 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDiff: combining Auto-encoder and Diffusion model for tabular data synthesizing
Oct 24, 2023Diffusion model has become a main paradigm for synthetic data generation in many subfields of modern machine learning, including computer vision, language model, or speech synthesis. In this paper, we leverage the power of diffusion model for generating synthetic tabular data. The heterogeneous features in tabular data have been main obstacles in tabular data synthesis, and we tackle this problem by employing the auto-encoder architecture. When compared with the state-of-the-art tabular synthesizers, the resulting synthetic tables from our model show nice statistical fidelities to the real data, and perform well in downstream tasks for machine learning utilities. We conducted the experiments over 15 publicly available datasets. Notably, our model adeptly captures the correlations among features, which has been a long-standing challenge in tabular data synthesis. Our code is available upon request and will be publicly released if paper is accepted.
Improve Deep Forest with Learnable Layerwise Augmentation Policy Schedule
Sep 16, 2023



As a modern ensemble technique, Deep Forest (DF) employs a cascading structure to construct deep models, providing stronger representational power compared to traditional decision forests. However, its greedy multi-layer learning procedure is prone to overfitting, limiting model effectiveness and generalizability. This paper presents an optimized Deep Forest, featuring learnable, layerwise data augmentation policy schedules. Specifically, We introduce the Cut Mix for Tabular data (CMT) augmentation technique to mitigate overfitting and develop a population-based search algorithm to tailor augmentation intensity for each layer. Additionally, we propose to incorporate outputs from intermediate layers into a checkpoint ensemble for more stable performance. Experimental results show that our method sets new state-of-the-art (SOTA) benchmarks in various tabular classification tasks, outperforming shallow tree ensembles, deep forests, deep neural network, and AutoML competitors. The learned policies also transfer effectively to Deep Forest variants, underscoring its potential for enhancing non-differentiable deep learning modules in tabular signal processing.
MissDiff: Training Diffusion Models on Tabular Data with Missing Values
Jul 02, 2023The diffusion model has shown remarkable performance in modeling data distributions and synthesizing data. However, the vanilla diffusion model requires complete or fully observed data for training. Incomplete data is a common issue in various real-world applications, including healthcare and finance, particularly when dealing with tabular datasets. This work presents a unified and principled diffusion-based framework for learning from data with missing values under various missing mechanisms. We first observe that the widely adopted "impute-then-generate" pipeline may lead to a biased learning objective. Then we propose to mask the regression loss of Denoising Score Matching in the training phase. We prove the proposed method is consistent in learning the score of data distributions, and the proposed training objective serves as an upper bound for the negative likelihood in certain cases. The proposed framework is evaluated on multiple tabular datasets using realistic and efficacious metrics and is demonstrated to outperform state-of-the-art diffusion model on tabular data with "impute-then-generate" pipeline by a large margin.
Utility Theory of Synthetic Data Generation
May 17, 2023Evaluating the utility of synthetic data is critical for measuring the effectiveness and efficiency of synthetic algorithms. Existing results focus on empirical evaluations of the utility of synthetic data, whereas the theoretical understanding of how utility is affected by synthetic data algorithms remains largely unexplored. This paper establishes utility theory from a statistical perspective, aiming to quantitatively assess the utility of synthetic algorithms based on a general metric. The metric is defined as the absolute difference in generalization between models trained on synthetic and original datasets. We establish analytical bounds for this utility metric to investigate critical conditions for the metric to converge. An intriguing result is that the synthetic feature distribution is not necessarily identical to the original one for the convergence of the utility metric as long as the model specification in downstream learning tasks is correct. Another important utility metric is model comparison based on synthetic data. Specifically, we establish sufficient conditions for synthetic data algorithms so that the ranking of generalization performances of models trained on the synthetic data is consistent with that from the original data. Finally, we conduct extensive experiments using non-parametric models and deep neural networks to validate our theoretical findings.
Tight Non-asymptotic Inference via Sub-Gaussian Intrinsic Moment Norm
Mar 13, 2023In non-asymptotic statistical inferences, variance-type parameters of sub-Gaussian distributions play a crucial role. However, direct estimation of these parameters based on the empirical moment generating function (MGF) is infeasible. To this end, we recommend using a sub-Gaussian intrinsic moment norm [Buldygin and Kozachenko (2000), Theorem 1.3] through maximizing a series of normalized moments. Importantly, the recommended norm can not only recover the exponential moment bounds for the corresponding MGFs, but also lead to tighter Hoeffding's sub-Gaussian concentration inequalities. In practice, {\color{black} we propose an intuitive way of checking sub-Gaussian data with a finite sample size by the sub-Gaussian plot}. Intrinsic moment norm can be robustly estimated via a simple plug-in approach. Our theoretical results are applied to non-asymptotic analysis, including the multi-armed bandit.
Statistical Theory of Differentially Private Marginal-based Data Synthesis Algorithms
Jan 25, 2023Marginal-based methods achieve promising performance in the synthetic data competition hosted by the National Institute of Standards and Technology (NIST). To deal with high-dimensional data, the distribution of synthetic data is represented by a probabilistic graphical model (e.g., a Bayesian network), while the raw data distribution is approximated by a collection of low-dimensional marginals. Differential privacy (DP) is guaranteed by introducing random noise to each low-dimensional marginal distribution. Despite its promising performance in practice, the statistical properties of marginal-based methods are rarely studied in the literature. In this paper, we study DP data synthesis algorithms based on Bayesian networks (BN) from a statistical perspective. We establish a rigorous accuracy guarantee for BN-based algorithms, where the errors are measured by the total variation (TV) distance or the $L^2$ distance. Related to downstream machine learning tasks, an upper bound for the utility error of the DP synthetic data is also derived. To complete the picture, we establish a lower bound for TV accuracy that holds for every $\epsilon$-DP synthetic data generator.
Double Matching Under Complementary Preferences
Jan 24, 2023



In this paper, we propose a new algorithm for addressing the problem of matching markets with complementary preferences, where agents' preferences are unknown a priori and must be learned from data. The presence of complementary preferences can lead to instability in the matching process, making this problem challenging to solve. To overcome this challenge, we formulate the problem as a bandit learning framework and propose the Multi-agent Multi-type Thompson Sampling (MMTS) algorithm. The algorithm combines the strengths of Thompson Sampling for exploration with a double matching technique to achieve a stable matching outcome. Our theoretical analysis demonstrates the effectiveness of MMTS as it is able to achieve stability at every matching step, satisfies the incentive-compatibility property, and has a sublinear Bayesian regret over time. Our approach provides a useful method for addressing complementary preferences in real-world scenarios.
Ranking Differential Privacy
Jan 02, 2023Rankings are widely collected in various real-life scenarios, leading to the leakage of personal information such as users' preferences on videos or news. To protect rankings, existing works mainly develop privacy protection on a single ranking within a set of ranking or pairwise comparisons of a ranking under the $\epsilon$-differential privacy. This paper proposes a novel notion called $\epsilon$-ranking differential privacy for protecting ranks. We establish the connection between the Mallows model (Mallows, 1957) and the proposed $\epsilon$-ranking differential privacy. This allows us to develop a multistage ranking algorithm to generate synthetic rankings while satisfying the developed $\epsilon$-ranking differential privacy. Theoretical results regarding the utility of synthetic rankings in the downstream tasks, including the inference attack and the personalized ranking tasks, are established. For the inference attack, we quantify how $\epsilon$ affects the estimation of the true ranking based on synthetic rankings. For the personalized ranking task, we consider varying privacy preferences among users and quantify how their privacy preferences affect the consistency in estimating the optimal ranking function. Extensive numerical experiments are carried out to verify the theoretical results and demonstrate the effectiveness of the proposed synthetic ranking algorithm.
On the Utility Recovery Incapability of Neural Net-based Differential Private Tabular Training Data Synthesizer under Privacy Deregulation
Nov 28, 2022



Devising procedures for auditing generative model privacy-utility tradeoff is an important yet unresolved problem in practice. Existing works concentrates on investigating the privacy constraint side effect in terms of utility degradation of the train on synthetic, test on real paradigm of synthetic data training. We push such understanding on privacy-utility tradeoff to next level by observing the privacy deregulation side effect on synthetic training data utility. Surprisingly, we discover the Utility Recovery Incapability of DP-CTGAN and PATE-CTGAN under privacy deregulation, raising concerns on their practical applications. The main message is Privacy Deregulation does NOT always imply Utility Recovery.
Improving Adversarial Robustness by Contrastive Guided Diffusion Process
Oct 18, 2022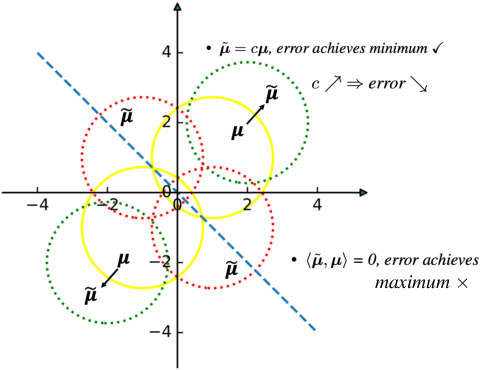
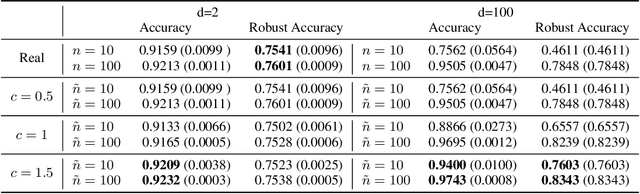
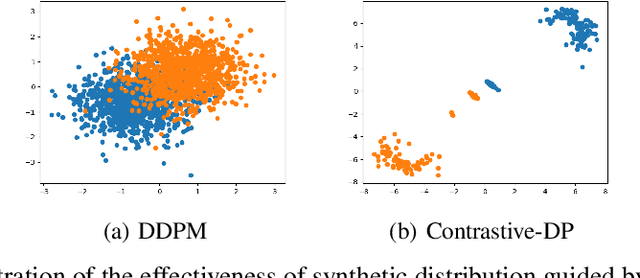
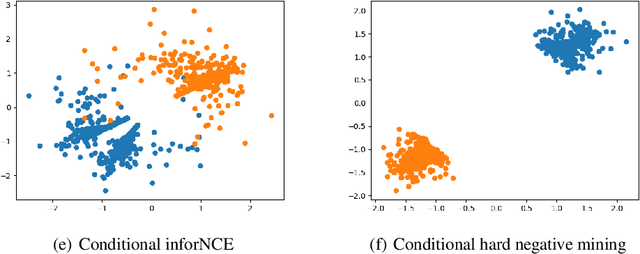
Synthetic data generation has become an emerging tool to help improve the adversarial robustness in classification tasks since robust learning requires a significantly larger amount of training samples compared with standard classification tasks. Among various deep generative models, the diffusion model has been shown to produce high-quality synthetic images and has achieved good performance in improving the adversarial robustness. However, diffusion-type methods are typically slow in data generation as compared with other generative models. Although different acceleration techniques have been proposed recently, it is also of great importance to study how to improve the sample efficiency of generated data for the downstream task. In this paper, we first analyze the optimality condition of synthetic distribution for achieving non-trivial robust accuracy. We show that enhancing the distinguishability among the generated data is critical for improving adversarial robustness. Thus, we propose the Contrastive-Guided Diffusion Process (Contrastive-DP), which adopts the contrastive loss to guide the diffusion model in data generation. We verify our theoretical results using simulations and demonstrate the good performance of Contrastive-DP on image datasets.