 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.
Balancing Efficiency and Expressiveness: Subgraph GNNs with Walk-Based Centrality
Jan 06, 2025



We propose an expressive and efficient approach that combines the strengths of two prominent extensions of Graph Neural Networks (GNNs): Subgraph GNNs and Structural Encodings (SEs). Our approach leverages walk-based centrality measures, both as a powerful form of SE and also as a subgraph selection strategy for Subgraph GNNs. By drawing a connection to perturbation analysis, we highlight the effectiveness of centrality-based sampling, and show it significantly reduces the computational burden associated with Subgraph GNNs. Further, we combine our efficient Subgraph GNN with SEs derived from the calculated centrality and demonstrate this hybrid approach, dubbed HyMN, gains in discriminative power. HyMN effectively addresses the expressiveness limitations of Message Passing Neural Networks (MPNNs) while mitigating the computational costs of Subgraph GNNs. Through a series of experiments on synthetic and real-world tasks, we show it outperforms other subgraph sampling approaches while being competitive with full-bag Subgraph GNNs and other state-of-the-art approaches with a notably reduced runtime.
Towards Foundation Models on Graphs: An Analysis on Cross-Dataset Transfer of Pretrained GNNs
Dec 23, 2024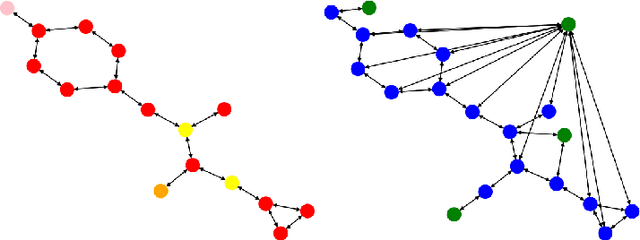
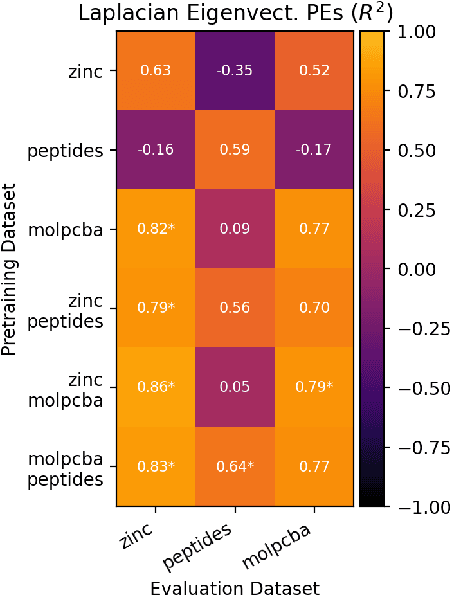
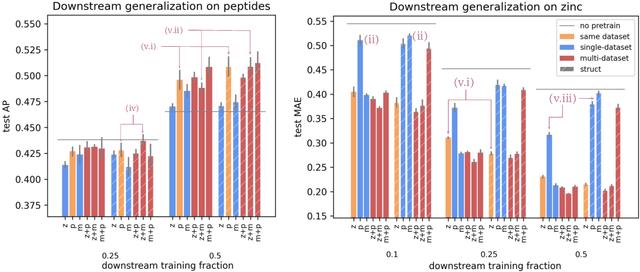
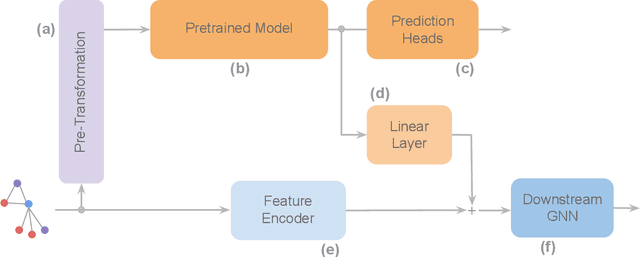
To develop a preliminary understanding towards Graph Foundation Models, we study the extent to which pretrained Graph Neural Networks can be applied across datasets, an effort requiring to be agnostic to dataset-specific features and their encodings. We build upon a purely structural pretraining approach and propose an extension to capture feature information while still being feature-agnostic. We evaluate pretrained models on downstream tasks for varying amounts of training samples and choices of pretraining datasets. Our preliminary results indicate that embeddings from pretrained models improve generalization only with enough downstream data points and in a degree which depends on the quantity and properties of pretraining data. Feature information can lead to improvements, but currently requires some similarities between pretraining and downstream feature spaces.
On the Reconstruction of Training Data from Group Invariant Networks
Nov 25, 2024



Reconstructing training data from trained neural networks is an active area of research with significant implications for privacy and explainability. Recent advances have demonstrated the feasibility of this process for several data types. However, reconstructing data from group-invariant neural networks poses distinct challenges that remain largely unexplored. This paper addresses this gap by first formulating the problem and discussing some of its basic properties. We then provide an experimental evaluation demonstrating that conventional reconstruction techniques are inadequate in this scenario. Specifically, we observe that the resulting data reconstructions gravitate toward symmetric inputs on which the group acts trivially, leading to poor-quality results. Finally, we propose two novel methods aiming to improve reconstruction in this setup and present promising preliminary experimental results. Our work sheds light on the complexities of reconstructing data from group invariant neural networks and offers potential avenues for future research in this domain.
Learning on LoRAs: GL-Equivariant Processing of Low-Rank Weight Spaces for Large Finetuned Models
Oct 05, 2024



Low-rank adaptations (LoRAs) have revolutionized the finetuning of large foundation models, enabling efficient adaptation even with limited computational resources. The resulting proliferation of LoRAs presents exciting opportunities for applying machine learning techniques that take these low-rank weights themselves as inputs. In this paper, we investigate the potential of Learning on LoRAs (LoL), a paradigm where LoRA weights serve as input to machine learning models. For instance, an LoL model that takes in LoRA weights as inputs could predict the performance of the finetuned model on downstream tasks, detect potentially harmful finetunes, or even generate novel model edits without traditional training methods. We first identify the inherent parameter symmetries of low rank decompositions of weights, which differ significantly from the parameter symmetries of standard neural networks. To efficiently process LoRA weights, we develop several symmetry-aware invariant or equivariant LoL models, using tools such as canonicalization, invariant featurization, and equivariant layers. We finetune thousands of text-to-image diffusion models and language models to collect datasets of LoRAs. In numerical experiments on these datasets, we show that our LoL architectures are capable of processing low rank weight decompositions to predict CLIP score, finetuning data attributes, finetuning data membership, and accuracy on downstream tasks.
Foldable SuperNets: Scalable Merging of Transformers with Different Initializations and Tasks
Oct 02, 2024



Many recent methods aim to merge neural networks (NNs) with identical architectures trained on different tasks to obtain a single multi-task model. Most existing works tackle the simpler setup of merging NNs initialized from a common pre-trained network, where simple heuristics like weight averaging work well. This work targets a more challenging goal: merging large transformers trained on different tasks from distinct initializations. First, we demonstrate that traditional merging methods fail catastrophically in this setup. To overcome this challenge, we propose Foldable SuperNet Merge (FS-Merge), a method that optimizes a SuperNet to fuse the original models using a feature reconstruction loss. FS-Merge is simple, data-efficient, and capable of merging models of varying widths. We test FS-Merge against existing methods, including knowledge distillation, on MLPs and transformers across various settings, sizes, tasks, and modalities. FS-Merge consistently outperforms them, achieving SOTA results, particularly in limited data scenarios.
Topological Blind Spots: Understanding and Extending Topological Deep Learning Through the Lens of Expressivity
Aug 10, 2024Topological deep learning (TDL) facilitates learning from data represented by topological structures. The primary model utilized in this setting is higher-order message-passing (HOMP), which extends traditional graph message-passing neural networks (MPNN) to diverse topological domains. Given the significant expressivity limitations of MPNNs, our paper aims to explore both the strengths and weaknesses of HOMP's expressive power and subsequently design novel architectures to address these limitations. We approach this from several perspectives: First, we demonstrate HOMP's inability to distinguish between topological objects based on fundamental topological and metric properties such as diameter, orientability, planarity, and homology. Second, we show HOMP's limitations in fully leveraging the topological structure of objects constructed using common lifting and pooling operators on graphs. Finally, we compare HOMP's expressive power to hypergraph networks, which are the most extensively studied TDL methods. We then develop two new classes of TDL models: multi-cellular networks (MCN) and scalable multi-cellular networks (SMCN). These models draw inspiration from expressive graph architectures. While MCN can reach full expressivity but is highly unscalable, SMCN offers a more scalable alternative that still mitigates many of HOMP's expressivity limitations. Finally, we construct a synthetic dataset, where TDL models are tasked with separating pairs of topological objects based on basic topological properties. We demonstrate that while HOMP is unable to distinguish between any of the pairs in the dataset, SMCN successfully distinguishes all pairs, empirically validating our theoretical findings. Our work opens a new design space and new opportunities for TDL, paving the way for more expressive and versatile models.
A Flexible, Equivariant Framework for Subgraph GNNs via Graph Products and Graph Coarsening
Jun 13, 2024



Subgraph Graph Neural Networks (Subgraph GNNs) enhance the expressivity of message-passing GNNs by representing graphs as sets of subgraphs. They have shown impressive performance on several tasks, but their complexity limits applications to larger graphs. Previous approaches suggested processing only subsets of subgraphs, selected either randomly or via learnable sampling. However, they make suboptimal subgraph selections or can only cope with very small subset sizes, inevitably incurring performance degradation. This paper introduces a new Subgraph GNNs framework to address these issues. We employ a graph coarsening function to cluster nodes into super-nodes with induced connectivity. The product between the coarsened and the original graph reveals an implicit structure whereby subgraphs are associated with specific sets of nodes. By running generalized message-passing on such graph product, our method effectively implements an efficient, yet powerful Subgraph GNN. Controlling the coarsening function enables meaningful selection of any number of subgraphs while, contrary to previous methods, being fully compatible with standard training techniques. Notably, we discover that the resulting node feature tensor exhibits new, unexplored permutation symmetries. We leverage this structure, characterize the associated linear equivariant layers and incorporate them into the layers of our Subgraph GNN architecture. Extensive experiments on multiple graph learning benchmarks demonstrate that our method is significantly more flexible than previous approaches, as it can seamlessly handle any number of subgraphs, while consistently outperforming baseline approaches.
On the Expressive Power of Spectral Invariant Graph Neural Networks
Jun 06, 2024Incorporating spectral information to enhance Graph Neural Networks (GNNs) has shown promising results but raises a fundamental challenge due to the inherent ambiguity of eigenvectors. Various architectures have been proposed to address this ambiguity, referred to as spectral invariant architectures. Notable examples include GNNs and Graph Transformers that use spectral distances, spectral projection matrices, or other invariant spectral features. However, the potential expressive power of these spectral invariant architectures remains largely unclear. The goal of this work is to gain a deep theoretical understanding of the expressive power obtainable when using spectral features. We first introduce a unified message-passing framework for designing spectral invariant GNNs, called Eigenspace Projection GNN (EPNN). A comprehensive analysis shows that EPNN essentially unifies all prior spectral invariant architectures, in that they are either strictly less expressive or equivalent to EPNN. A fine-grained expressiveness hierarchy among different architectures is also established. On the other hand, we prove that EPNN itself is bounded by a recently proposed class of Subgraph GNNs, implying that all these spectral invariant architectures are strictly less expressive than 3-WL. Finally, we discuss whether using spectral features can gain additional expressiveness when combined with more expressive GNNs.
The Empirical Impact of Neural Parameter Symmetries, or Lack Thereof
May 30, 2024



Many algorithms and observed phenomena in deep learning appear to be affected by parameter symmetries -- transformations of neural network parameters that do not change the underlying neural network function. These include linear mode connectivity, model merging, Bayesian neural network inference, metanetworks, and several other characteristics of optimization or loss-landscapes. However, theoretical analysis of the relationship between parameter space symmetries and these phenomena is difficult. In this work, we empirically investigate the impact of neural parameter symmetries by introducing new neural network architectures that have reduced parameter space symmetries. We develop two methods, with some provable guarantees, of modifying standard neural networks to reduce parameter space symmetries. With these new methods, we conduct a comprehensive experimental study consisting of multiple tasks aimed at assessing the effect of removing parameter symmetries. Our experiments reveal several interesting observations on the empirical impact of parameter symmetries; for instance, we observe linear mode connectivity between our networks without alignment of weight spaces, and we find that our networks allow for faster and more effective Bayesian neural network training.