 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronicles-OCR: A Cross-Temporal Perception Benchmark for the Evolutionary Trajectory of Chinese Characters
May 12, 2026Vision Large Language Models (VLLMs) have achieved remarkable success in modern text-rich visual understanding. However, their perceptual robustness in the face of the continuous morphological evolution of historical writing systems remains largely unexplored. Existing ancient text datasets typically focus on isolated historical periods, failing to capture the systematic visual distribution shifts spanning thousands of years. To bridge this gap and empower Digital Humanities, we introduce Chronicles-OCR, the first comprehensive benchmark specifically designed to evaluate the cross-temporal visual perception capabilities of VLLMs across the complete evolutionary trajectory of Chinese characters, known as the Seven Chinese Scripts. Curated in collaboration with top-tier institutional domain experts, the dataset comprises 2,800 strictly balanced images encompassing highly diverse physical media, ranging from tortoise shells to paper-based calligraphy. To accommodate the drastic morphological and topological variations across different historical stages, we propose a novel Stage-Adaptive Annotation Paradigm. Based on this, Chronicles-OCR formulates four rigorous quantitative tasks: cross-period character spotting, fine-grained archaic character recognition via visual referring, ancient text parsing, and script classification. By isolating visual perception from semantic reasoning, Chronicles-OCR provides an authoritative platform to expose the limitations of current VLLMs, paving the way for robust, evolution-aware historical text perception. Chronicles-OCR is publicly available at https://github.com/VirtualLUOUCAS/Chronicles-OCR.
M^2-MedDialog: A Dataset and Benchmarks for Multi-domain Multi-service Medical Dialogues
Sep 08, 2021
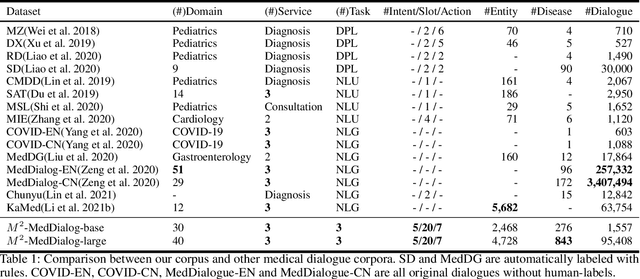
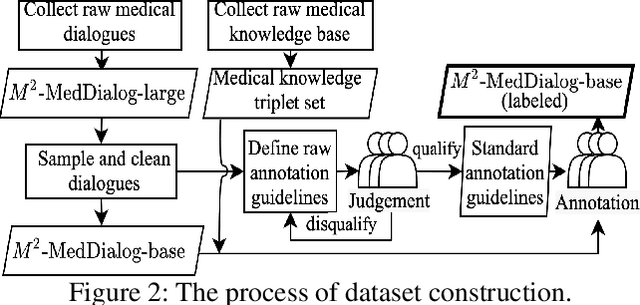
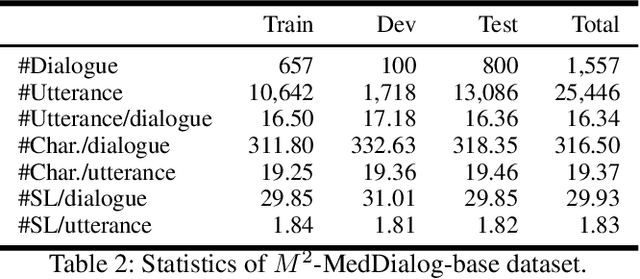
Medical dialogue systems (MDSs) aim to assist doctors and patients with a range of professional medical services, i.e., diagnosis, consultation, and treatment. However, one-stop MDS is still unexplored because: (1) no dataset has so large-scale dialogues contains both multiple medical services and fine-grained medical labels (i.e., intents, slots, values); (2) no model has addressed a MDS based on multiple-service conversations in a unified framework. In this work, we first build a Multiple-domain Multiple-service medical dialogue (M^2-MedDialog)dataset, which contains 1,557 conversations between doctors and patients, covering 276 types of diseases, 2,468 medical entities, and 3 specialties of medical services. To the best of our knowledge, it is the only medical dialogue dataset that includes both multiple medical services and fine-grained medical labels. Then, we formulate a one-stop MDS as a sequence-to-sequence generation problem. We unify a MDS with causal language modeling and conditional causal language modeling, respectively. Specifically, we employ several pretrained models (i.e., BERT-WWM, BERT-MED, GPT2, and MT5) and their variants to get benchmarks on M^2-MedDialog dataset. We also propose pseudo labeling and natural perturbation methods to expand M2-MedDialog dataset and enhance the state-of-the-art pretrained models. We demonstrate the results achieved by the benchmarks so far through extensive experiments on M2-MedDialog. We release the dataset, the code, as well as the evaluation scripts to facilitate future research in this important research direction.