 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressing beyond Art Masterpieces or Touristic Clichés: how to assess your LLMs for cultural alignment?
Apr 28, 2026Although the cultural (mis)alignment of Large Language Models (LLMs) has attracted increasing attention -- often framed in terms of cultural bias -- until recently there has been limited work on the design and development of datasets for cultural assessment. Here, we review existing approaches to such datasets and identify their main limitations. To address these issues, we propose design guidelines for annotators and report on the construction of a dataset built according to these principles. We further present a series of contrastive experiments conducted with this dataset. The results demonstrate that our design yields test sets with greater discriminative power, effectively distinguishing between models specialized for a given culture and those that are not, ceteris paribus.
CitiLink-Summ: Summarization of Discussion Subjects in European Portuguese Municipal Meeting Minutes
Feb 18, 2026Municipal meeting minutes are formal records documenting the discussions and decisions of local government, yet their content is often lengthy, dense, and difficult for citizens to navigate. Automatic summarization can help address this challenge by producing concise summaries for each discussion subject. Despite its potential, research on summarizing discussion subjects in municipal meeting minutes remains largely unexplored, especially in low-resource languages, where the inherent complexity of these documents adds further challenges. A major bottleneck is the scarcity of datasets containing high-quality, manually crafted summaries, which limits the development and evaluation of effective summarization models for this domain. In this paper, we present CitiLink-Summ, a new corpus of European Portuguese municipal meeting minutes, comprising 100 documents and 2,322 manually hand-written summaries, each corresponding to a distinct discussion subject. Leveraging this dataset, we establish baseline results for automatic summarization in this domain, employing state-of-the-art generative models (e.g., BART, PRIMERA) as well as large language models (LLMs), evaluated with both lexical and semantic metrics such as ROUGE, BLEU, METEOR, and BERTScore. CitiLink-Summ provides the first benchmark for municipal-domain summarization in European Portuguese, offering a valuable resource for advancing NLP research on complex administrative texts.
CitiLink-Minutes: A Multilayer Annotated Dataset of Municipal Meeting Minutes
Feb 12, 2026City councils play a crucial role in local governance, directly influencing citizens' daily lives through decisions made during municipal meetings. These deliberations are formally documented in meeting minutes, which serve as official records of discussions, decisions, and voting outcomes. Despite their importance, municipal meeting records have received little attention in Information Retrieval (IR) and Natural Language Processing (NLP), largely due to the lack of annotated datasets, which ultimately limit the development of computational models. To address this gap, we introduce CitiLink-Minutes, a multilayer dataset of 120 European Portuguese municipal meeting minutes from six municipalities. Unlike prior annotated datasets of parliamentary or video records, CitiLink-Minutes provides multilayer annotations and structured linkage of official written minutes. The dataset contains over one million tokens, with all personal identifiers de-identified. Each minute was manually annotated by two trained annotators and curated by an experienced linguist across three complementary dimensions: (1) metadata, (2) subjects of discussion, and (3) voting outcomes, totaling over 38,000 individual annotations. Released under FAIR principles and accompanied by baseline results on metadata extraction, topic classification, and vote labeling, CitiLink-Minutes demonstrates its potential for downstream NLP and IR tasks, while promoting transparent access to municipal decisions.
NLP for Local Governance Meeting Records: A Focus Article on Tasks, Datasets, Metrics and Benchmark
Feb 08, 2026Local governance meeting records are official documents, in the form of minutes or transcripts, documenting how proposals, discussions, and procedural actions unfold during institutional meetings. While generally structured, these documents are often dense, bureaucratic, and highly heterogeneous across municipalities, exhibiting significant variation in language, terminology, structure, and overall organization. This heterogeneity makes them difficult for non-experts to interpret and challenging for intelligent automated systems to process, limiting public transparency and civic engagement. To address these challenges, computational methods can be employed to structure and interpret such complex documents. In particular, Natural Language Processing (NLP) offers well-established methods that can enhance the accessibility and interpretability of governmental records. In this focus article, we review foundational NLP tasks that support the structuring of local governance meeting documents. Specifically, we review three core tasks: document segmentation, domain-specific entity extraction and automatic text summarization, which are essential for navigating lengthy deliberations, identifying political actors and personal information, and generating concise representations of complex decision-making processes. In reviewing these tasks, we discuss methodological approaches, evaluation metrics, and publicly available resources, while highlighting domain-specific challenges such as data scarcity, privacy constraints, and source variability. By synthesizing existing work across these foundational tasks, this article provides a structured overview of how NLP can enhance the structuring and accessibility of local governance meeting records.
CitiLink: Enhancing Municipal Transparency and Citizen Engagement through Searchable Meeting Minutes
Jan 26, 2026City council minutes are typically lengthy and formal documents with a bureaucratic writing style. Although publicly available, their structure often makes it difficult for citizens or journalists to efficiently find information. In this demo, we present CitiLink, a platform designed to transform unstructured municipal meeting minutes into structured and searchable data, demonstrating how NLP and IR can enhance the accessibility and transparency of local government. The system employs LLMs to extract metadata, discussed subjects, and voting outcomes, which are then indexed in a database to support full-text search with BM25 ranking and faceted filtering through a user-friendly interface. The developed system was built over a collection of 120 minutes made available by six Portuguese municipalities. To assess its usability, CitiLink was tested through guided sessions with municipal personnel, providing insights into how real users interact with the system. In addition, we evaluated Gemini's performance in extracting relevant information from the minutes, highlighting its effectiveness in data extraction.
Machine Learning guided high-throughput search of non-oxide garnets
Aug 29, 2022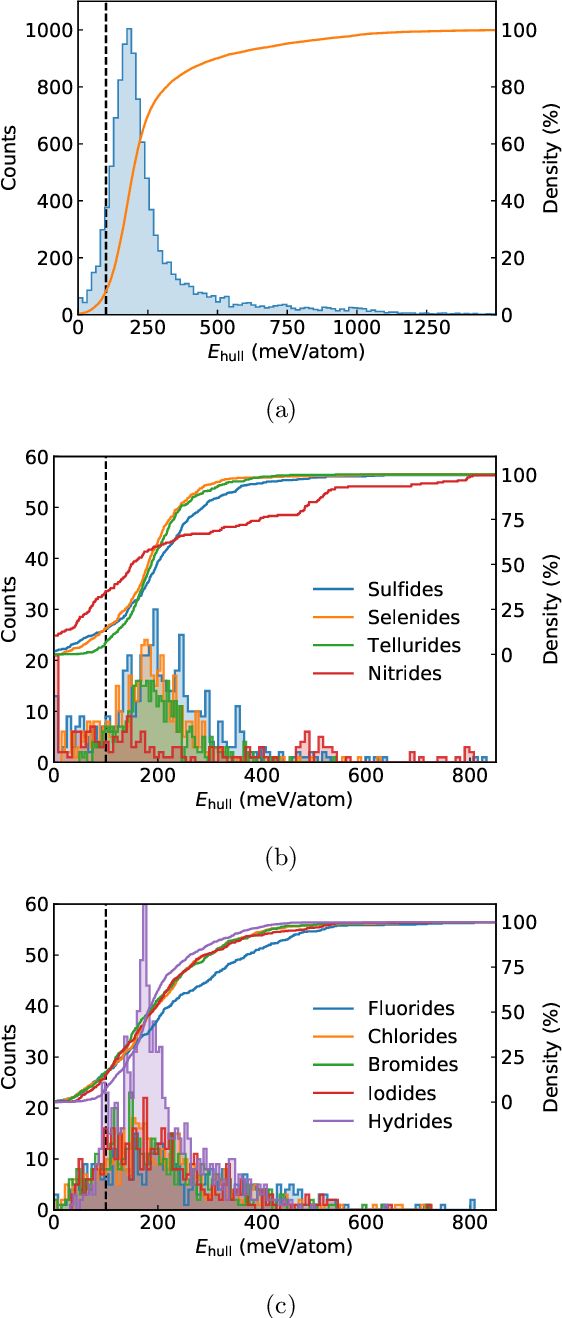
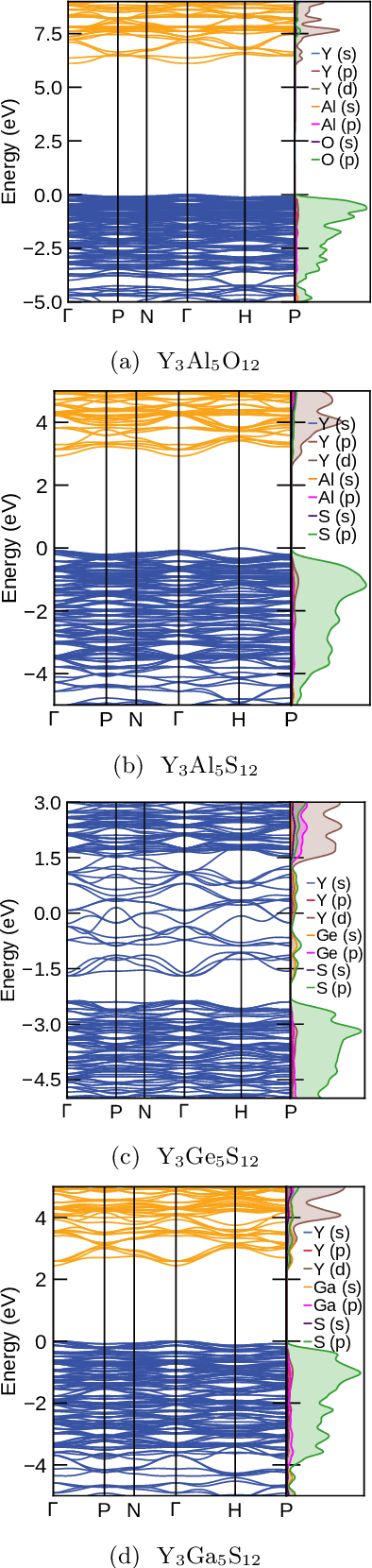
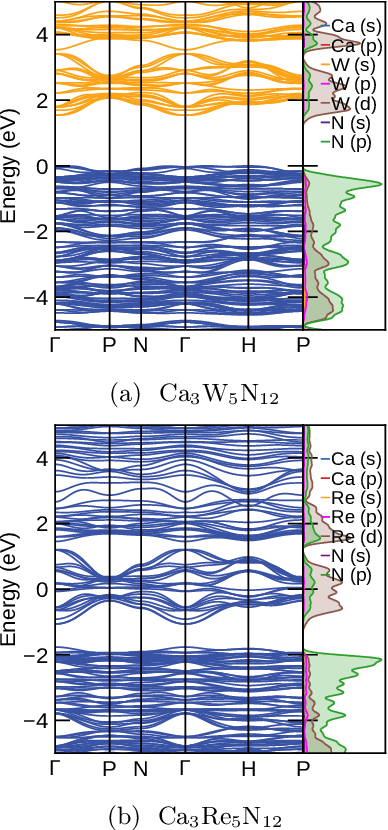
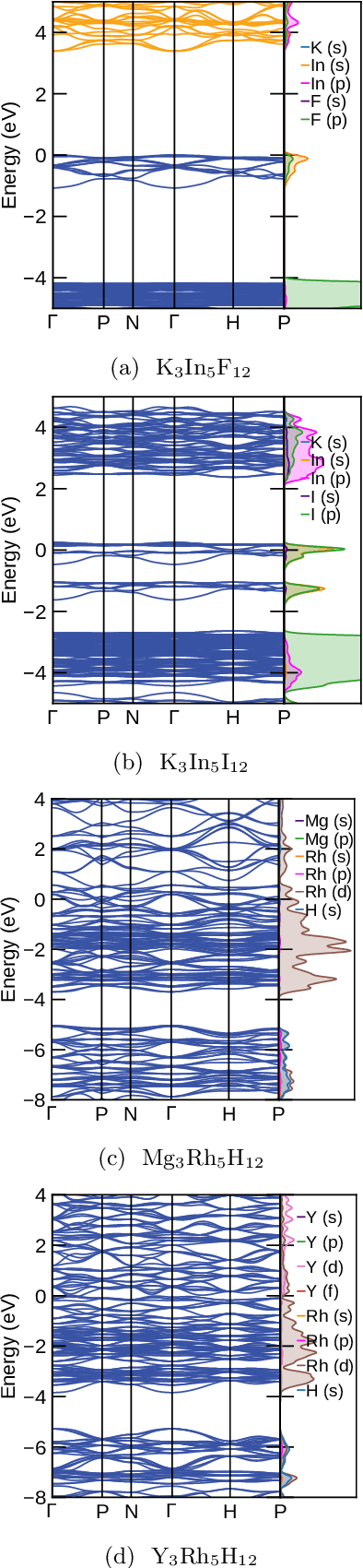
Garnets, known since the early stages of human civilization, have found important applications in modern technologies including magnetorestriction, spintronics, lithium batteries, etc. The overwhelming majority of experimentally known garnets are oxides, while explorations (experimental or theoretical) for the rest of the chemical space have been limited in scope. A key issue is that the garnet structure has a large primitive unit cell, requiring an enormous amount of computational resources. To perform a comprehensive search of the complete chemical space for new garnets,we combine recent progress in graph neural networks with high-throughput calculations. We apply the machine learning model to identify the potential (meta-)stable garnet systems before systematic density-functional calculations to validate the predictions. In this way, we discover more than 600 ternary garnets with distances to the convex hull below 100~meV/atom with a variety of physical and chemical properties. This includes sulfide, nitride and halide garnets. For these, we analyze the electronic structure and discuss the connection between the value of the electronic band gap and charge balance.