 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Chunking for Soft Prompts: Accelerating Compressor Learning via Block-wise Causal Masking
Feb 15, 2026Providing extensive context via prompting is vital for leveraging the capabilities of Large Language Models (LLMs). However, lengthy contexts significantly increase inference latency, as the computational cost of self-attention grows quadratically with sequence length. To mitigate this issue, context compression-particularly soft prompt compressio-has emerged as a widely studied solution, which converts long contexts into shorter memory embeddings via a trained compressor. Existing methods typically compress the entire context indiscriminately into a set of memory tokens, requiring the compressor to capture global dependencies and necessitating extensive pre-training data to learn effective patterns. Inspired by the chunking mechanism in human working memory and empirical observations of the spatial specialization of memory embeddings relative to original tokens, we propose Parallelized Iterative Compression (PIC). By simply modifying the Transformer's attention mask, PIC explicitly restricts the receptive field of memory tokens to sequential local chunks, thereby lowering the difficulty of compressor training. Experiments across multiple downstream tasks demonstrate that PIC consistently outperforms competitive baselines, with superiority being particularly pronounced in high compression scenarios (e.g., achieving relative improvements of 29.8\% in F1 score and 40.7\% in EM score on QA tasks at the $64\times$ compression ratio). Furthermore, PIC significantly expedites the training process. Specifically, when training the 16$\times$ compressor, it surpasses the peak performance of the competitive baseline while effectively reducing the training time by approximately 40\%.
A Zero-Shot based Fingerprint Presentation Attack Detection System
Feb 12, 2020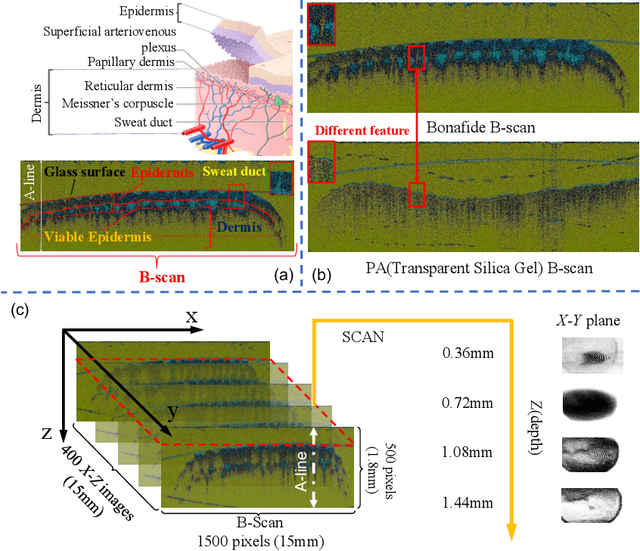

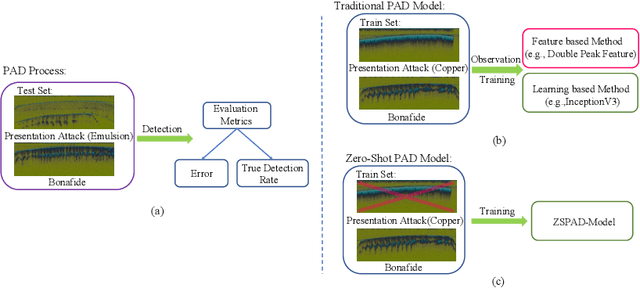
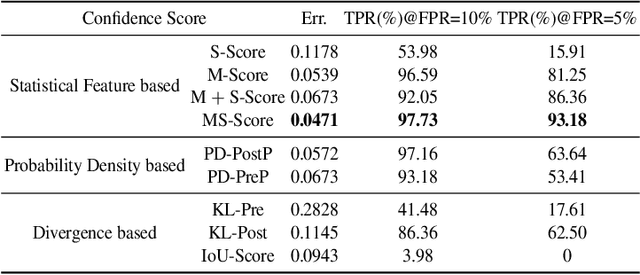
With the development of presentation attacks, Automated Fingerprint Recognition Systems(AFRSs) are vulnerable to presentation attack. Thus, numerous methods of presentation attack detection(PAD) have been proposed to ensure the normal utilization of AFRS. However, the demand of large-scale presentation attack images and the low-level generalization ability always astrict existing PAD methods' actual performances. Therefore, we propose a novel Zero-Shot Presentation Attack Detection Model to guarantee the generalization of the PAD model. The proposed ZSPAD-Model based on generative model does not utilize any negative samples in the process of establishment, which ensures the robustness for various types or materials based presentation attack. Different from other auto-encoder based model, the Fine-grained Map architecture is proposed to refine the reconstruction error of the auto-encoder networks and a task-specific gaussian model is utilized to improve the quality of clustering. Meanwhile, in order to improve the performance of the proposed model, 9 confidence scores are discussed in this article. Experimental results showed that the ZSPAD-Model is the state of the art for ZSPAD, and the MS-Score is the best confidence score. Compared with existing methods, the proposed ZSPAD-Model performs better than the feature-based method and under the multi-shot setting, the proposed method overperforms the learning based method with little training data. When large training data is available, their results are similar.