 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSell More, Play Less: Benchmarking LLM Realistic Selling Skill
Apr 09, 2026Sales dialogues require multi-turn, goal-directed persuasion under asymmetric incentives, which makes them a challenging setting for large language models (LLMs). Yet existing dialogue benchmarks rarely measure deal progression and outcomes. We introduce SalesLLM benchmark, a bilingual (ZH/EN) benchmark derived from realistic applications covering Financial Services and Consumer Goods, built from 30,074 scripted configurations and 1,805 curated multi-turn scenarios with controllable difficulty and personas. We propose a fully automatic evaluation pipeline that combines (i) an LLM-based rater for sales-process progress,and (ii) fine-tuned BERT classifiers for end-of-dialogue buying intent. To improve simulation fidelity, we train a user model, CustomerLM, with SFT and DPO on 8,000+ crowdworker-involved sales conversations, reducing role inversion from 17.44% (GPT-4o) to 8.8%. SalesLLM benchmark scores correlate strongly with expert human ratings (Pearson r=0.98). Experiments across 15 mainstream LLMs reveal substantial variability: top-performance LLMs are competitive with human-level performance while the less capable ones are worse than human. SalesLLM benchmark serves as a scalable benchmark for developing and evaluating outcome-oriented sales agents.
Where to Look and How to Describe: Fashion Image Retrieval with an Attentional Heterogeneous Bilinear Network
Oct 26, 2020
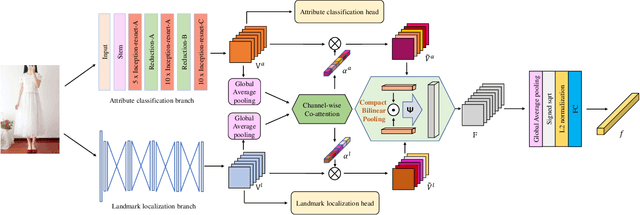
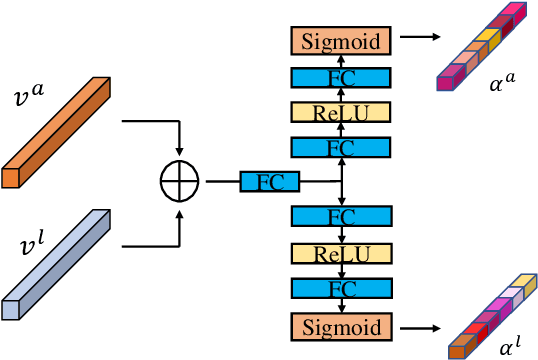
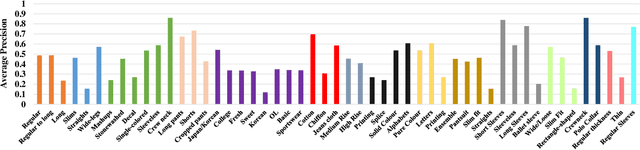
Fashion products typically feature in compositions of a variety of styles at different clothing parts. In order to distinguish images of different fashion products, we need to extract both appearance (i.e., "how to describe") and localization (i.e.,"where to look") information, and their interactions. To this end, we propose a biologically inspired framework for image-based fashion product retrieval, which mimics the hypothesized twostream visual processing system of human brain. The proposed attentional heterogeneous bilinear network (AHBN) consists of two branches: a deep CNN branch to extract fine-grained appearance attributes and a fully convolutional branch to extract landmark localization information. A joint channel-wise attention mechanism is further applied to the extracted heterogeneous features to focus on important channels, followed by a compact bilinear pooling layer to model the interaction of the two streams. Our proposed framework achieves satisfactory performance on three image-based fashion product retrieval benchmarks.
To Tune or Not To Tune? How About the Best of Both Worlds?
Jul 09, 2019
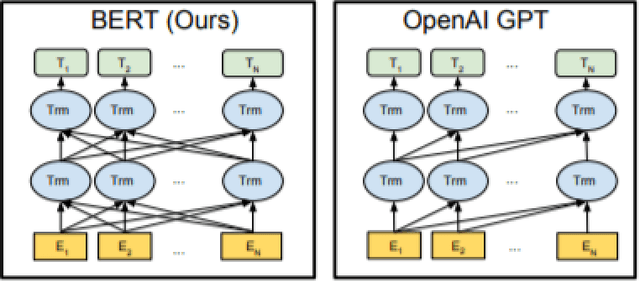


The introduction of pre-trained language models has revolutionized natural language research communities. However, researchers still know relatively little regarding their theoretical and empirical properties. In this regard, Peters et al. perform several experiments which demonstrate that it is better to adapt BERT with a light-weight task-specific head, rather than building a complex one on top of the pre-trained language model, and freeze the parameters in the said language model. However, there is another option to adopt. In this paper, we propose a new adaptation method which we first train the task model with the BERT parameters frozen and then fine-tune the entire model together. Our experimental results show that our model adaptation method can achieve 4.7% accuracy improvement in semantic similarity task, 0.99% accuracy improvement in sequence labeling task and 0.72% accuracy improvement in the text classification task.