 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Amortized Pareto-Front Generators for Constrained Bi-Objective Convex Optimization
May 12, 2026Generating feasible Pareto fronts for constrained bi-objective continuous optimization is central to multi-criteria decision-making. Existing methods usually rely on iterative scalarization, evolutionary search, or problem-specific solvers, requiring repeated optimization for each instance. We introduce DIPS, an end-to-end framework that fine-tunes large language models as amortized Pareto-front generators for constrained bi-objective convex optimization. Given a textual problem description, DIPS directly outputs an ordered set of feasible continuous decision vectors approximating the Pareto front. To make continuous optimization compatible with autoregressive language modeling, DIPS combines a compact discretization scheme, Numerically Grounded Token Initialization for new numerical tokens, and Three-Phase Curriculum Optimization, which progressively aligns structural validity, feasibility, and Pareto-front quality. Across five families of constrained bi-objective convex problems, a fine-tuned 7B-parameter model achieves normalized hypervolume ratios of 95.29% to 98.18% relative to reference fronts. With vLLM-accelerated inference, DIPS solves one instance in as little as 0.16 seconds and outperforms general-purpose and reasoning LLM baselines under the evaluated setting. These results suggest that LLMs can serve as effective amortized generators for continuous Pareto-front approximation.
Dual-view Snapshot Compressive Imaging via Optical Flow Aided Recurrent Neural Network
Sep 11, 2021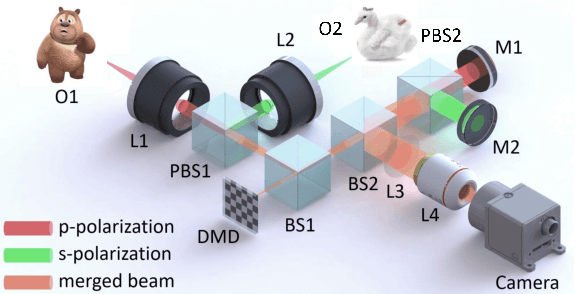
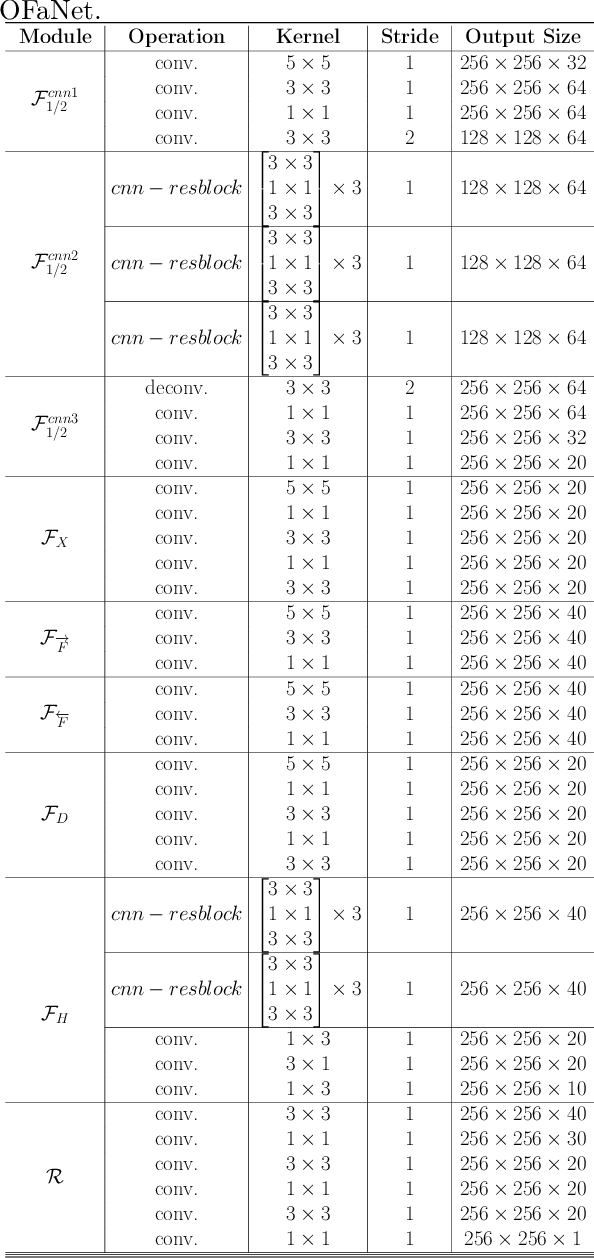
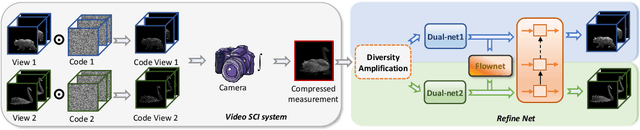
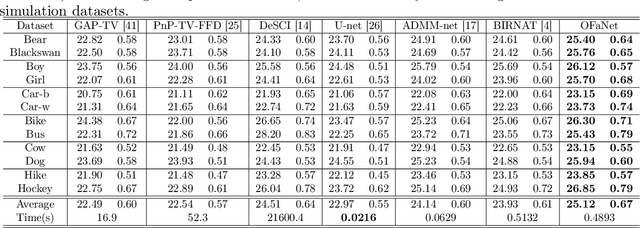
Dual-view snapshot compressive imaging (SCI) aims to capture videos from two field-of-views (FoVs) using a 2D sensor (detector) in a single snapshot, achieving joint FoV and temporal compressive sensing, and thus enjoying the advantages of low-bandwidth, low-power, and low-cost. However, it is challenging for existing model-based decoding algorithms to reconstruct each individual scene, which usually require exhaustive parameter tuning with extremely long running time for large scale data. In this paper, we propose an optical flow-aided recurrent neural network for dual video SCI systems, which provides high-quality decoding in seconds. Firstly, we develop a diversity amplification method to enlarge the differences between scenes of two FoVs, and design a deep convolutional neural network with dual branches to separate different scenes from the single measurement. Secondly, we integrate the bidirectional optical flow extracted from adjacent frames with the recurrent neural network to jointly reconstruct each video in a sequential manner. Extensive results on both simulation and real data demonstrate the superior performance of our proposed model in a short inference time. The code and data are available at https://github.com/RuiyingLu/OFaNet-for-Dual-view-SCI.
Memory-Efficient Network for Large-scale Video Compressive Sensing
Mar 05, 2021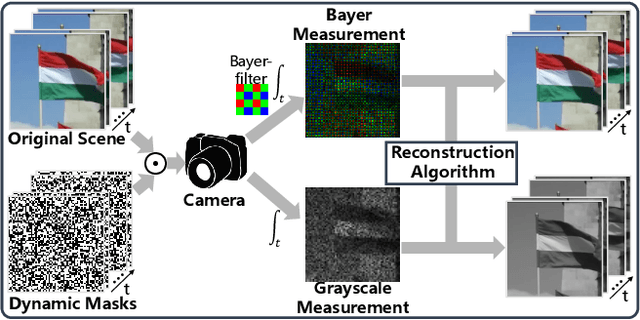
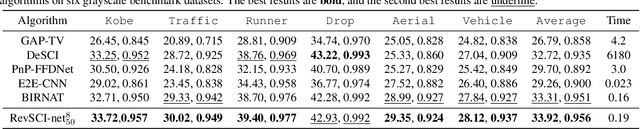

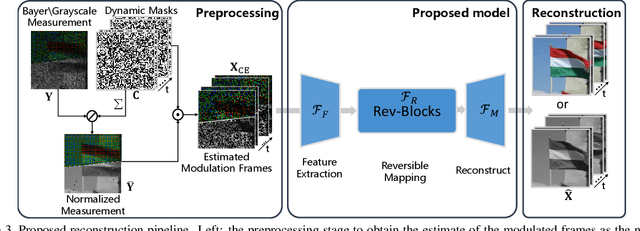
Video snapshot compressive imaging (SCI) captures a sequence of video frames in a single shot using a 2D detector. The underlying principle is that during one exposure time, different masks are imposed on the high-speed scene to form a compressed measurement. With the knowledge of masks, optimization algorithms or deep learning methods are employed to reconstruct the desired high-speed video frames from this snapshot measurement. Unfortunately, though these methods can achieve decent results, the long running time of optimization algorithms or huge training memory occupation of deep networks still preclude them in practical applications. In this paper, we develop a memory-efficient network for large-scale video SCI based on multi-group reversible 3D convolutional neural networks. In addition to the basic model for the grayscale SCI system, we take one step further to combine demosaicing and SCI reconstruction to directly recover color video from Bayer measurements. Extensive results on both simulation and real data captured by SCI cameras demonstrate that our proposed model outperforms previous state-of-the-art with less memory and thus can be used in large-scale problems. The code is at https://github.com/BoChenGroup/RevSCI-net.