 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-aware Deep Transform
Oct 18, 2015
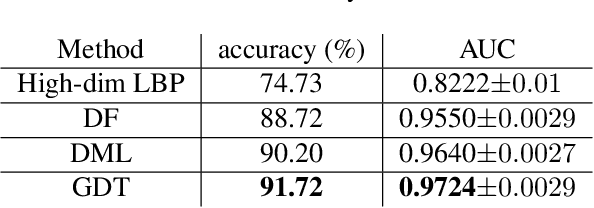
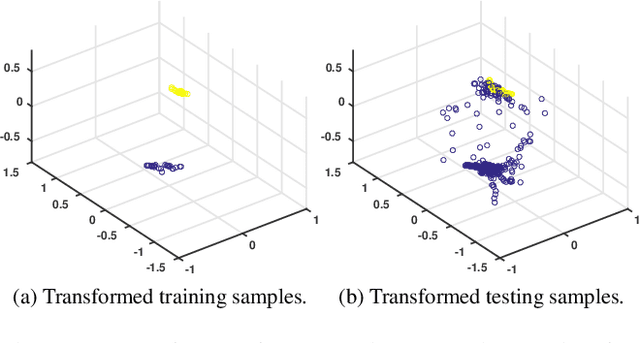
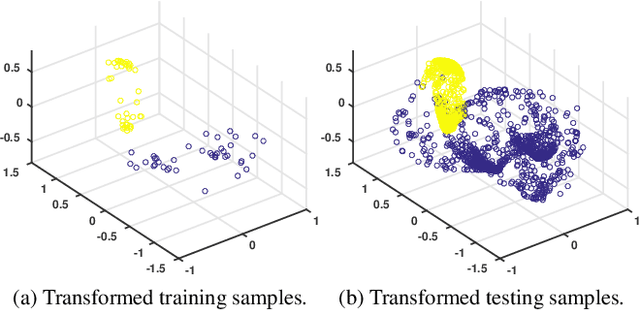
Many recent efforts have been devoted to designing sophisticated deep learning structures, obtaining revolutionary results on benchmark datasets. The success of these deep learning methods mostly relies on an enormous volume of labeled training samples to learn a huge number of parameters in a network; therefore, understanding the generalization ability of a learned deep network cannot be overlooked, especially when restricted to a small training set, which is the case for many applications. In this paper, we propose a novel deep learning objective formulation that unifies both the classification and metric learning criteria. We then introduce a geometry-aware deep transform to enable a non-linear discriminative and robust feature transform, which shows competitive performance on small training sets for both synthetic and real-world data. We further support the proposed framework with a formal $(K,\epsilon)$-robustness analysis.
Compressed Nonnegative Matrix Factorization is Fast and Accurate
Sep 06, 2015
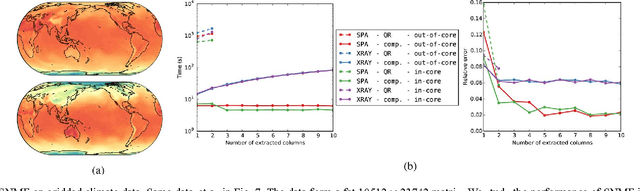
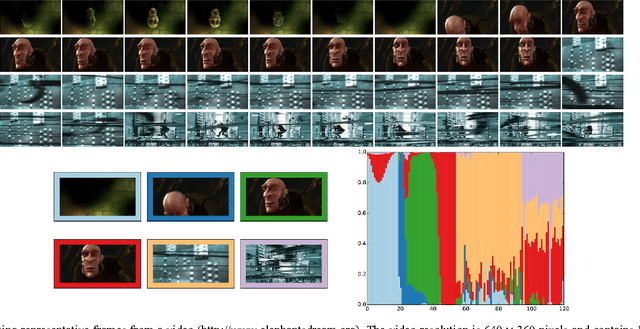
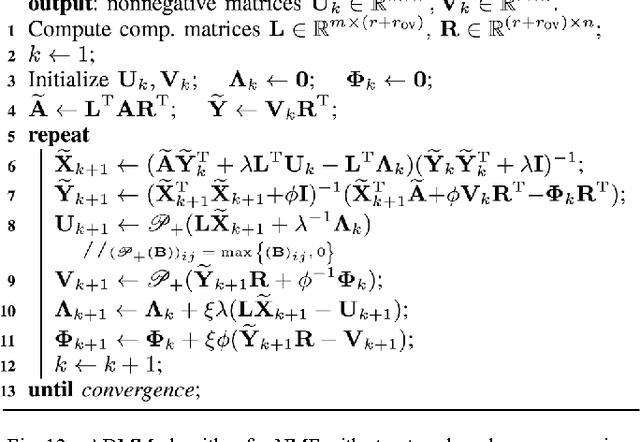
Nonnegative matrix factorization (NMF) has an established reputation as a useful data analysis technique in numerous applications. However, its usage in practical situations is undergoing challenges in recent years. The fundamental factor to this is the increasingly growing size of the datasets available and needed in the information sciences. To address this, in this work we propose to use structured random compression, that is, random projections that exploit the data structure, for two NMF variants: classical and separable. In separable NMF (SNMF) the left factors are a subset of the columns of the input matrix. We present suitable formulations for each problem, dealing with different representative algorithms within each one. We show that the resulting compressed techniques are faster than their uncompressed variants, vastly reduce memory demands, and do not encompass any significant deterioration in performance. The proposed structured random projections for SNMF allow to deal with arbitrarily shaped large matrices, beyond the standard limit of tall-and-skinny matrices, granting access to very efficient computations in this general setting. We accompany the algorithmic presentation with theoretical foundations and numerous and diverse examples, showing the suitability of the proposed approaches.
Data Representation using the Weyl Transform
Jul 21, 2015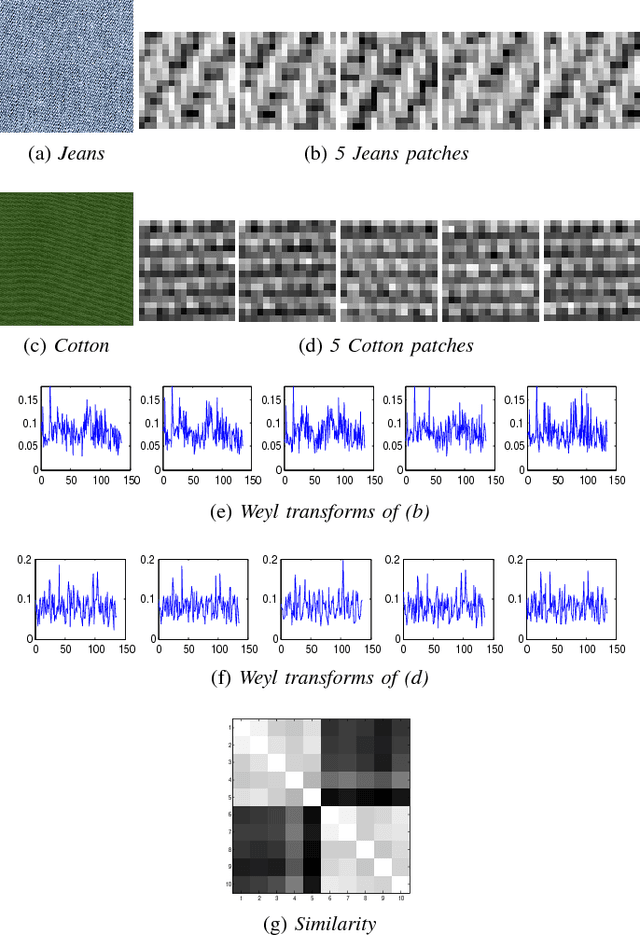
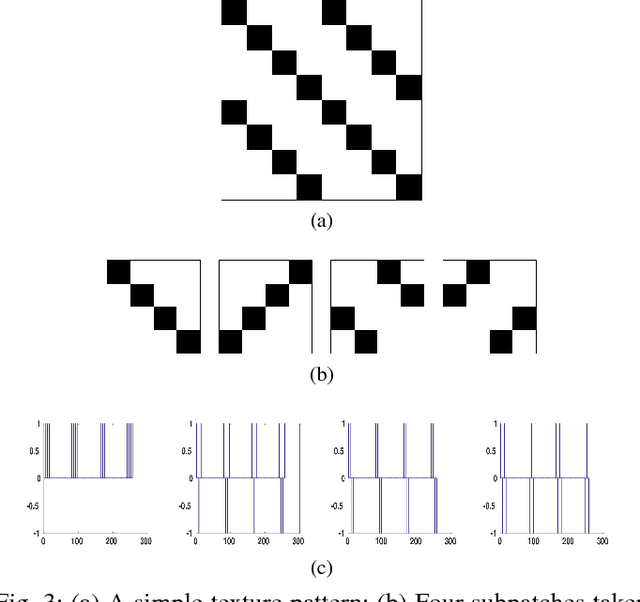


The Weyl transform is introduced as a rich framework for data representation. Transform coefficients are connected to the Walsh-Hadamard transform of multiscale autocorrelations, and different forms of dyadic periodicity in a signal are shown to appear as different features in its Weyl coefficients. The Weyl transform has a high degree of symmetry with respect to a large group of multiscale transformations, which allows compact yet discriminative representations to be obtained by pooling coefficients. The effectiveness of the Weyl transform is demonstrated through the example of textured image classification.
On the Stability of Deep Networks
Jun 03, 2015In this work we study the properties of deep neural networks (DNN) with random weights. We formally prove that these networks perform a distance-preserving embedding of the data. Based on this we then draw conclusions on the size of the training data and the networks' structure. A longer version of this paper with more results and details can be found in (Giryes et al., 2015). In particular, we formally prove in the longer version that DNN with random Gaussian weights perform a distance-preserving embedding of the data, with a special treatment for in-class and out-of-class data.
Random Forests Can Hash
Apr 17, 2015
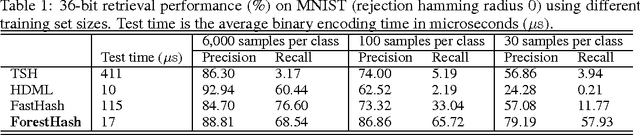
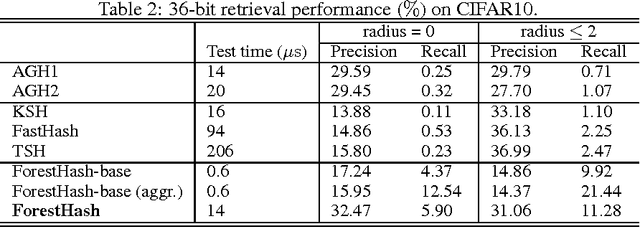
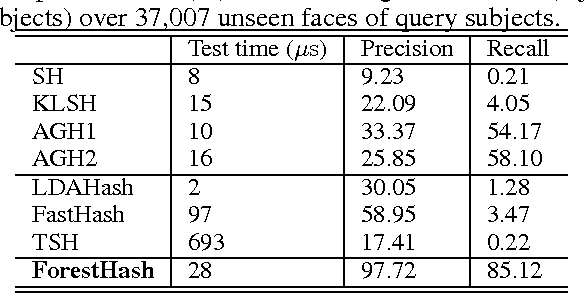
Hash codes are a very efficient data representation needed to be able to cope with the ever growing amounts of data. We introduce a random forest semantic hashing scheme with information-theoretic code aggregation, showing for the first time how random forest, a technique that together with deep learning have shown spectacular results in classification, can also be extended to large-scale retrieval. Traditional random forest fails to enforce the consistency of hashes generated from each tree for the same class data, i.e., to preserve the underlying similarity, and it also lacks a principled way for code aggregation across trees. We start with a simple hashing scheme, where independently trained random trees in a forest are acting as hashing functions. We the propose a subspace model as the splitting function, and show that it enforces the hash consistency in a tree for data from the same class. We also introduce an information-theoretic approach for aggregating codes of individual trees into a single hash code, producing a near-optimal unique hash for each class. Experiments on large-scale public datasets are presented, showing that the proposed approach significantly outperforms state-of-the-art hashing methods for retrieval tasks.
Graph Matching: Relax at Your Own Risk
Jan 10, 2015
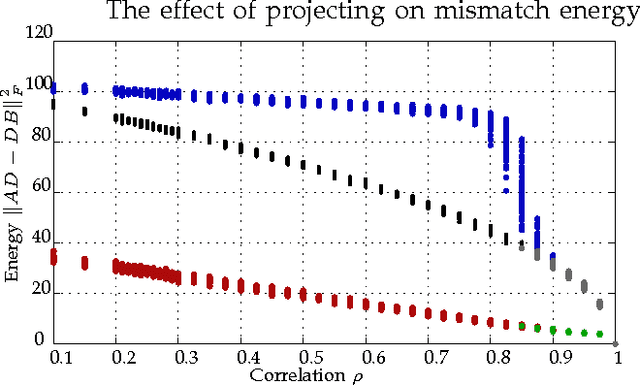
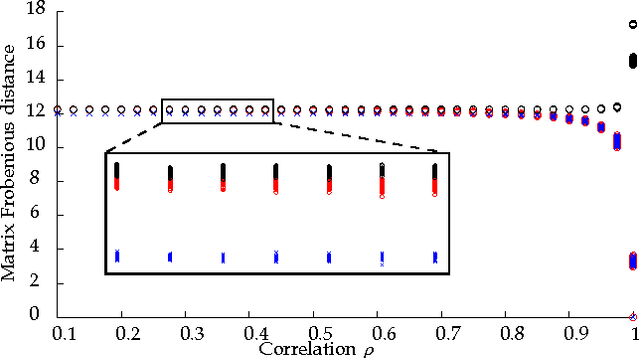
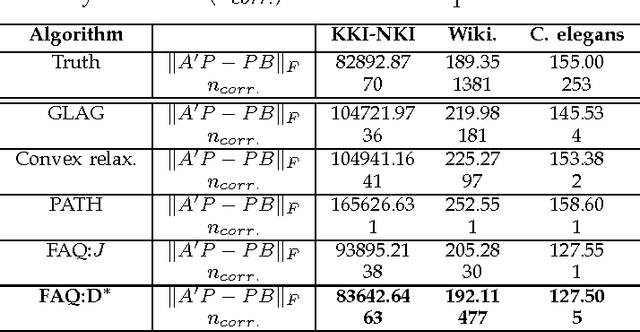
Graph matching---aligning a pair of graphs to minimize their edge disagreements---has received wide-spread attention from both theoretical and applied communities over the past several decades, including combinatorics, computer vision, and connectomics. Its attention can be partially attributed to its computational difficulty. Although many heuristics have previously been proposed in the literature to approximately solve graph matching, very few have any theoretical support for their performance. A common technique is to relax the discrete problem to a continuous problem, therefore enabling practitioners to bring gradient-descent-type algorithms to bear. We prove that an indefinite relaxation (when solved exactly) almost always discovers the optimal permutation, while a common convex relaxation almost always fails to discover the optimal permutation. These theoretical results suggest that initializing the indefinite algorithm with the convex optimum might yield improved practical performance. Indeed, experimental results illuminate and corroborate these theoretical findings, demonstrating that excellent results are achieved in both benchmark and real data problems by amalgamating the two approaches.
A Bi-clustering Framework for Consensus Problems
Aug 20, 2014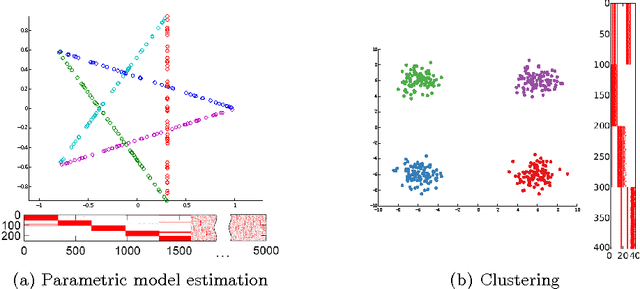
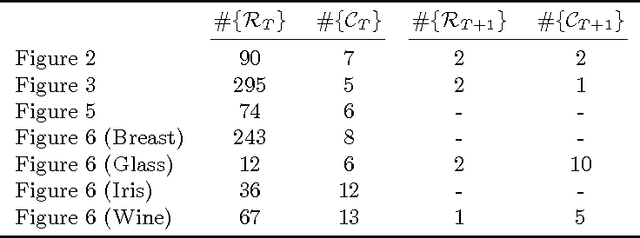
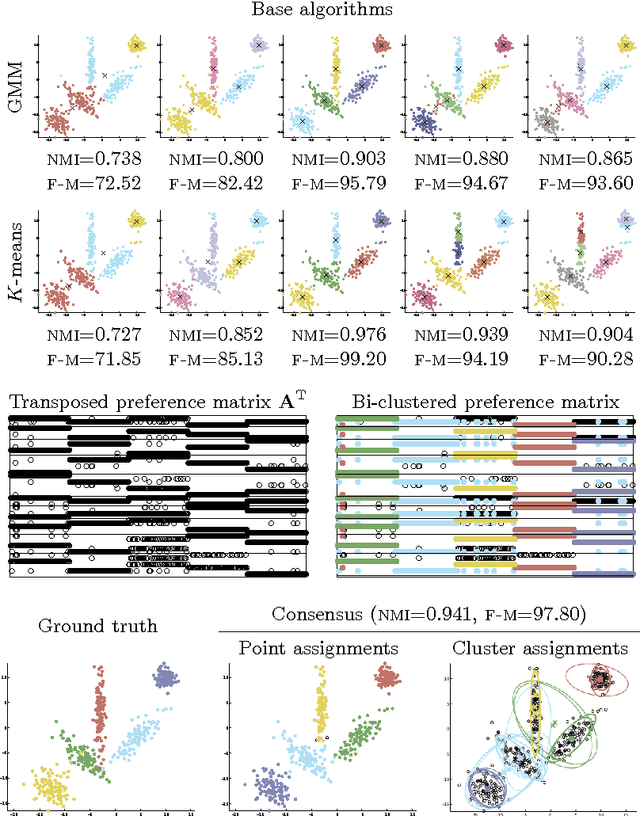
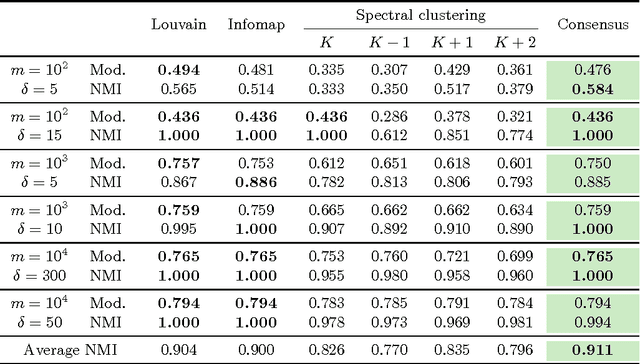
We consider grouping as a general characterization for problems such as clustering, community detection in networks, and multiple parametric model estimation. We are interested in merging solutions from different grouping algorithms, distilling all their good qualities into a consensus solution. In this paper, we propose a bi-clustering framework and perspective for reaching consensus in such grouping problems. In particular, this is the first time that the task of finding/fitting multiple parametric models to a dataset is formally posed as a consensus problem. We highlight the equivalence of these tasks and establish the connection with the computational Gestalt program, that seeks to provide a psychologically-inspired detection theory for visual events. We also present a simple but powerful bi-clustering algorithm, specially tuned to the nature of the problem we address, though general enough to handle many different instances inscribed within our characterization. The presentation is accompanied with diverse and extensive experimental results in clustering, community detection, and multiple parametric model estimation in image processing applications.
Learning Transformations for Clustering and Classification
Mar 09, 2014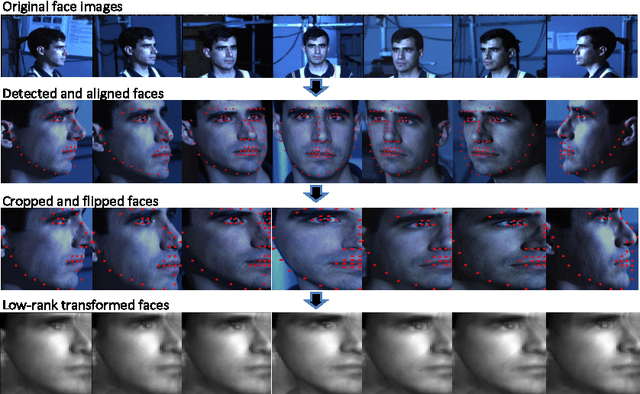
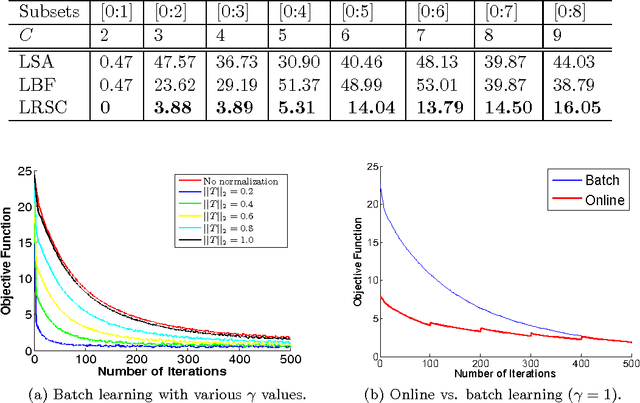
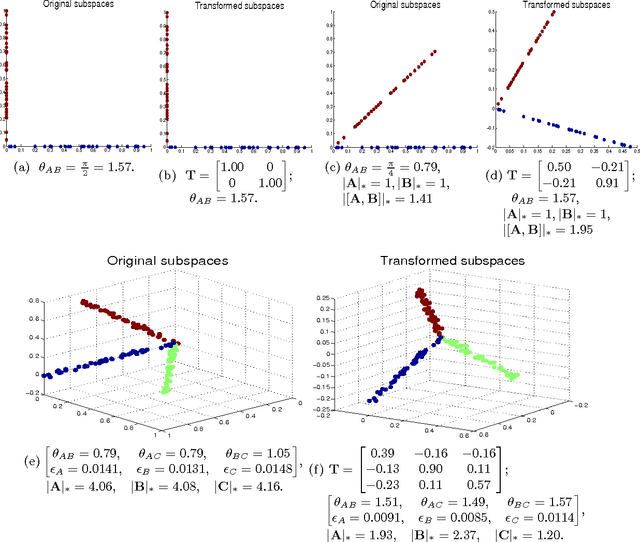
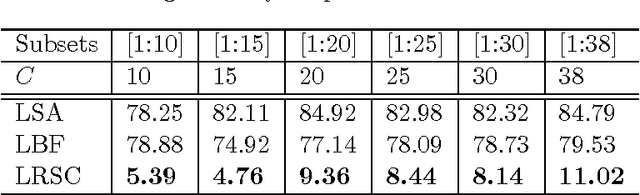
A low-rank transformation learning framework for subspace clustering and classification is here proposed. Many high-dimensional data, such as face images and motion sequences, approximately lie in a union of low-dimensional subspaces. The corresponding subspace clustering problem has been extensively studied in the literature to partition such high-dimensional data into clusters corresponding to their underlying low-dimensional subspaces. However, low-dimensional intrinsic structures are often violated for real-world observations, as they can be corrupted by errors or deviate from ideal models. We propose to address this by learning a linear transformation on subspaces using matrix rank, via its convex surrogate nuclear norm, as the optimization criteria. The learned linear transformation restores a low-rank structure for data from the same subspace, and, at the same time, forces a a maximally separated structure for data from different subspaces. In this way, we reduce variations within subspaces, and increase separation between subspaces for a more robust subspace clustering. This proposed learned robust subspace clustering framework significantly enhances the performance of existing subspace clustering methods. Basic theoretical results here presented help to further support the underlying framework. To exploit the low-rank structures of the transformed subspaces, we further introduce a fast subspace clustering technique, which efficiently combines robust PCA with sparse modeling. When class labels are present at the training stage, we show this low-rank transformation framework also significantly enhances classification performance. Extensive experiments using public datasets are presented, showing that the proposed approach significantly outperforms state-of-the-art methods for subspace clustering and classification.
Low-Cost Compressive Sensing for Color Video and Depth
Feb 27, 2014
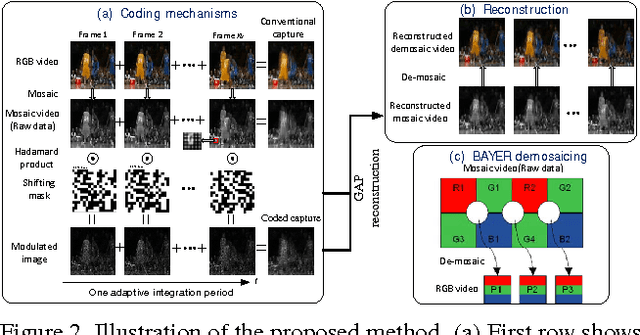
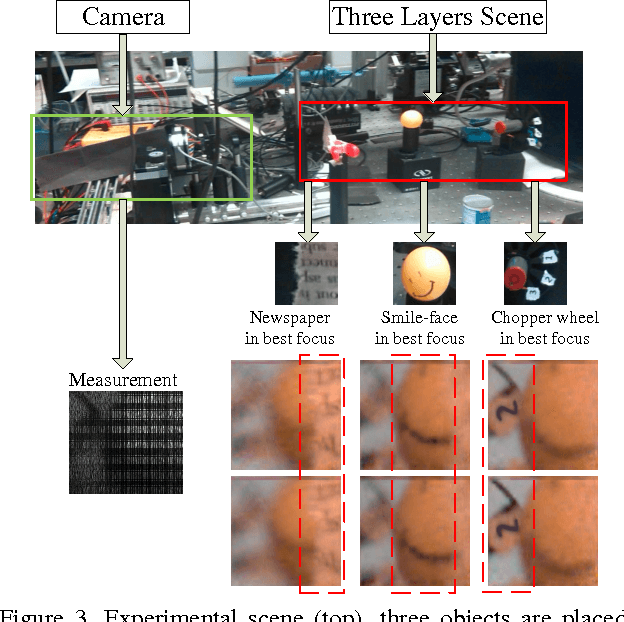
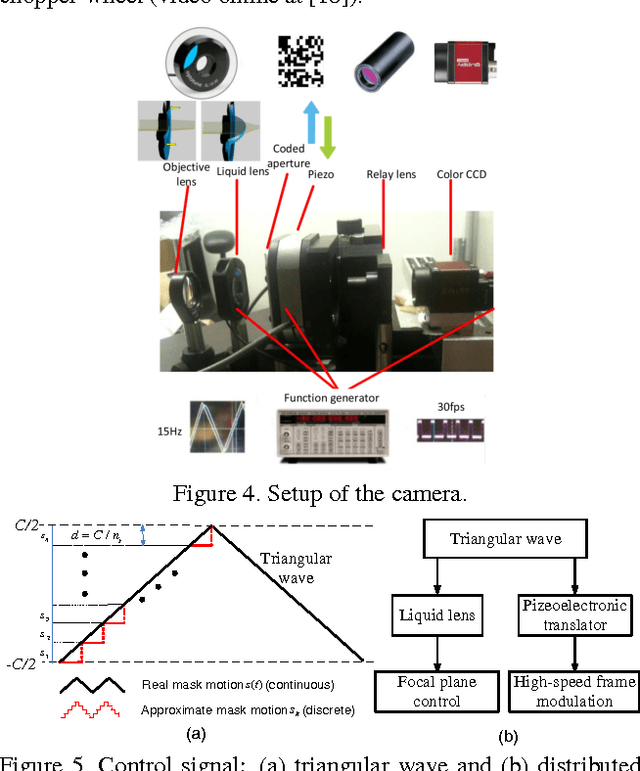
A simple and inexpensive (low-power and low-bandwidth) modification is made to a conventional off-the-shelf color video camera, from which we recover {multiple} color frames for each of the original measured frames, and each of the recovered frames can be focused at a different depth. The recovery of multiple frames for each measured frame is made possible via high-speed coding, manifested via translation of a single coded aperture; the inexpensive translation is constituted by mounting the binary code on a piezoelectric device. To simultaneously recover depth information, a {liquid} lens is modulated at high speed, via a variable voltage. Consequently, during the aforementioned coding process, the liquid lens allows the camera to sweep the focus through multiple depths. In addition to designing and implementing the camera, fast recovery is achieved by an anytime algorithm exploiting the group-sparsity of wavelet/DCT coefficients.
Sparse similarity-preserving hashing
Feb 16, 2014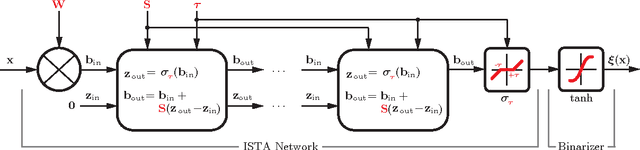
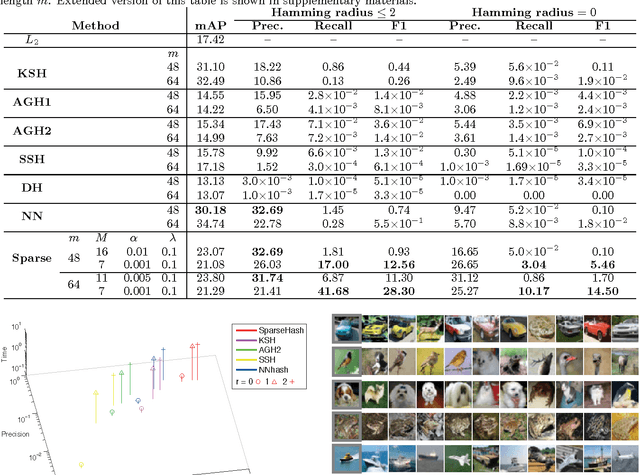

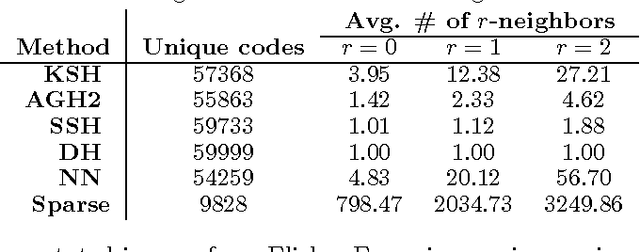
In recent years, a lot of attention has been devoted to efficient nearest neighbor search by means of similarity-preserving hashing. One of the plights of existing hashing techniques is the intrinsic trade-off between performance and computational complexity: while longer hash codes allow for lower false positive rates, it is very difficult to increase the embedding dimensionality without incurring in very high false negatives rates or prohibiting computational costs. In this paper, we propose a way to overcome this limitation by enforcing the hash codes to be sparse. Sparse high-dimensional codes enjoy from the low false positive rates typical of long hashes, while keeping the false negative rates similar to those of a shorter dense hashing scheme with equal number of degrees of freedom. We use a tailored feed-forward neural network for the hashing function. Extensive experimental evaluation involving visual and multi-modal data shows the benefits of the proposed method.