 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Overcomplete HMMs
Jun 28, 2018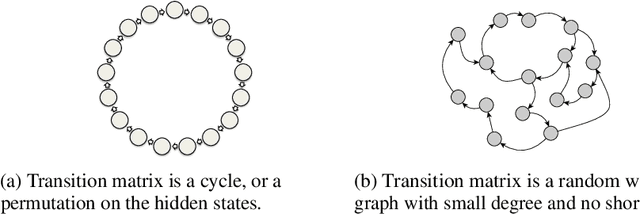
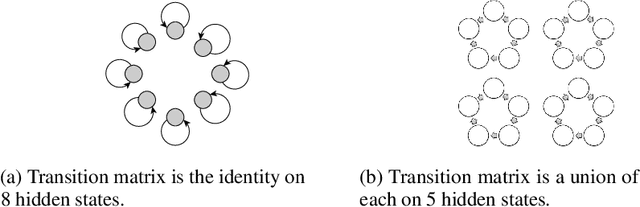
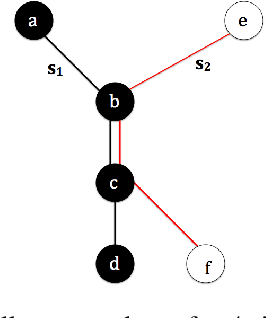
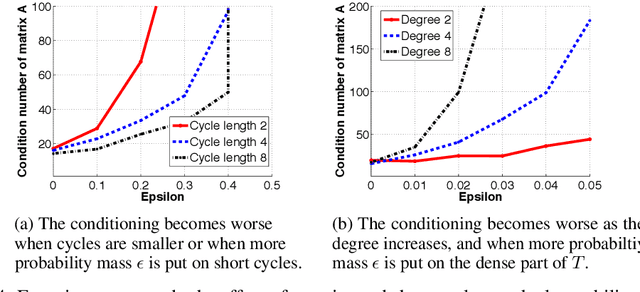
We study the problem of learning overcomplete HMMs---those that have many hidden states but a small output alphabet. Despite having significant practical importance, such HMMs are poorly understood with no known positive or negative results for efficient learning. In this paper, we present several new results---both positive and negative---which help define the boundaries between the tractable and intractable settings. Specifically, we show positive results for a large subclass of HMMs whose transition matrices are sparse, well-conditioned, and have small probability mass on short cycles. On the other hand, we show that learning is impossible given only a polynomial number of samples for HMMs with a small output alphabet and whose transition matrices are random regular graphs with large degree. We also discuss these results in the context of learning HMMs which can capture long-term dependencies.
Fast and Accurate Low-Rank Factorization of Compressively-Sensed Data
May 30, 2018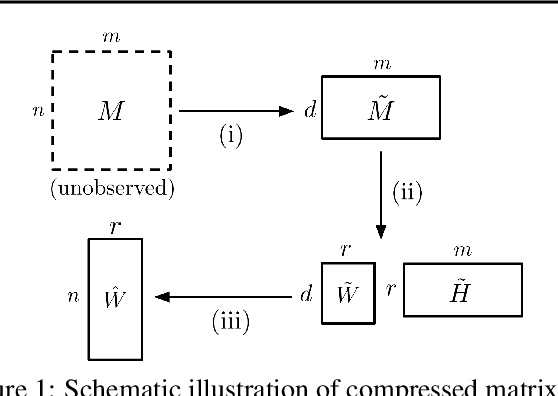
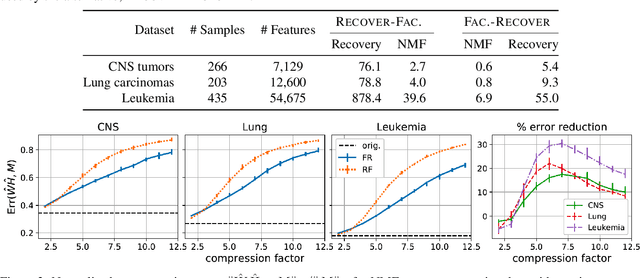
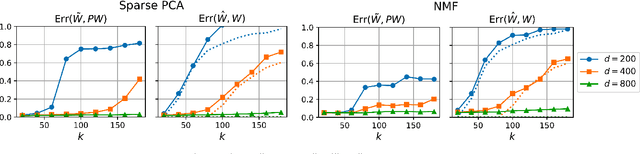
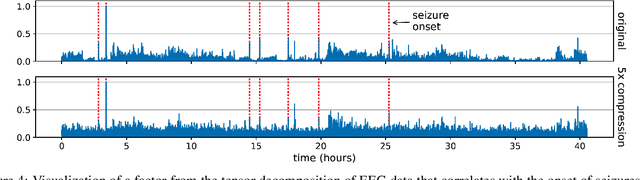
We consider the question of accurately and efficiently computing low-rank matrix or tensor factorizations given data compressed via random projections. This problem arises naturally in the many settings in which data is acquired via compressive sensing. We examine the approach of first performing factorization in the compressed domain, and then reconstructing the original high-dimensional factors from the recovered (compressed) factors. In both the tensor and matrix settings, we establish conditions under which this natural approach will provably recover the original factors. We support these theoretical results with experiments on synthetic data and demonstrate the practical applicability of our methods on real-world gene expression and EEG time series data.
Estimating Learnability in the Sublinear Data Regime
May 04, 2018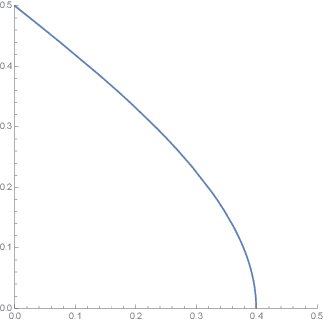
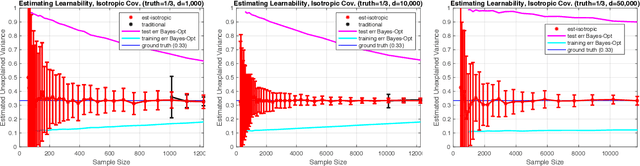
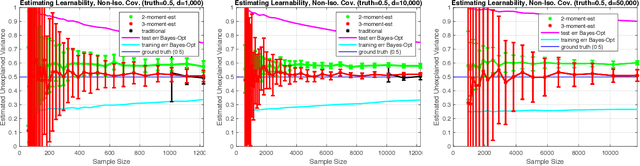
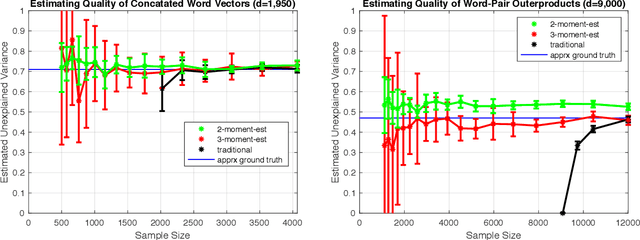
We consider the problem of estimating how well a model class is capable of fitting a distribution of labeled data. We show that it is often possible to accurately estimate this "learnability" even when given an amount of data that is too small to reliably learn any accurate model. Our first result applies to the setting where the data is drawn from a $d$-dimensional distribution with isotropic covariance, and the label of each datapoint is an arbitrary noisy function of the datapoint. In this setting, we show that with $O(\sqrt{d})$ samples, one can accurately estimate the fraction of the variance of the label that can be explained via the best linear function of the data. We extend these techniques to the setting of binary classification, where we show that in an analogous setting, the prediction error of the best linear classifier can be accurately estimated given $O(\sqrt{d})$ labeled samples. Note that in both the linear regression and binary classification settings, even if there is no noise in the labels, a sample size linear in the dimension, $d$, is required to \emph{learn} any function correlated with the underlying model. We further extend our estimation approach to the setting where the data distribution has an (unknown) arbitrary covariance matrix, allowing these techniques to be applied to settings where the model class consists of a linear function applied to a nonlinear embedding of the data. Finally, we demonstrate the practical viability of these approaches on synthetic and real data. This ability to estimate the explanatory value of a set of features (or dataset), even in the regime in which there is too little data to realize that explanatory value, may be relevant to the scientific and industrial settings for which data collection is expensive and there are many potentially relevant feature sets that could be collected.
Sketching Linear Classifiers over Data Streams
Apr 06, 2018
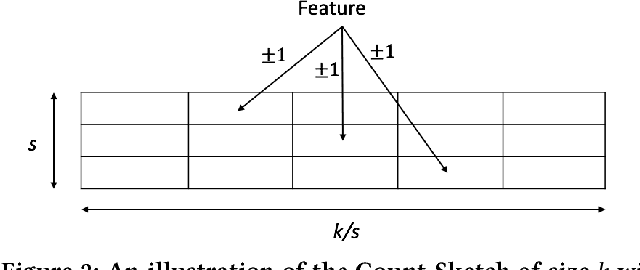
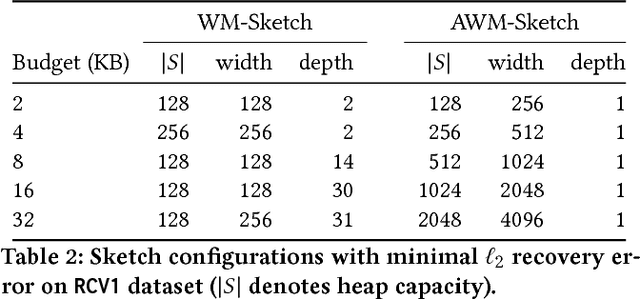
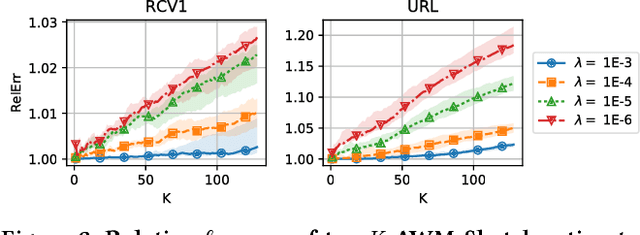
We introduce a new sub-linear space sketch---the Weight-Median Sketch---for learning compressed linear classifiers over data streams while supporting the efficient recovery of large-magnitude weights in the model. This enables memory-limited execution of several statistical analyses over streams, including online feature selection, streaming data explanation, relative deltoid detection, and streaming estimation of pointwise mutual information. Unlike related sketches that capture the most frequently-occurring features (or items) in a data stream, the Weight-Median Sketch captures the features that are most discriminative of one stream (or class) compared to another. The Weight-Median Sketch adopts the core data structure used in the Count-Sketch, but, instead of sketching counts, it captures sketched gradient updates to the model parameters. We provide a theoretical analysis that establishes recovery guarantees for batch and online learning, and demonstrate empirical improvements in memory-accuracy trade-offs over alternative memory-budgeted methods, including count-based sketches and feature hashing.
Recovering Structured Probability Matrices
Feb 06, 2018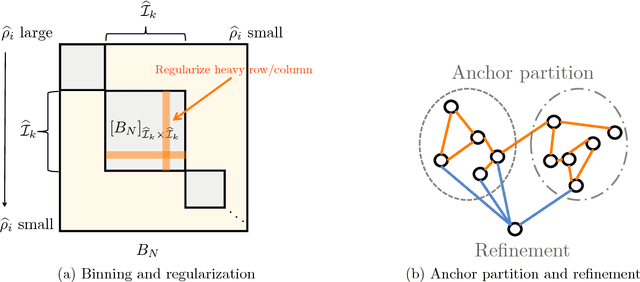
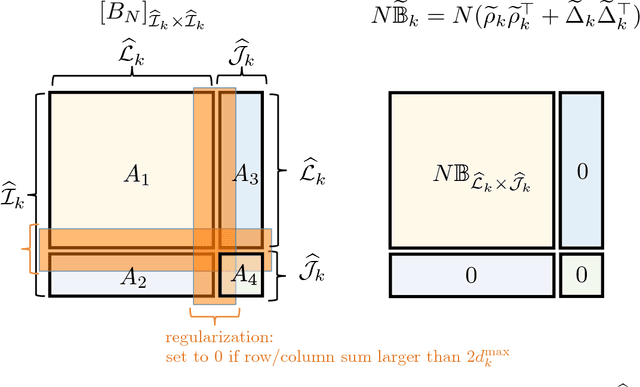
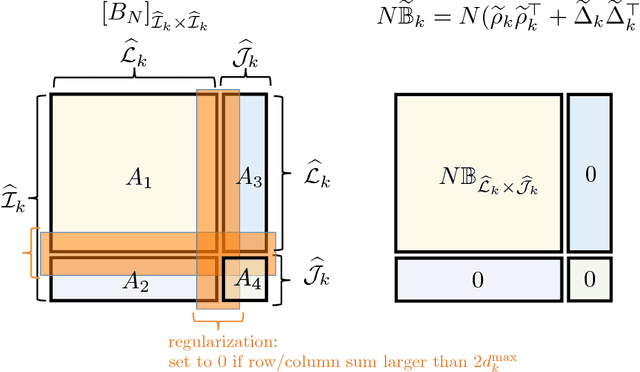
We consider the problem of accurately recovering a matrix B of size M by M , which represents a probability distribution over M2 outcomes, given access to an observed matrix of "counts" generated by taking independent samples from the distribution B. How can structural properties of the underlying matrix B be leveraged to yield computationally efficient and information theoretically optimal reconstruction algorithms? When can accurate reconstruction be accomplished in the sparse data regime? This basic problem lies at the core of a number of questions that are currently being considered by different communities, including building recommendation systems and collaborative filtering in the sparse data regime, community detection in sparse random graphs, learning structured models such as topic models or hidden Markov models, and the efforts from the natural language processing community to compute "word embeddings". Our results apply to the setting where B has a low rank structure. For this setting, we propose an efficient algorithm that accurately recovers the underlying M by M matrix using Theta(M) samples. This result easily translates to Theta(M) sample algorithms for learning topic models and learning hidden Markov Models. These linear sample complexities are optimal, up to constant factors, in an extremely strong sense: even testing basic properties of the underlying matrix (such as whether it has rank 1 or 2) requires Omega(M) samples. We provide an even stronger lower bound where distinguishing whether a sequence of observations were drawn from the uniform distribution over M observations versus being generated by an HMM with two hidden states requires Omega(M) observations. This precludes sublinear-sample hypothesis tests for basic properties, such as identity or uniformity, as well as sublinear sample estimators for quantities such as the entropy rate of HMMs.
Resilience: A Criterion for Learning in the Presence of Arbitrary Outliers
Nov 27, 2017
We introduce a criterion, resilience, which allows properties of a dataset (such as its mean or best low rank approximation) to be robustly computed, even in the presence of a large fraction of arbitrary additional data. Resilience is a weaker condition than most other properties considered so far in the literature, and yet enables robust estimation in a broader variety of settings. We provide new information-theoretic results on robust distribution learning, robust estimation of stochastic block models, and robust mean estimation under bounded $k$th moments. We also provide new algorithmic results on robust distribution learning, as well as robust mean estimation in $\ell_p$-norms. Among our proof techniques is a method for pruning a high-dimensional distribution with bounded $1$st moments to a stable "core" with bounded $2$nd moments, which may be of independent interest.
Learning Populations of Parameters
Nov 22, 2017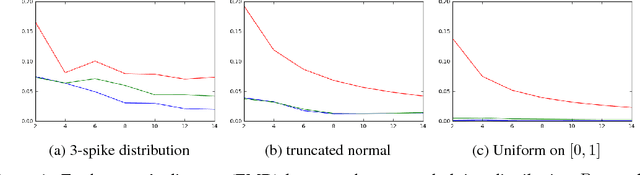
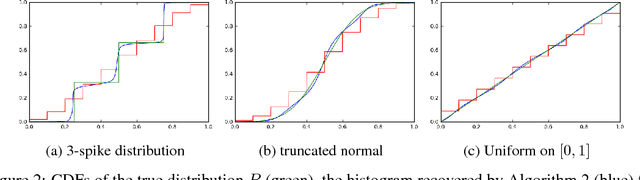
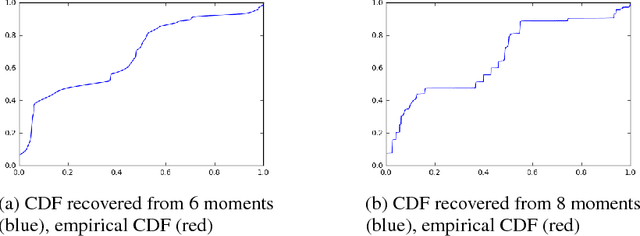
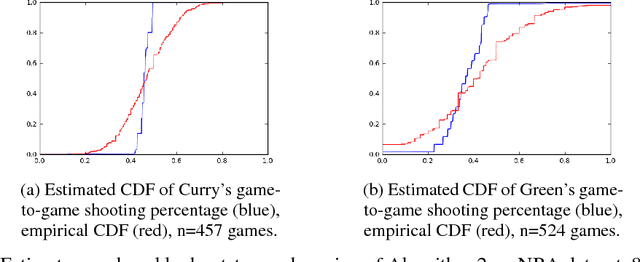
Consider the following estimation problem: there are $n$ entities, each with an unknown parameter $p_i \in [0,1]$, and we observe $n$ independent random variables, $X_1,\ldots,X_n$, with $X_i \sim $ Binomial$(t, p_i)$. How accurately can one recover the "histogram" (i.e. cumulative density function) of the $p_i$'s? While the empirical estimates would recover the histogram to earth mover distance $\Theta(\frac{1}{\sqrt{t}})$ (equivalently, $\ell_1$ distance between the CDFs), we show that, provided $n$ is sufficiently large, we can achieve error $O(\frac{1}{t})$ which is information theoretically optimal. We also extend our results to the multi-dimensional parameter case, capturing settings where each member of the population has multiple associated parameters. Beyond the theoretical results, we demonstrate that the recovery algorithm performs well in practice on a variety of datasets, providing illuminating insights into several domains, including politics, sports analytics, and variation in the gender ratio of offspring.
Learning Discrete Distributions from Untrusted Batches
Nov 22, 2017We consider the problem of learning a discrete distribution in the presence of an $\epsilon$ fraction of malicious data sources. Specifically, we consider the setting where there is some underlying distribution, $p$, and each data source provides a batch of $\ge k$ samples, with the guarantee that at least a $(1-\epsilon)$ fraction of the sources draw their samples from a distribution with total variation distance at most $\eta$ from $p$. We make no assumptions on the data provided by the remaining $\epsilon$ fraction of sources--this data can even be chosen as an adversarial function of the $(1-\epsilon)$ fraction of "good" batches. We provide two algorithms: one with runtime exponential in the support size, $n$, but polynomial in $k$, $1/\epsilon$ and $1/\eta$ that takes $O((n+k)/\epsilon^2)$ batches and recovers $p$ to error $O(\eta+\epsilon/\sqrt{k})$. This recovery accuracy is information theoretically optimal, to constant factors, even given an infinite number of data sources. Our second algorithm applies to the $\eta = 0$ setting and also achieves an $O(\epsilon/\sqrt{k})$ recover guarantee, though it runs in $\mathrm{poly}((nk)^k)$ time. This second algorithm, which approximates a certain tensor via a rank-1 tensor minimizing $\ell_1$ distance, is surprising in light of the hardness of many low-rank tensor approximation problems, and may be of independent interest.
Orthogonalized ALS: A Theoretically Principled Tensor Decomposition Algorithm for Practical Use
Sep 23, 2017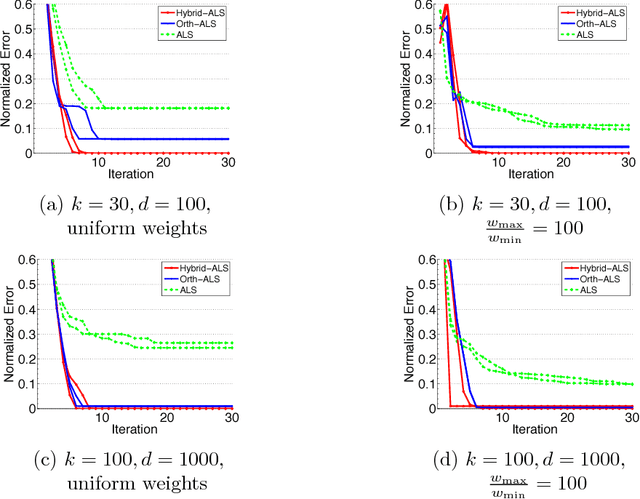
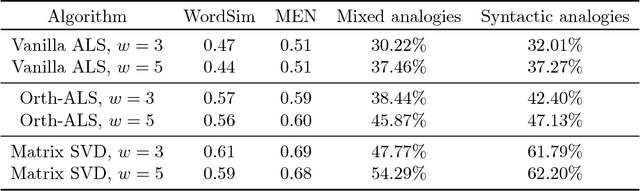
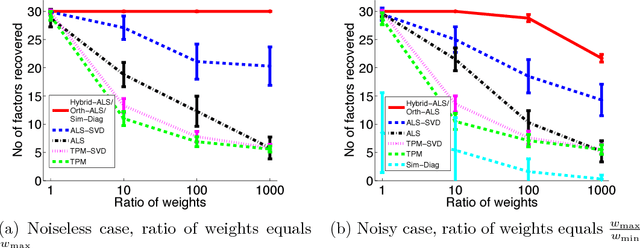
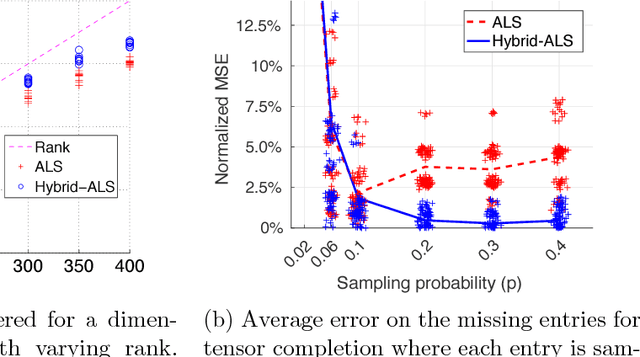
The popular Alternating Least Squares (ALS) algorithm for tensor decomposition is efficient and easy to implement, but often converges to poor local optima---particularly when the weights of the factors are non-uniform. We propose a modification of the ALS approach that is as efficient as standard ALS, but provably recovers the true factors with random initialization under standard incoherence assumptions on the factors of the tensor. We demonstrate the significant practical superiority of our approach over traditional ALS for a variety of tasks on synthetic data---including tensor factorization on exact, noisy and over-complete tensors, as well as tensor completion---and for computing word embeddings from a third-order word tri-occurrence tensor.
A Data Prism: Semi-Verified Learning in the Small-Alpha Regime
Aug 09, 2017We consider a model of unreliable or crowdsourced data where there is an underlying set of $n$ binary variables, each evaluator contributes a (possibly unreliable or adversarial) estimate of the values of some subset of $r$ of the variables, and the learner is given the true value of a constant number of variables. We show that, provided an $\alpha$-fraction of the evaluators are "good" (either correct, or with independent noise rate $p < 1/2$), then the true values of a $(1-\epsilon)$ fraction of the $n$ underlying variables can be deduced as long as $\alpha > 1/(2-2p)^r$. This setting can be viewed as an instance of the semi-verified learning model introduced in [CSV17], which explores the tradeoff between the number of items evaluated by each worker and the fraction of good evaluators. Our results require the number of evaluators to be extremely large, $>n^r$, although our algorithm runs in linear time, $O_{r,\epsilon}(n)$, given query access to the large dataset of evaluations. This setting and results can also be viewed as examining a general class of semi-adversarial CSPs with a planted assignment. This parameter regime where the fraction of reliable data is small, is relevant to a number of practical settings. For example, settings where one has a large dataset of customer preferences, with each customer specifying preferences for a small (constant) number of items, and the goal is to ascertain the preferences of a specific demographic of interest. Our results show that this large dataset (which lacks demographic information) can be leveraged together with the preferences of the demographic of interest for a constant number of randomly selected items, to recover an accurate estimate of the entire set of preferences. In this sense, our results can be viewed as a "data prism" allowing one to extract the behavior of specific cohorts from a large, mixed, dataset.