 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing Dialogue States for Open Conversational Machine Reading
Sep 02, 2021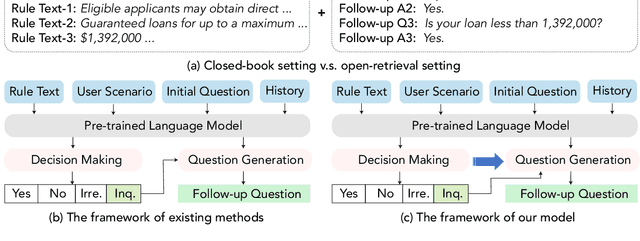
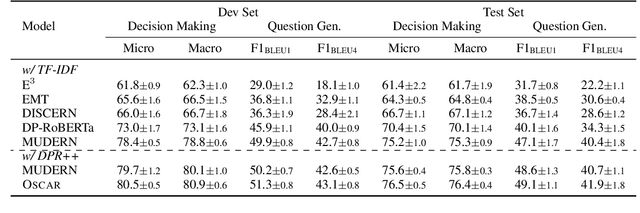
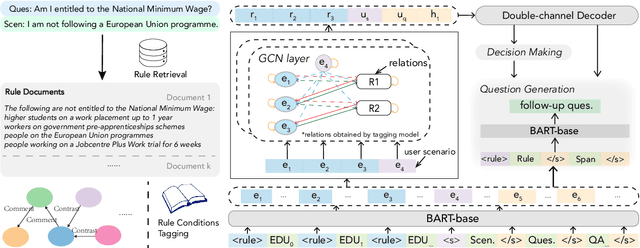
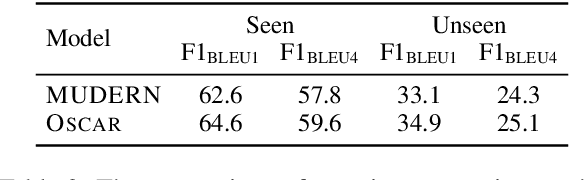
Conversational machine reading (CMR) requires machines to communicate with humans through multi-turn interactions between two salient dialogue states of decision making and question generation processes. In open CMR settings, as the more realistic scenario, the retrieved background knowledge would be noisy, which results in severe challenges in the information transmission. Existing studies commonly train independent or pipeline systems for the two subtasks. However, those methods are trivial by using hard-label decisions to activate question generation, which eventually hinders the model performance. In this work, we propose an effective gating strategy by smoothing the two dialogue states in only one decoder and bridge decision making and question generation to provide a richer dialogue state reference. Experiments on the OR-ShARC dataset show the effectiveness of our method, which achieves new state-of-the-art results.
Unsupervised Open-Domain Question Answering
Aug 31, 2021
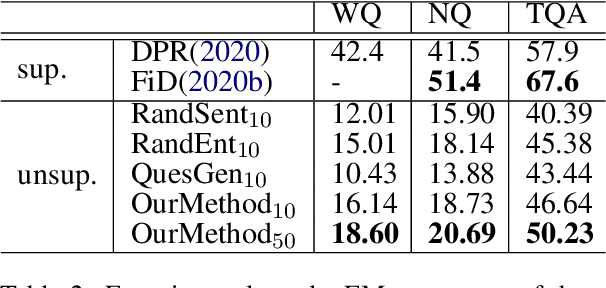

Open-domain Question Answering (ODQA) has achieved significant results in terms of supervised learning manner. However, data annotation cannot also be irresistible for its huge demand in an open domain. Though unsupervised QA or unsupervised Machine Reading Comprehension (MRC) has been tried more or less, unsupervised ODQA has not been touched according to our best knowledge. This paper thus pioneers the work of unsupervised ODQA by formally introducing the task and proposing a series of key data construction methods. Our exploration in this work inspiringly shows unsupervised ODQA can reach up to 86% performance of supervised ones.
Span Fine-tuning for Pre-trained Language Models
Aug 29, 2021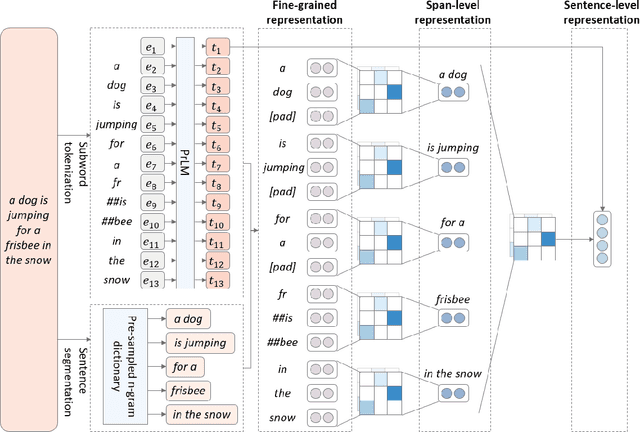
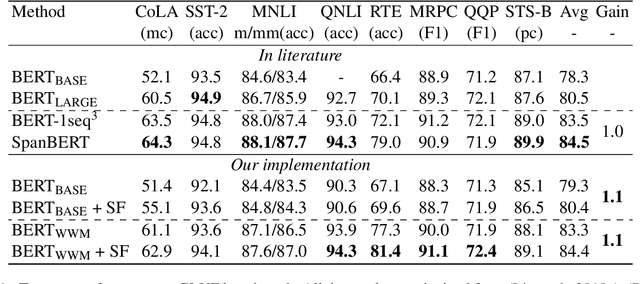

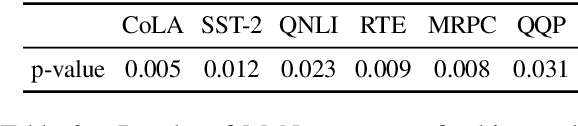
Pre-trained language models (PrLM) have to carefully manage input units when training on a very large text with a vocabulary consisting of millions of words. Previous works have shown that incorporating span-level information over consecutive words in pre-training could further improve the performance of PrLMs. However, given that span-level clues are introduced and fixed in pre-training, previous methods are time-consuming and lack of flexibility. To alleviate the inconvenience, this paper presents a novel span fine-tuning method for PrLMs, which facilitates the span setting to be adaptively determined by specific downstream tasks during the fine-tuning phase. In detail, any sentences processed by the PrLM will be segmented into multiple spans according to a pre-sampled dictionary. Then the segmentation information will be sent through a hierarchical CNN module together with the representation outputs of the PrLM and ultimately generate a span-enhanced representation. Experiments on GLUE benchmark show that the proposed span fine-tuning method significantly enhances the PrLM, and at the same time, offer more flexibility in an efficient way.
Cross-lingual Transferring of Pre-trained Contextualized Language Models
Jul 27, 2021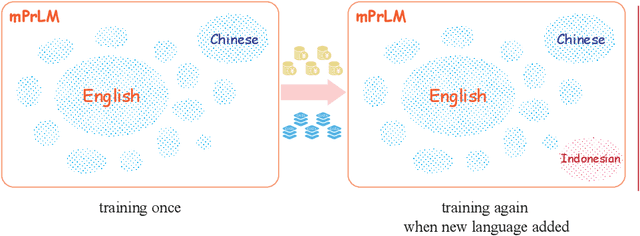
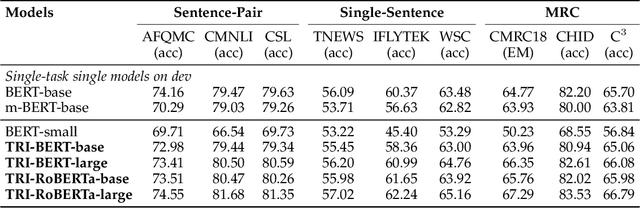
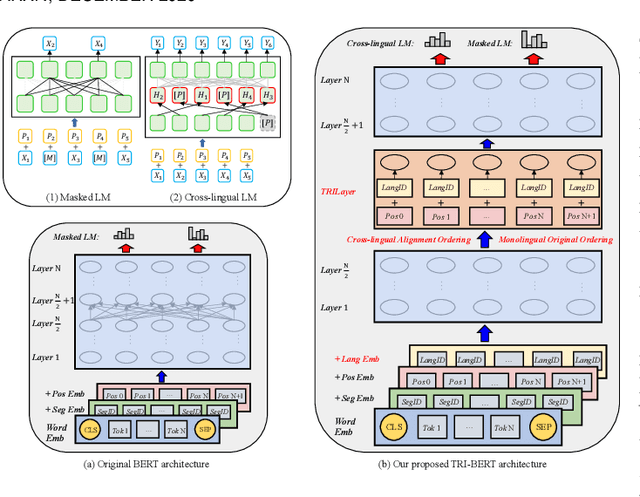
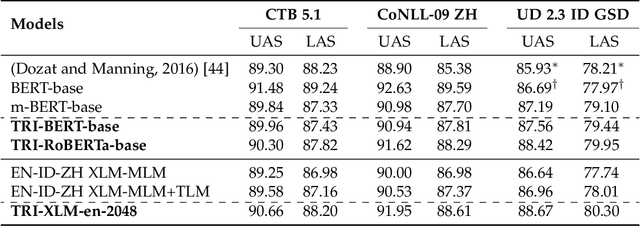
Though the pre-trained contextualized language model (PrLM) has made a significant impact on NLP, training PrLMs in languages other than English can be impractical for two reasons: other languages often lack corpora sufficient for training powerful PrLMs, and because of the commonalities among human languages, computationally expensive PrLM training for different languages is somewhat redundant. In this work, building upon the recent works connecting cross-lingual model transferring and neural machine translation, we thus propose a novel cross-lingual model transferring framework for PrLMs: TreLM. To handle the symbol order and sequence length differences between languages, we propose an intermediate ``TRILayer" structure that learns from these differences and creates a better transfer in our primary translation direction, as well as a new cross-lingual language modeling objective for transfer training. Additionally, we showcase an embedding aligning that adversarially adapts a PrLM's non-contextualized embedding space and the TRILayer structure to learn a text transformation network across languages, which addresses the vocabulary difference between languages. Experiments on both language understanding and structure parsing tasks show the proposed framework significantly outperforms language models trained from scratch with limited data in both performance and efficiency. Moreover, despite an insignificant performance loss compared to pre-training from scratch in resource-rich scenarios, our cross-lingual model transferring framework is significantly more economical.
Graph-free Multi-hop Reading Comprehension: A Select-to-Guide Strategy
Jul 25, 2021
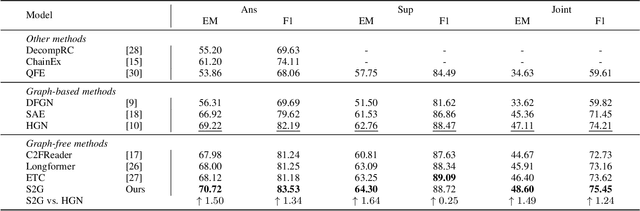
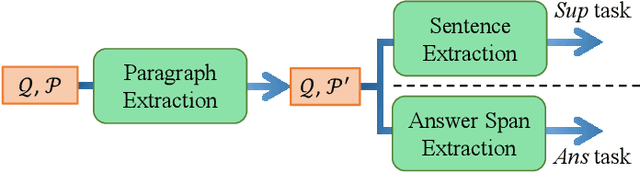
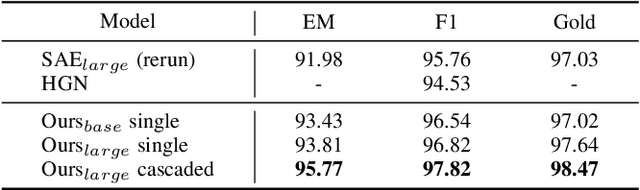
Multi-hop reading comprehension (MHRC) requires not only to predict the correct answer span in the given passage, but also to provide a chain of supporting evidences for reasoning interpretability. It is natural to model such a process into graph structure by understanding multi-hop reasoning as jumping over entity nodes, which has made graph modelling dominant on this task. Recently, there have been dissenting voices about whether graph modelling is indispensable due to the inconvenience of the graph building, however existing state-of-the-art graph-free attempts suffer from huge performance gap compared to graph-based ones. This work presents a novel graph-free alternative which firstly outperform all graph models on MHRC. In detail, we exploit a select-to-guide (S2G) strategy to accurately retrieve evidence paragraphs in a coarse-to-fine manner, incorporated with two novel attention mechanisms, which surprisingly shows conforming to the nature of multi-hop reasoning. Our graph-free model achieves significant and consistent performance gain over strong baselines and the current new state-of-the-art on the MHRC benchmark, HotpotQA, among all the published works.
Dialogue-oriented Pre-training
Jun 01, 2021
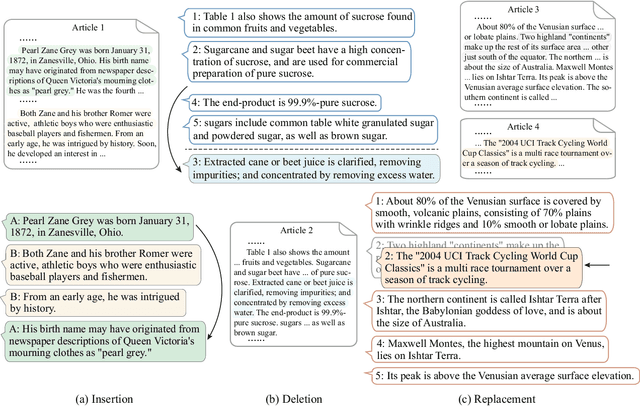
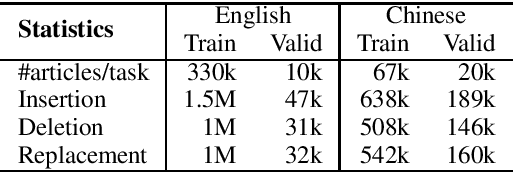
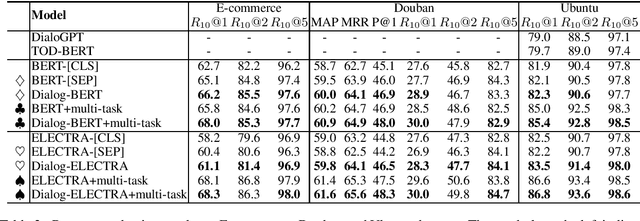
Pre-trained language models (PrLM) has been shown powerful in enhancing a broad range of downstream tasks including various dialogue related ones. However, PrLMs are usually trained on general plain text with common language model (LM) training objectives, which cannot sufficiently capture dialogue exclusive features due to the limitation of such training setting, so that there is an immediate need to fill the gap between a specific dialogue task and the LM task. As it is unlikely to collect huge dialogue data for dialogue-oriented pre-training, in this paper, we propose three strategies to simulate the conversation features on general plain text. Our proposed method differs from existing post-training methods that it may yield a general-purpose PrLM and does not individualize to any detailed task while keeping the capability of learning dialogue related features including speaker awareness, continuity and consistency. The resulted Dialog-PrLM is fine-tuned on three public multi-turn dialogue datasets and helps achieve significant and consistent improvement over the plain PrLMs.
Defending Pre-trained Language Models from Adversarial Word Substitutions Without Performance Sacrifice
May 30, 2021
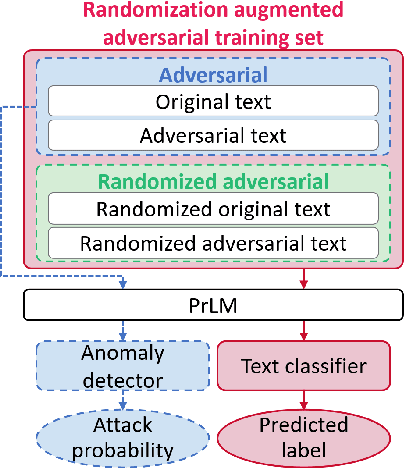
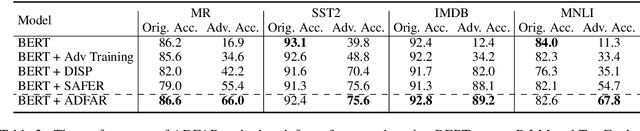
Pre-trained contextualized language models (PrLMs) have led to strong performance gains in downstream natural language understanding tasks. However, PrLMs can still be easily fooled by adversarial word substitution, which is one of the most challenging textual adversarial attack methods. Existing defence approaches suffer from notable performance loss and complexities. Thus, this paper presents a compact and performance-preserved framework, Anomaly Detection with Frequency-Aware Randomization (ADFAR). In detail, we design an auxiliary anomaly detection classifier and adopt a multi-task learning procedure, by which PrLMs are able to distinguish adversarial input samples. Then, in order to defend adversarial word substitution, a frequency-aware randomization process is applied to those recognized adversarial input samples. Empirical results show that ADFAR significantly outperforms those newly proposed defense methods over various tasks with much higher inference speed. Remarkably, ADFAR does not impair the overall performance of PrLMs. The code is available at https://github.com/LilyNLP/ADFAR
Pre-training Universal Language Representation
May 30, 2021
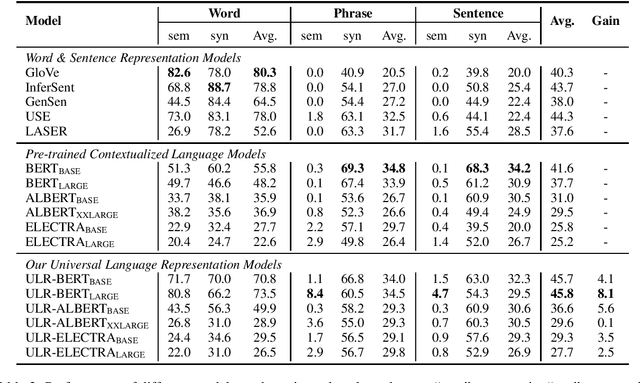
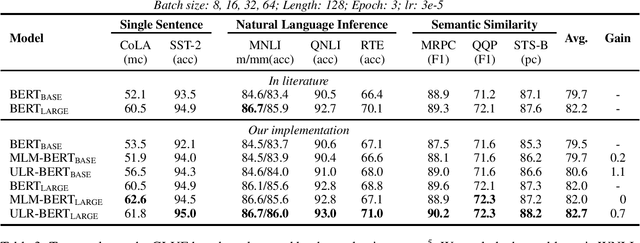
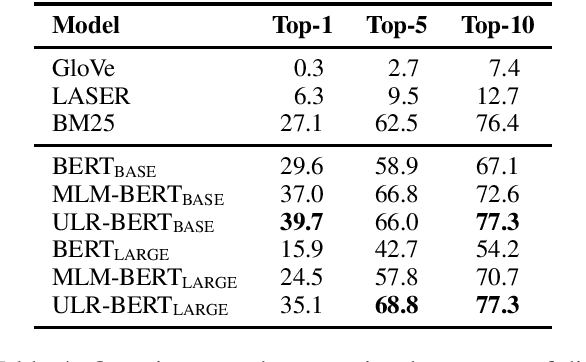
Despite the well-developed cut-edge representation learning for language, most language representation models usually focus on specific levels of linguistic units. This work introduces universal language representation learning, i.e., embeddings of different levels of linguistic units or text with quite diverse lengths in a uniform vector space. We propose the training objective MiSAD that utilizes meaningful n-grams extracted from large unlabeled corpus by a simple but effective algorithm for pre-trained language models. Then we empirically verify that well designed pre-training scheme may effectively yield universal language representation, which will bring great convenience when handling multiple layers of linguistic objects in a unified way. Especially, our model achieves the highest accuracy on analogy tasks in different language levels and significantly improves the performance on downstream tasks in the GLUE benchmark and a question answering dataset.
Grammatical Error Correction as GAN-like Sequence Labeling
May 29, 2021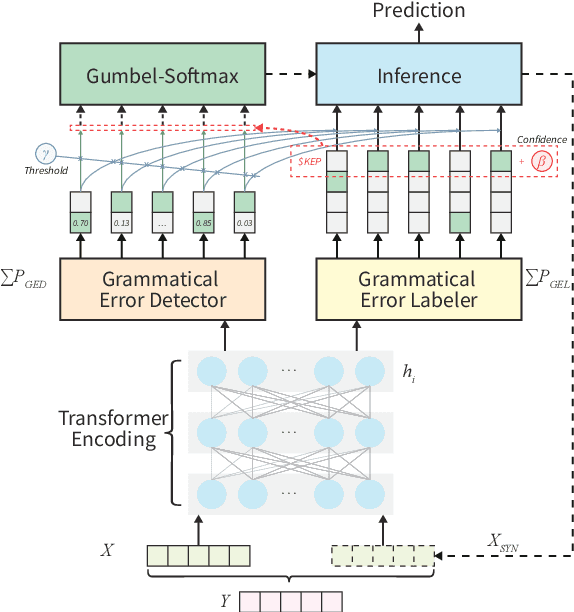
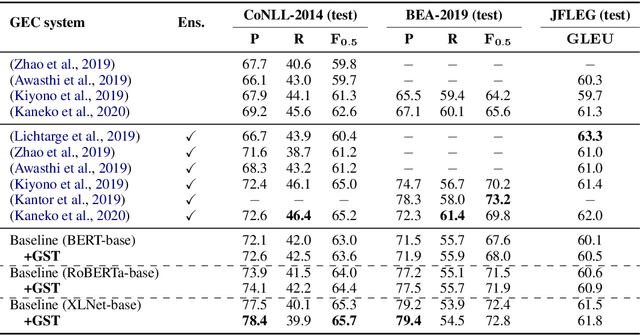
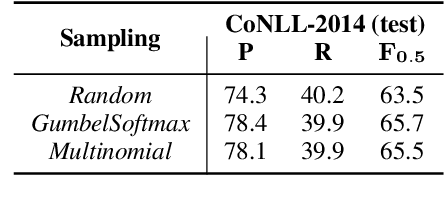
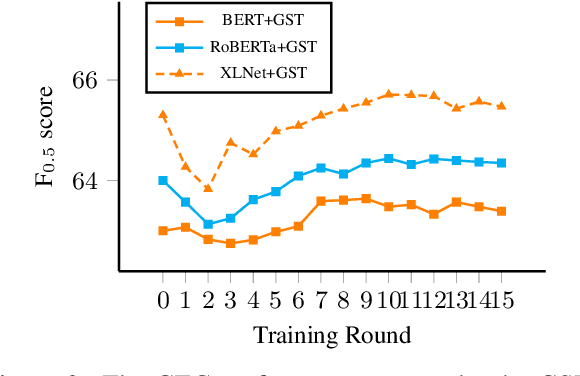
In Grammatical Error Correction (GEC), sequence labeling models enjoy fast inference compared to sequence-to-sequence models; however, inference in sequence labeling GEC models is an iterative process, as sentences are passed to the model for multiple rounds of correction, which exposes the model to sentences with progressively fewer errors at each round. Traditional GEC models learn from sentences with fixed error rates. Coupling this with the iterative correction process causes a mismatch between training and inference that affects final performance. In order to address this mismatch, we propose a GAN-like sequence labeling model, which consists of a grammatical error detector as a discriminator and a grammatical error labeler with Gumbel-Softmax sampling as a generator. By sampling from real error distributions, our errors are more genuine compared to traditional synthesized GEC errors, thus alleviating the aforementioned mismatch and allowing for better training. Our results on several evaluation benchmarks demonstrate that our proposed approach is effective and improves the previous state-of-the-art baseline.
Structural Pre-training for Dialogue Comprehension
May 23, 2021

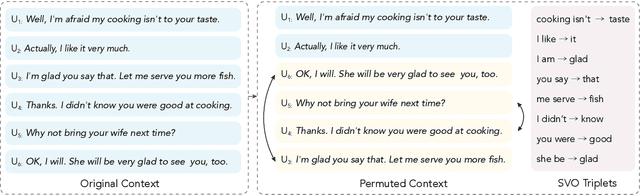
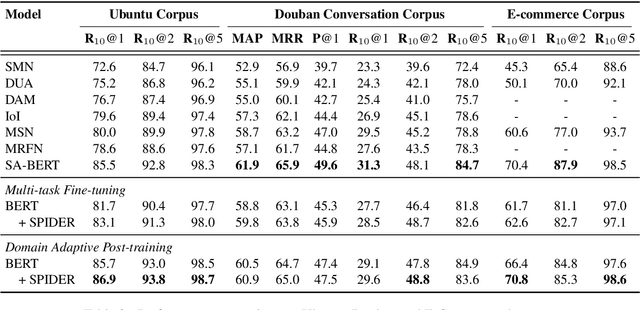
Pre-trained language models (PrLMs) have demonstrated superior performance due to their strong ability to learn universal language representations from self-supervised pre-training. However, even with the help of the powerful PrLMs, it is still challenging to effectively capture task-related knowledge from dialogue texts which are enriched by correlations among speaker-aware utterances. In this work, we present SPIDER, Structural Pre-traIned DialoguE Reader, to capture dialogue exclusive features. To simulate the dialogue-like features, we propose two training objectives in addition to the original LM objectives: 1) utterance order restoration, which predicts the order of the permuted utterances in dialogue context; 2) sentence backbone regularization, which regularizes the model to improve the factual correctness of summarized subject-verb-object triplets. Experimental results on widely used dialogue benchmarks verify the effectiveness of the newly introduced self-supervised tasks.