 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
PODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Oct 21, 2024



Listeners of long-form talk-audio content, such as podcast episodes, often find it challenging to understand the overall structure and locate relevant sections. A practical solution is to divide episodes into chapters--semantically coherent segments labeled with titles and timestamps. Since most episodes on our platform at Spotify currently lack creator-provided chapters, automating the creation of chapters is essential. Scaling the chapterization of podcast episodes presents unique challenges. First, episodes tend to be less structured than written texts, featuring spontaneous discussions with nuanced transitions. Second, the transcripts are usually lengthy, averaging about 16,000 tokens, which necessitates efficient processing that can preserve context. To address these challenges, we introduce PODTILE, a fine-tuned encoder-decoder transformer to segment conversational data. The model simultaneously generates chapter transitions and titles for the input transcript. To preserve context, each input text is augmented with global context, including the episode's title, description, and previous chapter titles. In our intrinsic evaluation, PODTILE achieved an 11% improvement in ROUGE score over the strongest baseline. Additionally, we provide insights into the practical benefits of auto-generated chapters for listeners navigating episode content. Our findings indicate that auto-generated chapters serve as a useful tool for engaging with less popular podcasts. Finally, we present empirical evidence that using chapter titles can enhance effectiveness of sparse retrieval in search tasks.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021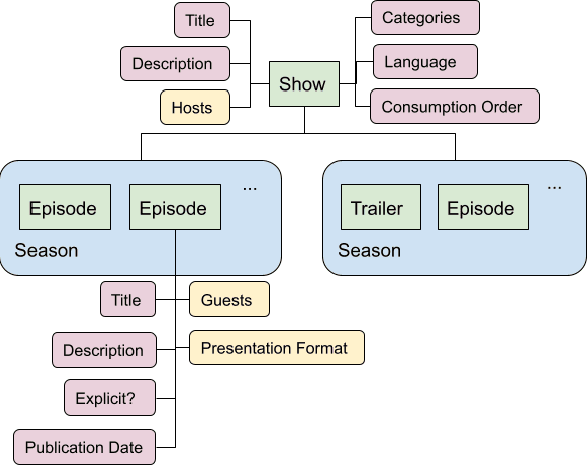
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
Tensor-based formulation and nuclear norm regularization for multi-energy computed tomography
Jul 19, 2013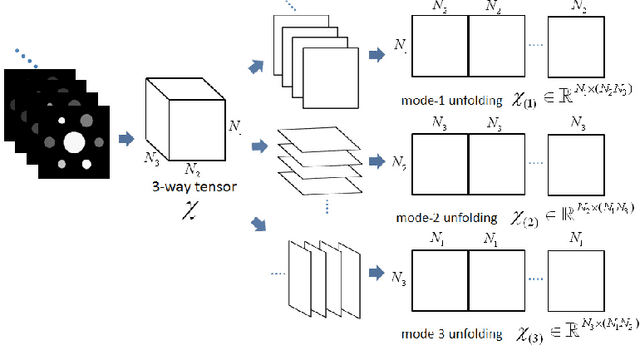
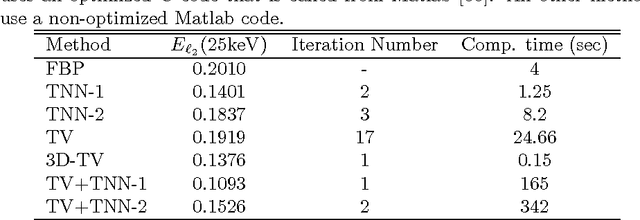
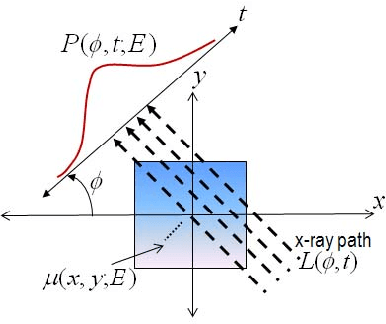
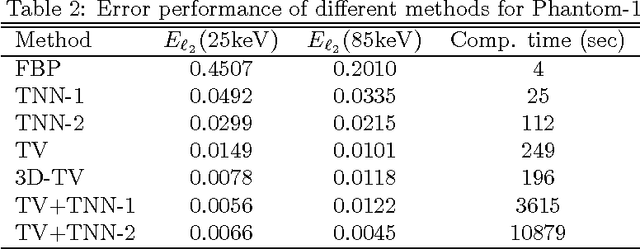
The development of energy selective, photon counting X-ray detectors allows for a wide range of new possibilities in the area of computed tomographic image formation. Under the assumption of perfect energy resolution, here we propose a tensor-based iterative algorithm that simultaneously reconstructs the X-ray attenuation distribution for each energy. We use a multi-linear image model rather than a more standard "stacked vector" representation in order to develop novel tensor-based regularizers. Specifically, we model the multi-spectral unknown as a 3-way tensor where the first two dimensions are space and the third dimension is energy. This approach allows for the design of tensor nuclear norm regularizers, which like its two dimensional counterpart, is a convex function of the multi-spectral unknown. The solution to the resulting convex optimization problem is obtained using an alternating direction method of multipliers (ADMM) approach. Simulation results shows that the generalized tensor nuclear norm can be used as a stand alone regularization technique for the energy selective (spectral) computed tomography (CT) problem and when combined with total variation regularization it enhances the regularization capabilities especially at low energy images where the effects of noise are most prominent.
A Parametric Level Set Approach to Simultaneous Object Identification and Background Reconstruction for Dual Energy Computed Tomography
Mar 29, 2011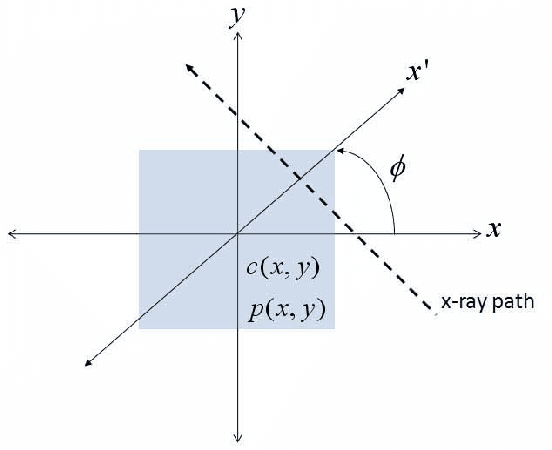
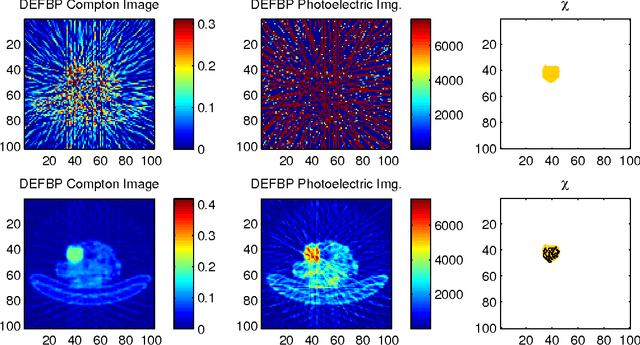
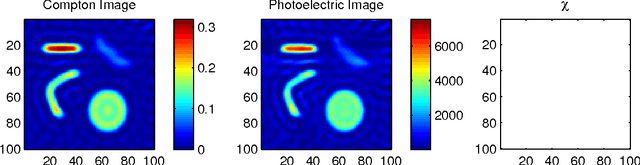
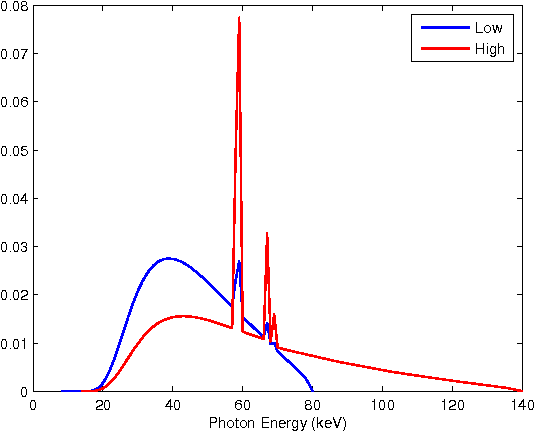
Dual energy computerized tomography has gained great interest because of its ability to characterize the chemical composition of a material rather than simply providing relative attenuation images as in conventional tomography. The purpose of this paper is to introduce a novel polychromatic dual energy processing algorithm with an emphasis on detection and characterization of piecewise constant objects embedded in an unknown, cluttered background. Physical properties of the objects, specifically the Compton scattering and photoelectric absorption coefficients, are assumed to be known with some level of uncertainty. Our approach is based on a level-set representation of the characteristic function of the object and encompasses a number of regularization techniques for addressing both the prior information we have concerning the physical properties of the object as well as fundamental, physics-based limitations associated with our ability to jointly recover the Compton scattering and photoelectric absorption properties of the scene. In the absence of an object with appropriate physical properties, our approach returns a null characteristic function and thus can be viewed as simultaneously solving the detection and characterization problems. Unlike the vast majority of methods which define the level set function non-parametrically, i.e., as a dense set of pixel values), we define our level set parametrically via radial basis functions (RBF's) and employ a Gauss-Newton type algorithm for cost minimization. Numerical results show that the algorithm successfully detects objects of interest, finds their shape and location, and gives a adequate reconstruction of the background.