 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: Graph-Induced Fine-Tuning for Multi-Party Conversation Understanding
May 17, 2023



Addressing the issues of who saying what to whom in multi-party conversations (MPCs) has recently attracted a lot of research attention. However, existing methods on MPC understanding typically embed interlocutors and utterances into sequential information flows, or utilize only the superficial of inherent graph structures in MPCs. To this end, we present a plug-and-play and lightweight method named graph-induced fine-tuning (GIFT) which can adapt various Transformer-based pre-trained language models (PLMs) for universal MPC understanding. In detail, the full and equivalent connections among utterances in regular Transformer ignore the sparse but distinctive dependency of an utterance on another in MPCs. To distinguish different relationships between utterances, four types of edges are designed to integrate graph-induced signals into attention mechanisms to refine PLMs originally designed for processing sequential texts. We evaluate GIFT by implementing it into three PLMs, and test the performance on three downstream tasks including addressee recognition, speaker identification and response selection. Experimental results show that GIFT can significantly improve the performance of three PLMs on three downstream tasks and two benchmarks with only 4 additional parameters per encoding layer, achieving new state-of-the-art performance on MPC understanding.
Multi-Stage Coarse-to-Fine Contrastive Learning for Conversation Intent Induction
Mar 09, 2023



Intent recognition is critical for task-oriented dialogue systems. However, for emerging domains and new services, it is difficult to accurately identify the key intent of a conversation due to time-consuming data annotation and comparatively poor model transferability. Therefore, the automatic induction of dialogue intention is very important for intelligent dialogue systems. This paper presents our solution to Track 2 of Intent Induction from Conversations for Task-Oriented Dialogue at the Eleventh Dialogue System Technology Challenge (DSTC11). The essence of intention clustering lies in distinguishing the representation of different dialogue utterances. The key to automatic intention induction is that, for any given set of new data, the sentence representation obtained by the model can be well distinguished from different labels. Therefore, we propose a multi-stage coarse-to-fine contrastive learning model training scheme including unsupervised contrastive learning pre-training, supervised contrastive learning pre-training, and fine-tuning with joint contrastive learning and clustering to obtain a better dialogue utterance representation model for the clustering task. In the released DSTC11 Track 2 evaluation results, our proposed system ranked first on both of the two subtasks of this Track.
SportsSum2.0: Generating High-Quality Sports News from Live Text Commentary
Oct 12, 2021
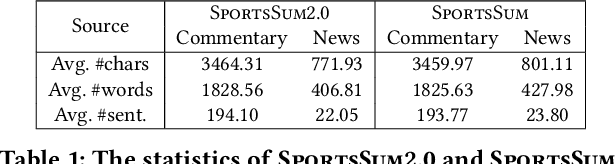
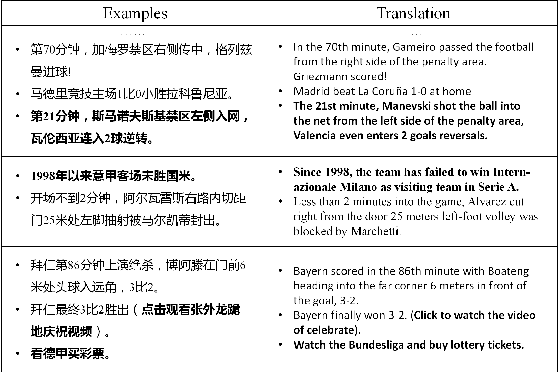
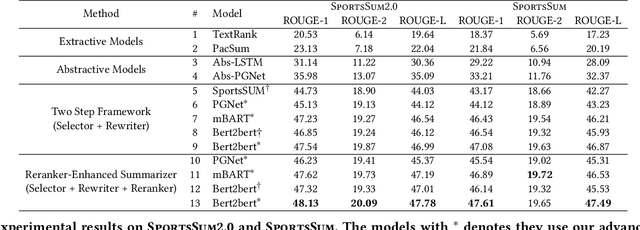
Sports game summarization aims to generate news articles from live text commentaries. A recent state-of-the-art work, SportsSum, not only constructs a large benchmark dataset, but also proposes a two-step framework. Despite its great contributions, the work has three main drawbacks: 1) the noise existed in SportsSum dataset degrades the summarization performance; 2) the neglect of lexical overlap between news and commentaries results in low-quality pseudo-labeling algorithm; 3) the usage of directly concatenating rewritten sentences to form news limits its practicability. In this paper, we publish a new benchmark dataset SportsSum2.0, together with a modified summarization framework. In particular, to obtain a clean dataset, we employ crowd workers to manually clean the original dataset. Moreover, the degree of lexical overlap is incorporated into the generation of pseudo labels. Further, we introduce a reranker-enhanced summarizer to take into account the fluency and expressiveness of the summarized news. Extensive experiments show that our model outperforms the state-of-the-art baseline.
Adversarial Training for Machine Reading Comprehension with Virtual Embeddings
Jun 08, 2021Adversarial training (AT) as a regularization method has proved its effectiveness on various tasks. Though there are successful applications of AT on some NLP tasks, the distinguishing characteristics of NLP tasks have not been exploited. In this paper, we aim to apply AT on machine reading comprehension (MRC) tasks. Furthermore, we adapt AT for MRC tasks by proposing a novel adversarial training method called PQAT that perturbs the embedding matrix instead of word vectors. To differentiate the roles of passages and questions, PQAT uses additional virtual P/Q-embedding matrices to gather the global perturbations of words from passages and questions separately. We test the method on a wide range of MRC tasks, including span-based extractive RC and multiple-choice RC. The results show that adversarial training is effective universally, and PQAT further improves the performance.
Memory Augmented Sequential Paragraph Retrieval for Multi-hop Question Answering
Feb 07, 2021Retrieving information from correlative paragraphs or documents to answer open-domain multi-hop questions is very challenging. To deal with this challenge, most of the existing works consider paragraphs as nodes in a graph and propose graph-based methods to retrieve them. However, in this paper, we point out the intrinsic defect of such methods. Instead, we propose a new architecture that models paragraphs as sequential data and considers multi-hop information retrieval as a kind of sequence labeling task. Specifically, we design a rewritable external memory to model the dependency among paragraphs. Moreover, a threshold gate mechanism is proposed to eliminate the distraction of noise paragraphs. We evaluate our method on both full wiki and distractor subtask of HotpotQA, a public textual multi-hop QA dataset requiring multi-hop information retrieval. Experiments show that our method achieves significant improvement over the published state-of-the-art method in retrieval and downstream QA task performance.
Unsupervised Explanation Generation for Machine Reading Comprehension
Nov 13, 2020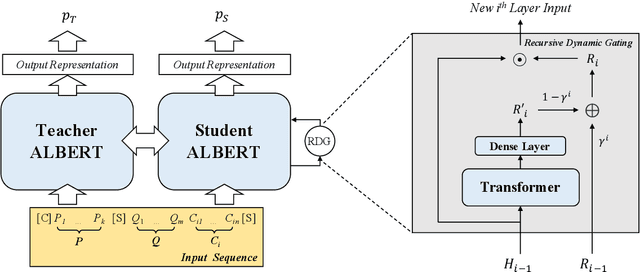
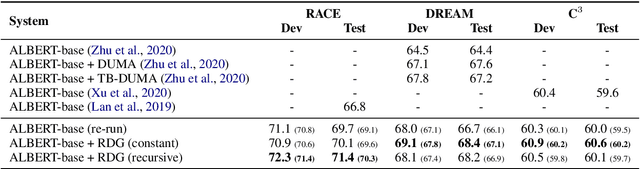
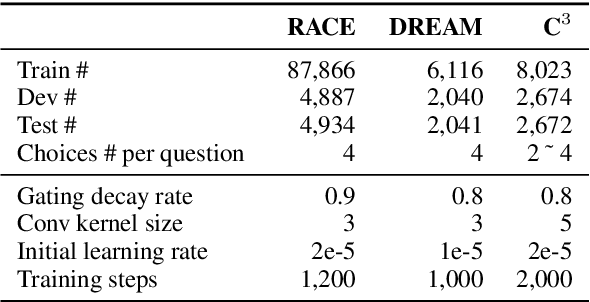

With the blooming of various Pre-trained Language Models (PLMs), Machine Reading Comprehension (MRC) has embraced significant improvements on various benchmarks and even surpass human performances. However, the existing works only target on the accuracy of the final predictions and neglect the importance of the explanations for the prediction, which is a big obstacle when utilizing these models in real-life applications to convince humans. In this paper, we propose a self-explainable framework for the machine reading comprehension task. The main idea is that the proposed system tries to use less passage information and achieve similar results compared to the system that uses the whole passage, while the filtered passage will be used as explanations. We carried out experiments on three multiple-choice MRC datasets, and found that the proposed system could achieve consistent improvements over baseline systems. To evaluate the explainability, we compared our approach with the traditional attention mechanism in human evaluations and found that the proposed system has a notable advantage over the latter one.
CharBERT: Character-aware Pre-trained Language Model
Nov 03, 2020
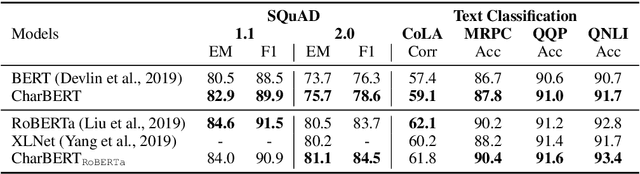
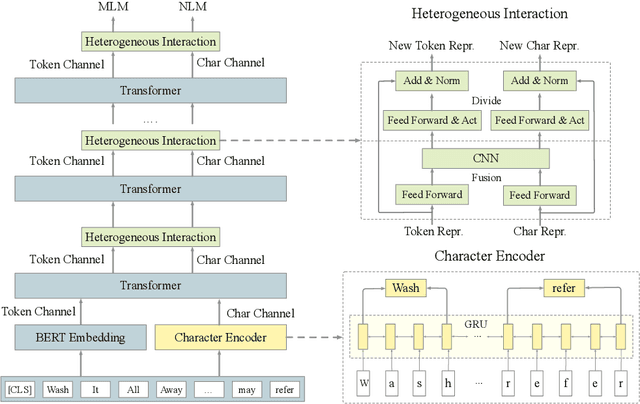
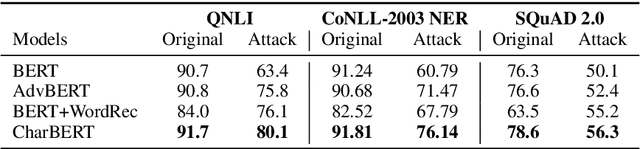
Most pre-trained language models (PLMs) construct word representations at subword level with Byte-Pair Encoding (BPE) or its variations, by which OOV (out-of-vocab) words are almost avoidable. However, those methods split a word into subword units and make the representation incomplete and fragile. In this paper, we propose a character-aware pre-trained language model named CharBERT improving on the previous methods (such as BERT, RoBERTa) to tackle these problems. We first construct the contextual word embedding for each token from the sequential character representations, then fuse the representations of characters and the subword representations by a novel heterogeneous interaction module. We also propose a new pre-training task named NLM (Noisy LM) for unsupervised character representation learning. We evaluate our method on question answering, sequence labeling, and text classification tasks, both on the original datasets and adversarial misspelling test sets. The experimental results show that our method can significantly improve the performance and robustness of PLMs simultaneously. Pretrained models, evaluation sets, and code are available at https://github.com/wtma/CharBERT
Revisiting Pre-Trained Models for Chinese Natural Language Processing
Apr 29, 2020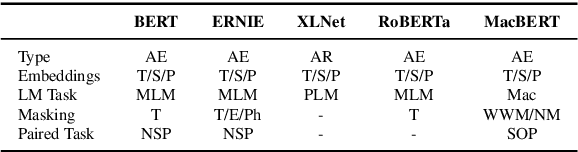

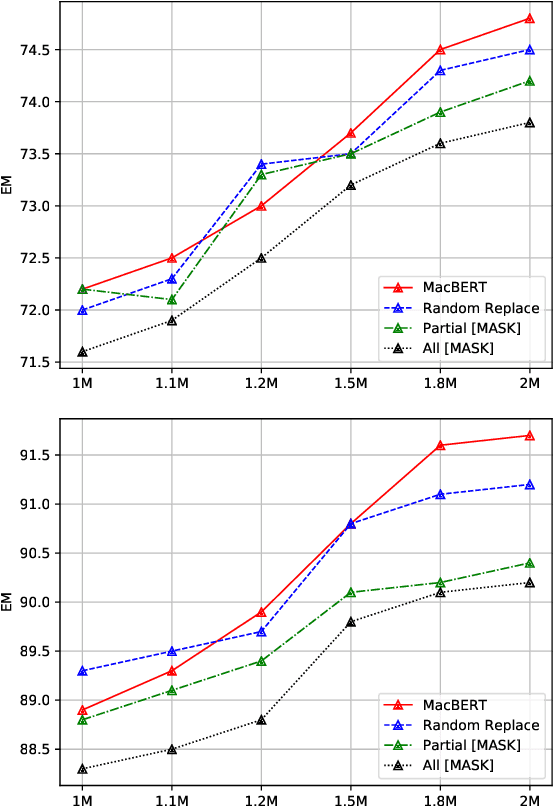
Bidirectional Encoder Representations from Transformers (BERT) has shown marvelous improvements across various NLP tasks, and various variants have been proposed to further improve the performance of the pre-trained models. In this paper, we target on revisiting Chinese pre-trained models to examine their effectiveness in a non-English language and release the Chinese pre-trained model series to the community. We also propose a simple but effective model called MacBERT, which improves upon RoBERTa in several ways, especially the masking strategy. We carried out extensive experiments on various Chinese NLP tasks, covering sentence-level to document-level, to revisit the existing pre-trained models as well as the proposed MacBERT. Experimental results show that MacBERT could achieve state-of-the-art performances on many NLP tasks, and we also ablate details with several findings that may help future research.
Conversational Word Embedding for Retrieval-Based Dialog System
Apr 28, 2020
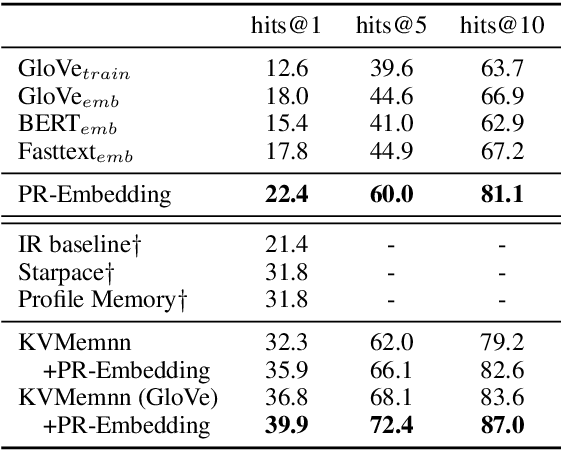
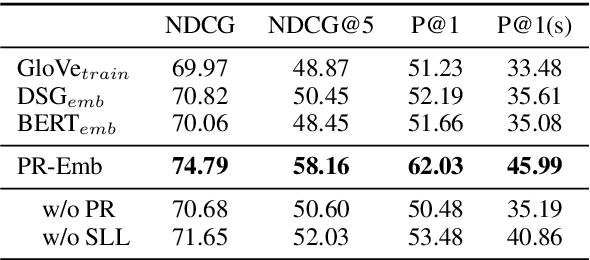
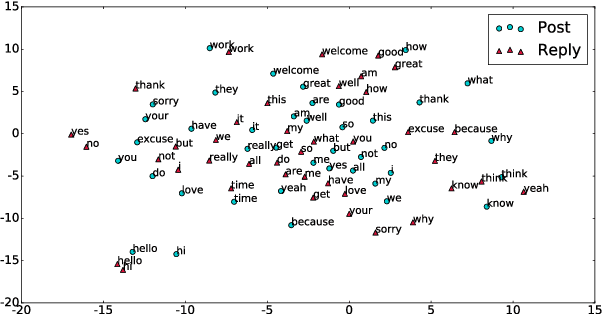
Human conversations contain many types of information, e.g., knowledge, common sense, and language habits. In this paper, we propose a conversational word embedding method named PR-Embedding, which utilizes the conversation pairs $ \left\langle{post, reply} \right\rangle$ to learn word embedding. Different from previous works, PR-Embedding uses the vectors from two different semantic spaces to represent the words in post and reply. To catch the information among the pair, we first introduce the word alignment model from statistical machine translation to generate the cross-sentence window, then train the embedding on word-level and sentence-level. We evaluate the method on single-turn and multi-turn response selection tasks for retrieval-based dialog systems. The experiment results show that PR-Embedding can improve the quality of the selected response. PR-Embedding source code is available at https://github.com/wtma/PR-Embedding
A Sentence Cloze Dataset for Chinese Machine Reading Comprehension
Apr 07, 2020
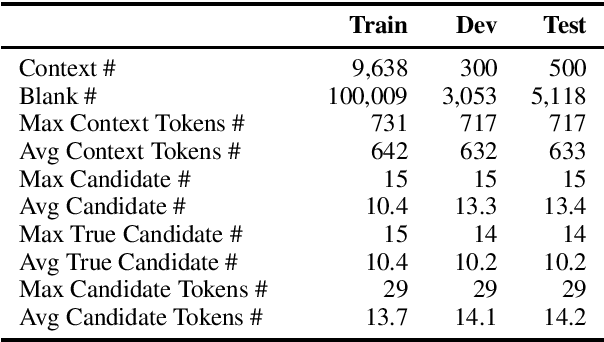
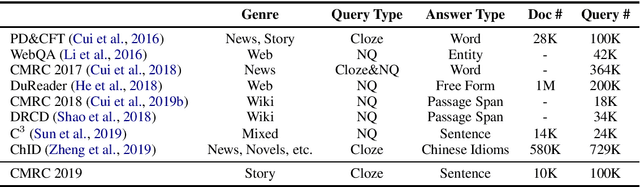
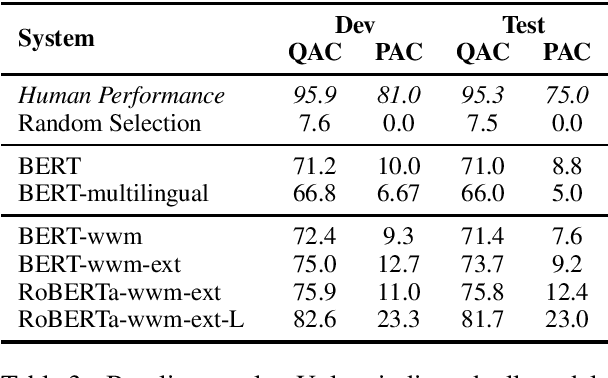
Owing to the continuous contributions by the Chinese NLP community, more and more Chinese machine reading comprehension datasets become available, and they have been pushing Chinese MRC research forward. To add diversity in this area, in this paper, we propose a new task called Sentence Cloze-style Machine Reading Comprehension (SC-MRC). The proposed task aims to fill the right candidate sentence into the passage that has several blanks. Moreover, to add more difficulties, we also made fake candidates that are similar to the correct ones, which requires the machine to judge their correctness in the context. The proposed dataset contains over 100K blanks (questions) within over 10K passages, which was originated from Chinese narrative stories. To evaluate the dataset, we implement several baseline systems based on pre-trained models, and the results show that the state-of-the-art model still underperforms human performance by a large margin. We hope the release of the dataset could further accelerate the machine reading comprehension research. Resources available: https://github.com/ymcui/cmrc2019