emerged as a new security risk for existing DP text sanitization approaches in the current environment.
Machine Learning guided high-throughput search of non-oxide garnets
Aug 29, 2022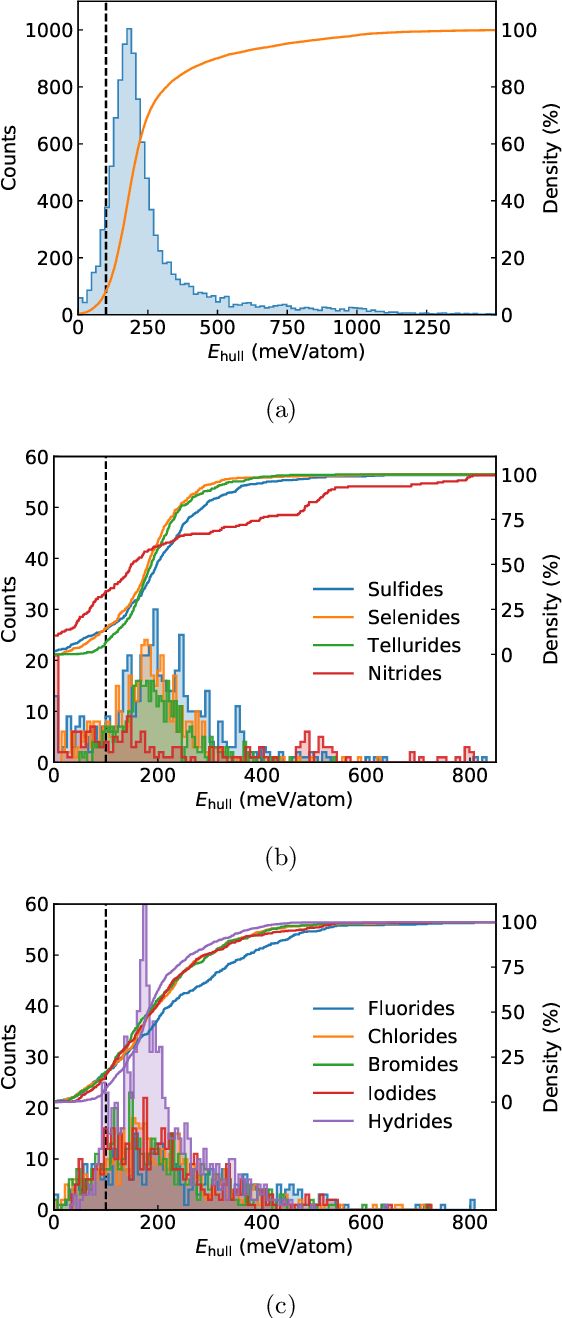
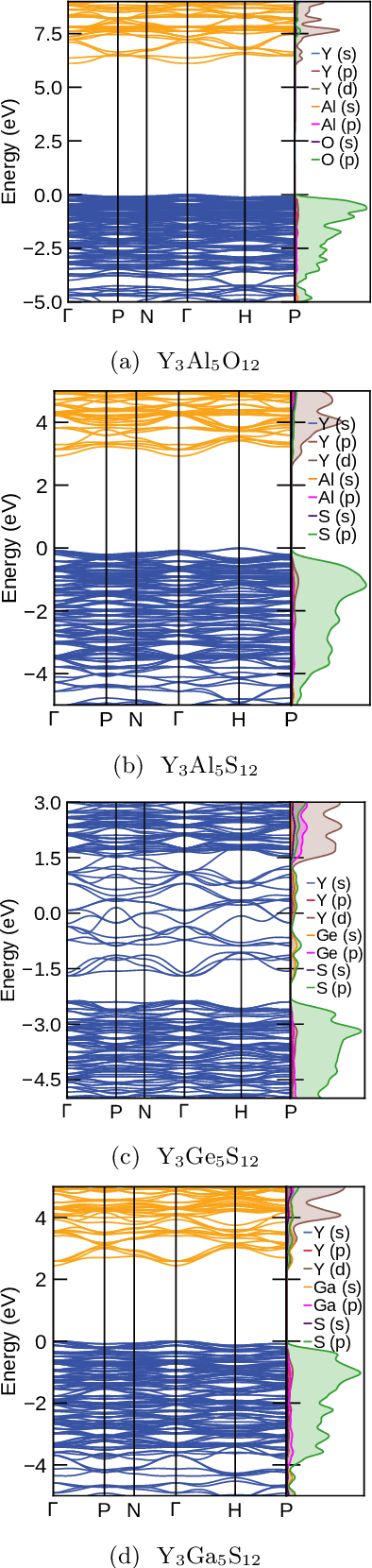
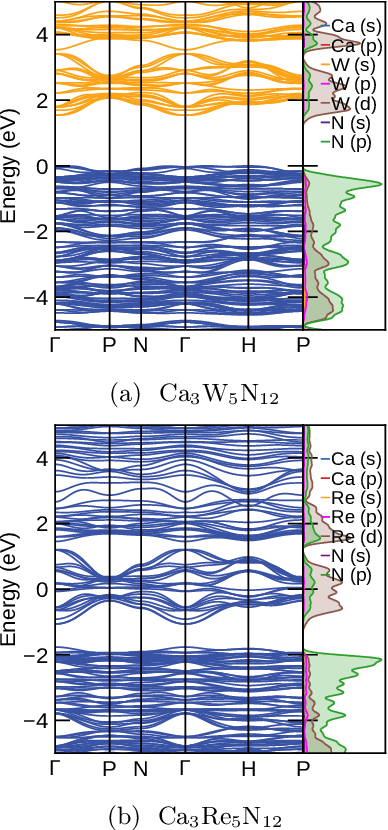
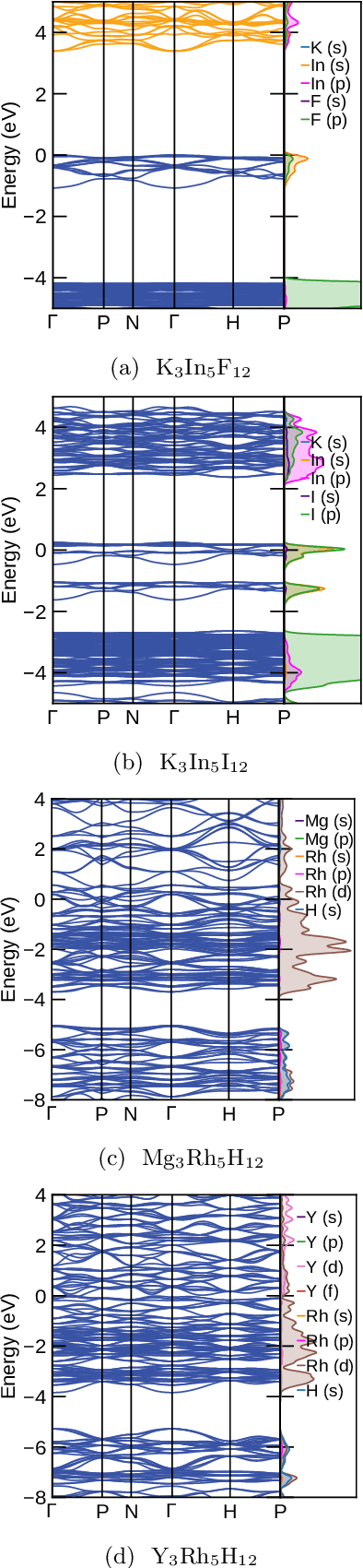
Garnets, known since the early stages of human civilization, have found important applications in modern technologies including magnetorestriction, spintronics, lithium batteries, etc. The overwhelming majority of experimentally known garnets are oxides, while explorations (experimental or theoretical) for the rest of the chemical space have been limited in scope. A key issue is that the garnet structure has a large primitive unit cell, requiring an enormous amount of computational resources. To perform a comprehensive search of the complete chemical space for new garnets,we combine recent progress in graph neural networks with high-throughput calculations. We apply the machine learning model to identify the potential (meta-)stable garnet systems before systematic density-functional calculations to validate the predictions. In this way, we discover more than 600 ternary garnets with distances to the convex hull below 100~meV/atom with a variety of physical and chemical properties. This includes sulfide, nitride and halide garnets. For these, we analyze the electronic structure and discuss the connection between the value of the electronic band gap and charge balance.