 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Face Verification Nets For Pain Intensity Regression
Jun 01, 2017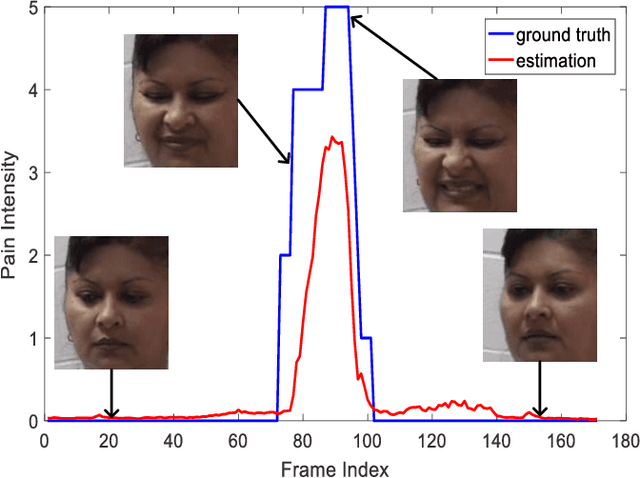
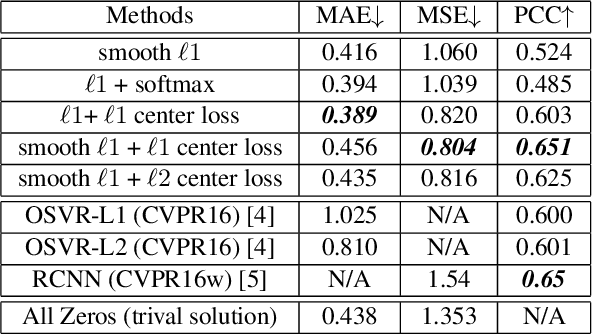
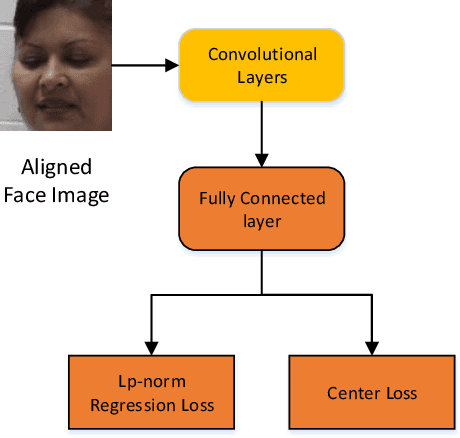
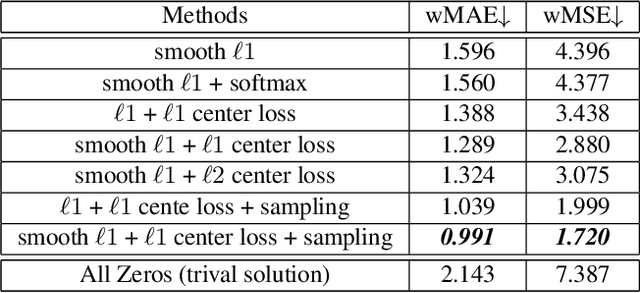
Limited labeled data are available for the research of estimating facial expression intensities. For instance, the ability to train deep networks for automated pain assessment is limited by small datasets with labels of patient-reported pain intensities. Fortunately, fine-tuning from a data-extensive pre-trained domain, such as face verification, can alleviate this problem. In this paper, we propose a network that fine-tunes a state-of-the-art face verification network using a regularized regression loss and additional data with expression labels. In this way, the expression intensity regression task can benefit from the rich feature representations trained on a huge amount of data for face verification. The proposed regularized deep regressor is applied to estimate the pain expression intensity and verified on the widely-used UNBC-McMaster Shoulder-Pain dataset, achieving the state-of-the-art performance. A weighted evaluation metric is also proposed to address the imbalance issue of different pain intensities.
Real-time Teaching Cues for Automated Surgical Coaching
Apr 24, 2017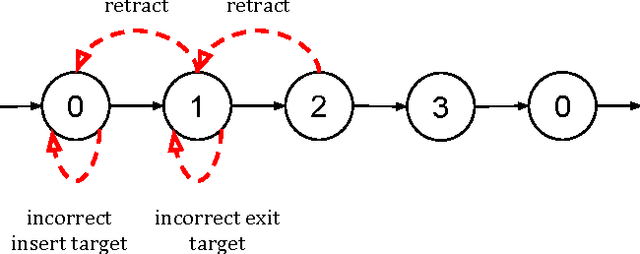
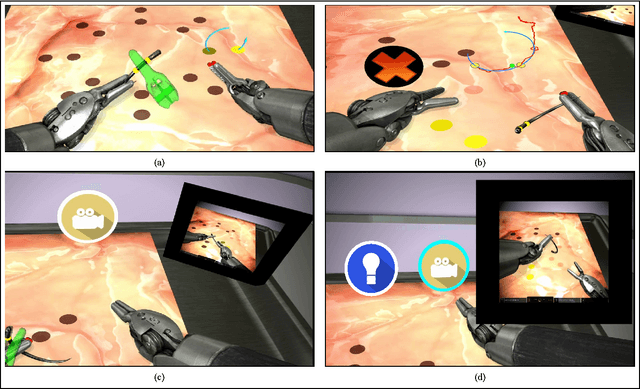
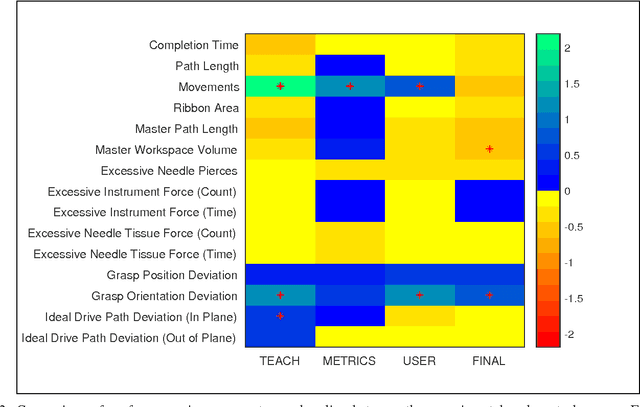
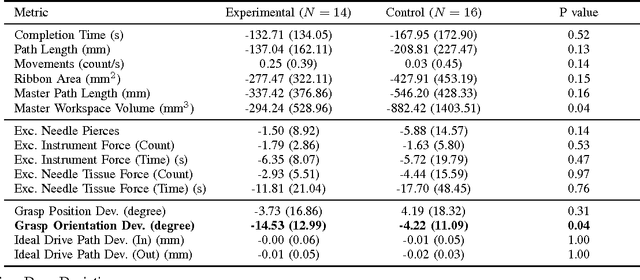
With introduction of new technologies in the operating room like the da Vinci Surgical System, training surgeons to use them effectively and efficiently is crucial in the delivery of better patient care. Coaching by an expert surgeon is effective in teaching relevant technical skills, but current methods to deliver effective coaching are limited and not scalable. We present a virtual reality simulation-based framework for automated virtual coaching in surgical education. We implement our framework within the da Vinci Skills Simulator. We provide three coaching modes ranging from a hands-on teacher (continuous guidance) to a handsoff guide (assistance upon request). We present six teaching cues targeted at critical learning elements of a needle passing task, which are shown to the user based on the coaching mode. These cues are graphical overlays which guide the user, inform them about sub-par performance, and show relevant video demonstrations. We evaluated our framework in a pilot randomized controlled trial with 16 subjects in each arm. In a post-study questionnaire, participants reported high comprehension of feedback, and perceived improvement in performance. After three practice repetitions of the task, the control arm (independent learning) showed better motion efficiency whereas the experimental arm (received real-time coaching) had better performance of learning elements (as per the ACS Resident Skills Curriculum). We observed statistically higher improvement in the experimental group based on one of the metrics (related to needle grasp orientation). In conclusion, we developed an automated coach that provides real-time cues for surgical training and demonstrated its feasibility.
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
Apr 20, 2017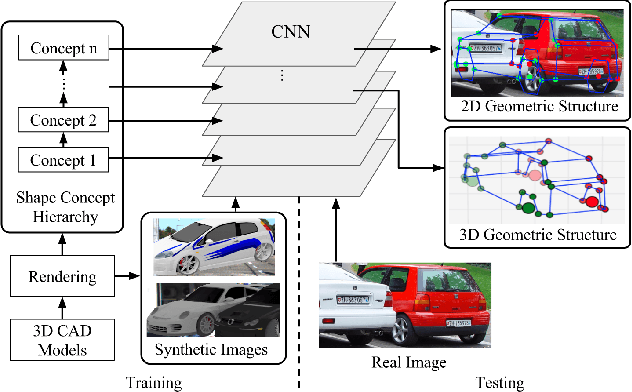
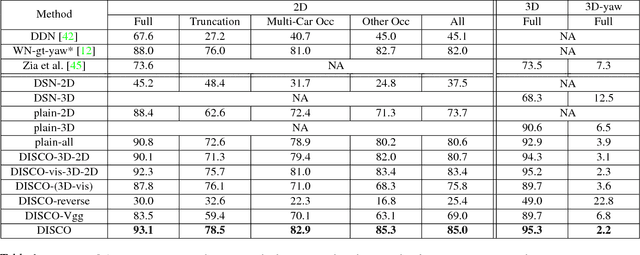
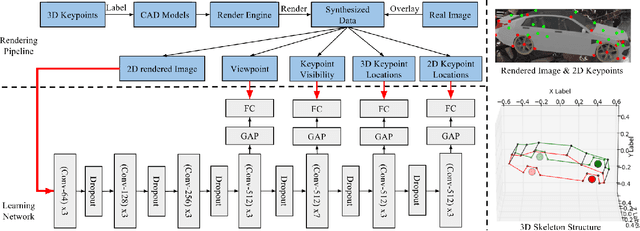
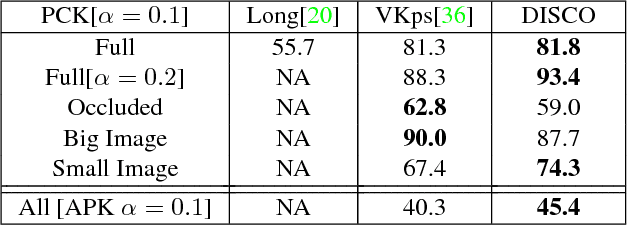
Monocular 3D object parsing is highly desirable in various scenarios including occlusion reasoning and holistic scene interpretation. We present a deep convolutional neural network (CNN) architecture to localize semantic parts in 2D image and 3D space while inferring their visibility states, given a single RGB image. Our key insight is to exploit domain knowledge to regularize the network by deeply supervising its hidden layers, in order to sequentially infer intermediate concepts associated with the final task. To acquire training data in desired quantities with ground truth 3D shape and relevant concepts, we render 3D object CAD models to generate large-scale synthetic data and simulate challenging occlusion configurations between objects. We train the network only on synthetic data and demonstrate state-of-the-art performances on real image benchmarks including an extended version of KITTI, PASCAL VOC, PASCAL3D+ and IKEA for 2D and 3D keypoint localization and instance segmentation. The empirical results substantiate the utility of our deep supervision scheme by demonstrating effective transfer of knowledge from synthetic data to real images, resulting in less overfitting compared to standard end-to-end training.
User Experience of the CoSTAR System for Instruction of Collaborative Robots
Mar 23, 2017
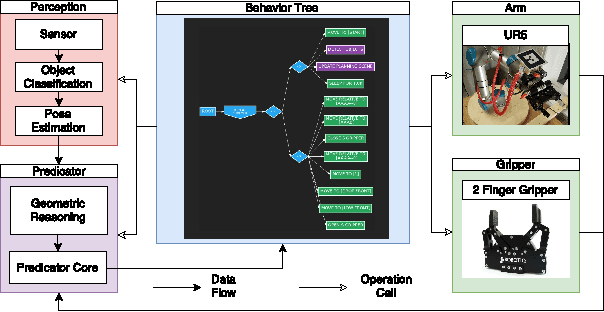
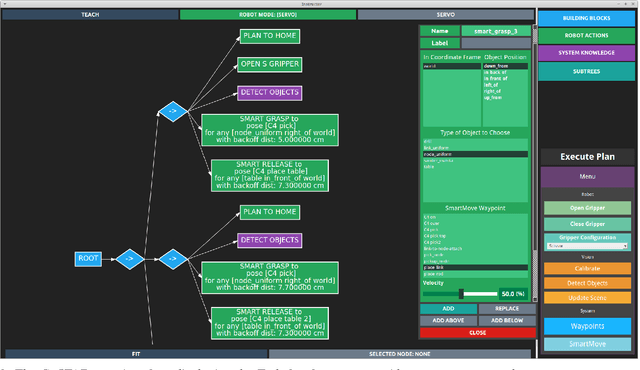

How can we enable novice users to create effective task plans for collaborative robots? Must there be a tradeoff between generalizability and ease of use? To answer these questions, we conducted a user study with the CoSTAR system, which integrates perception and reasoning into a Behavior Tree-based task plan editor. In our study, we ask novice users to perform simple pick-and-place assembly tasks under varying perception and planning capabilities. Our study shows that users found Behavior Trees to be an effective way of specifying task plans. Furthermore, users were also able to more quickly, effectively, and generally author task plans with the addition of CoSTAR's planning, perception, and reasoning capabilities. Despite these improvements, concepts associated with these capabilities were rated by users as less usable, and our results suggest a direction for further refinement.
Combining Neural Networks and Tree Search for Task and Motion Planning in Challenging Environments
Mar 22, 2017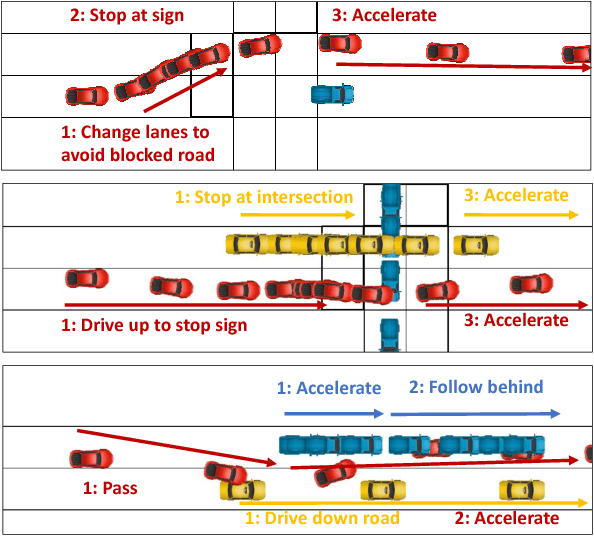
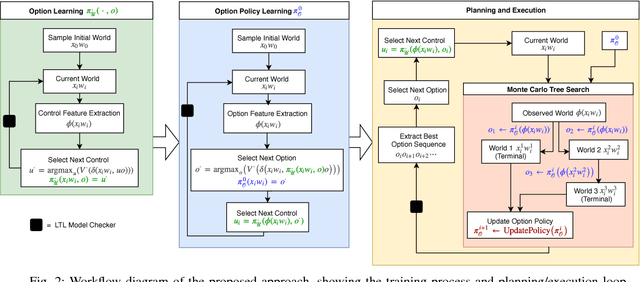
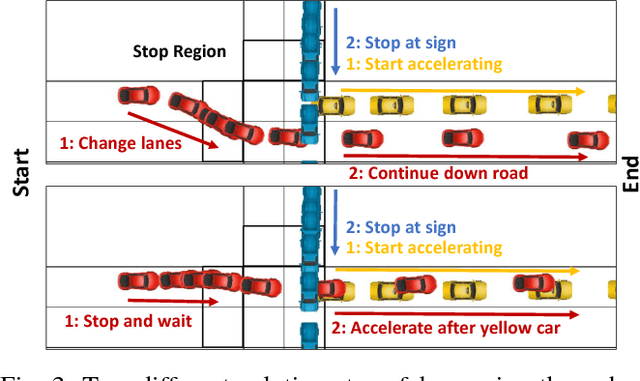
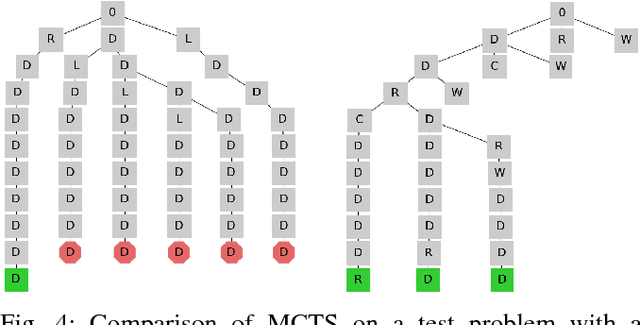
We consider task and motion planning in complex dynamic environments for problems expressed in terms of a set of Linear Temporal Logic (LTL) constraints, and a reward function. We propose a methodology based on reinforcement learning that employs deep neural networks to learn low-level control policies as well as task-level option policies. A major challenge in this setting, both for neural network approaches and classical planning, is the need to explore future worlds of a complex and interactive environment. To this end, we integrate Monte Carlo Tree Search with hierarchical neural net control policies trained on expressive LTL specifications. This paper investigates the ability of neural networks to learn both LTL constraints and control policies in order to generate task plans in complex environments. We demonstrate our approach in a simulated autonomous driving setting, where a vehicle must drive down a road in traffic, avoid collisions, and navigate an intersection, all while obeying given rules of the road.
CoSTAR: Instructing Collaborative Robots with Behavior Trees and Vision
Nov 18, 2016
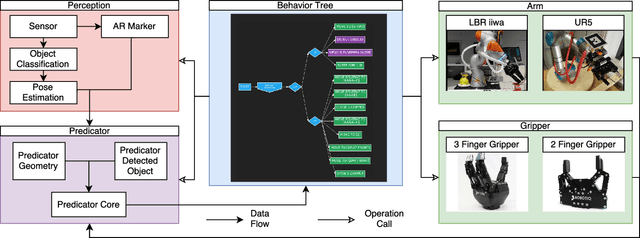
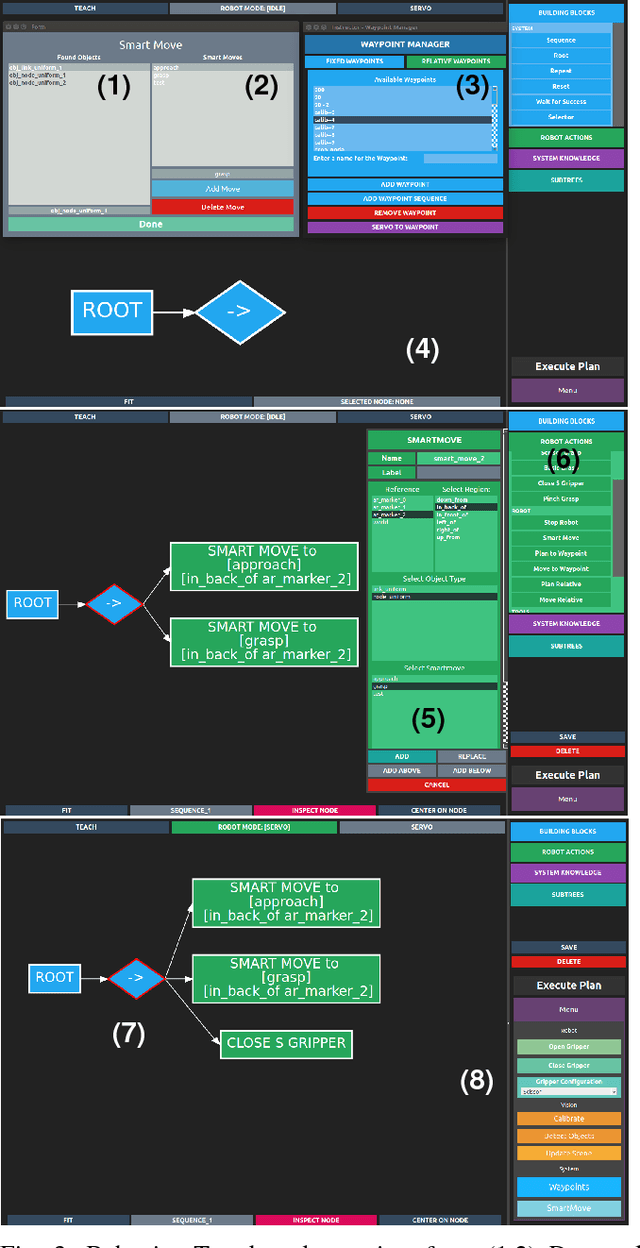
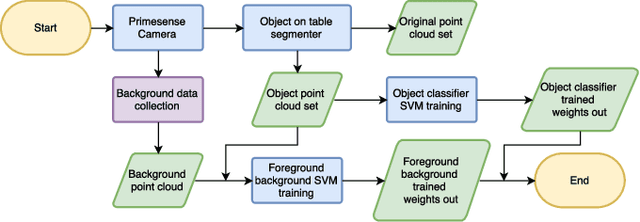
For collaborative robots to become useful, end users who are not robotics experts must be able to instruct them to perform a variety of tasks. With this goal in mind, we developed a system for end-user creation of robust task plans with a broad range of capabilities. CoSTAR: the Collaborative System for Task Automation and Recognition is our winning entry in the 2016 KUKA Innovation Award competition at the Hannover Messe trade show, which this year focused on Flexible Manufacturing. CoSTAR is unique in how it creates natural abstractions that use perception to represent the world in a way users can both understand and utilize to author capable and robust task plans. Our Behavior Tree-based task editor integrates high-level information from known object segmentation and pose estimation with spatial reasoning and robot actions to create robust task plans. We describe the cross-platform design and implementation of this system on multiple industrial robots and evaluate its suitability for a wide variety of use cases.
Temporal Convolutional Networks for Action Segmentation and Detection
Nov 16, 2016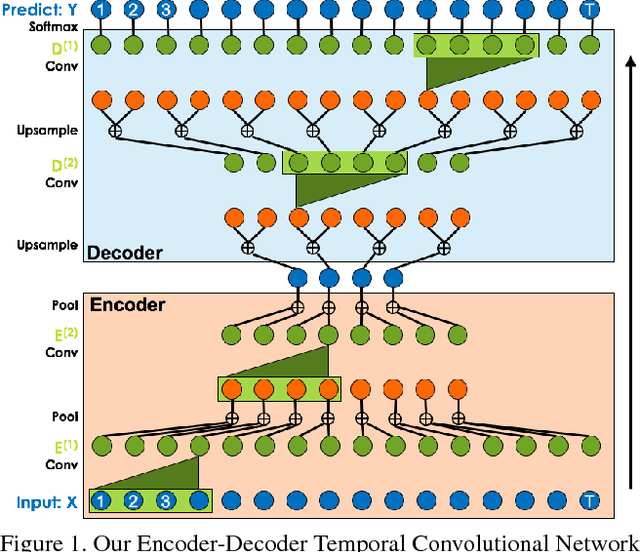
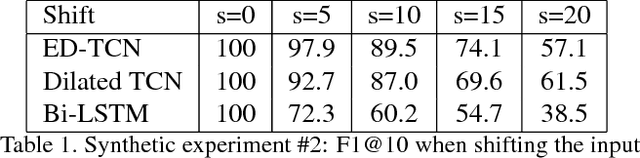
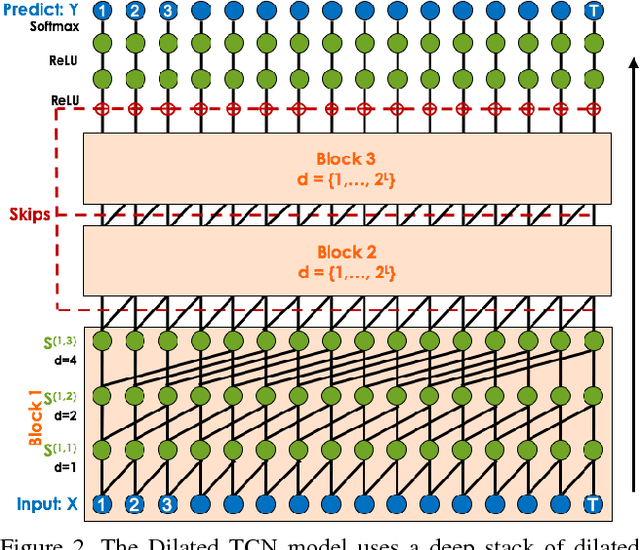
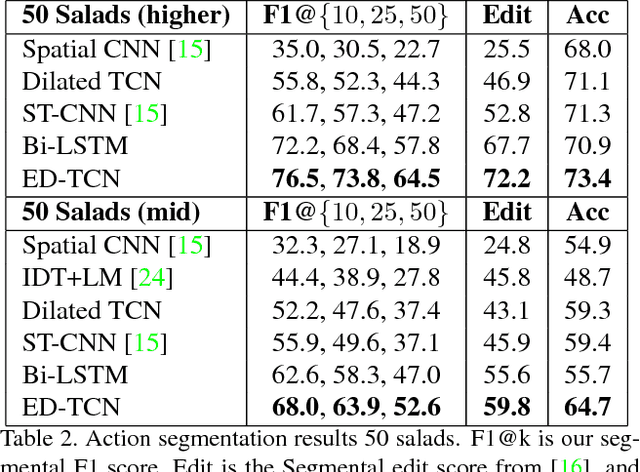
The ability to identify and temporally segment fine-grained human actions throughout a video is crucial for robotics, surveillance, education, and beyond. Typical approaches decouple this problem by first extracting local spatiotemporal features from video frames and then feeding them into a temporal classifier that captures high-level temporal patterns. We introduce a new class of temporal models, which we call Temporal Convolutional Networks (TCNs), that use a hierarchy of temporal convolutions to perform fine-grained action segmentation or detection. Our Encoder-Decoder TCN uses pooling and upsampling to efficiently capture long-range temporal patterns whereas our Dilated TCN uses dilated convolutions. We show that TCNs are capable of capturing action compositions, segment durations, and long-range dependencies, and are over a magnitude faster to train than competing LSTM-based Recurrent Neural Networks. We apply these models to three challenging fine-grained datasets and show large improvements over the state of the art.
Anatomically Constrained Video-CT Registration via the V-IMLOP Algorithm
Oct 25, 2016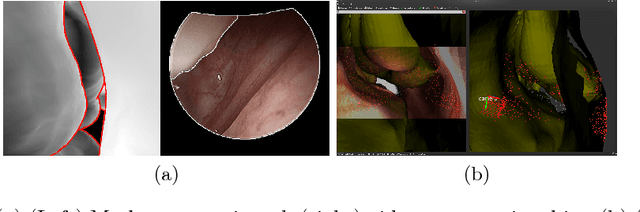
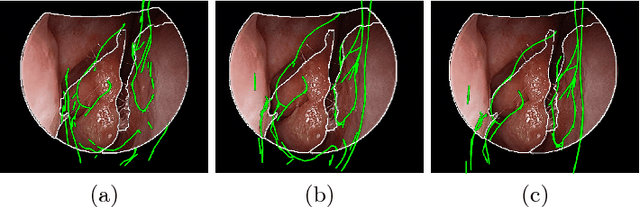
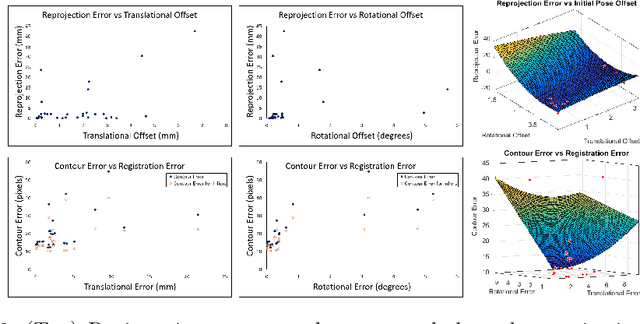
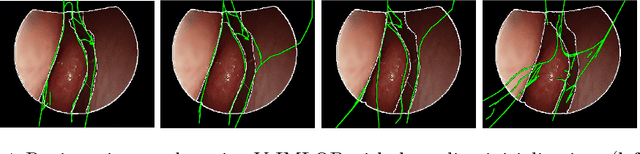
Functional endoscopic sinus surgery (FESS) is a surgical procedure used to treat acute cases of sinusitis and other sinus diseases. FESS is fast becoming the preferred choice of treatment due to its minimally invasive nature. However, due to the limited field of view of the endoscope, surgeons rely on navigation systems to guide them within the nasal cavity. State of the art navigation systems report registration accuracy of over 1mm, which is large compared to the size of the nasal airways. We present an anatomically constrained video-CT registration algorithm that incorporates multiple video features. Our algorithm is robust in the presence of outliers. We also test our algorithm on simulated and in-vivo data, and test its accuracy against degrading initializations.
* 8 pages, 4 figures, MICCAI
Segmental Spatiotemporal CNNs for Fine-grained Action Segmentation
Sep 30, 2016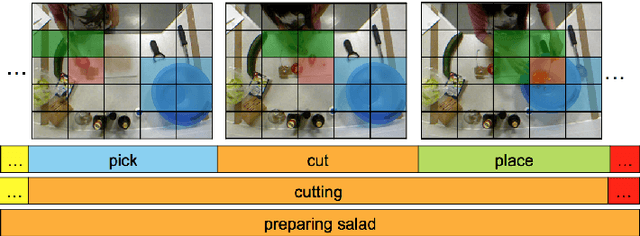
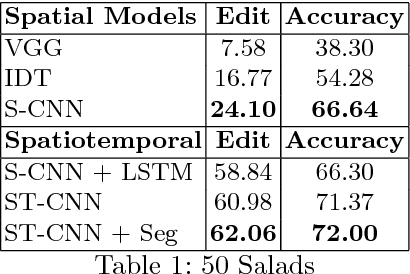
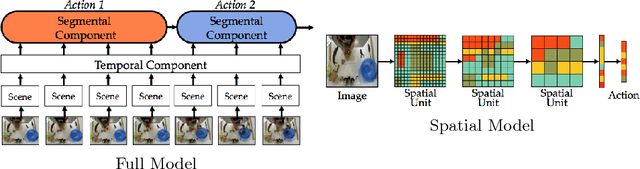
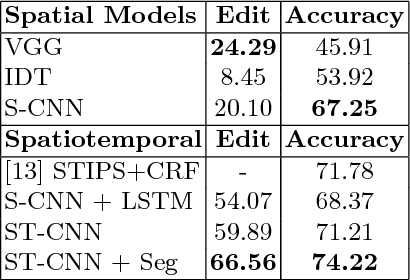
Joint segmentation and classification of fine-grained actions is important for applications of human-robot interaction, video surveillance, and human skill evaluation. However, despite substantial recent progress in large-scale action classification, the performance of state-of-the-art fine-grained action recognition approaches remains low. We propose a model for action segmentation which combines low-level spatiotemporal features with a high-level segmental classifier. Our spatiotemporal CNN is comprised of a spatial component that uses convolutional filters to capture information about objects and their relationships, and a temporal component that uses large 1D convolutional filters to capture information about how object relationships change across time. These features are used in tandem with a semi-Markov model that models transitions from one action to another. We introduce an efficient constrained segmental inference algorithm for this model that is orders of magnitude faster than the current approach. We highlight the effectiveness of our Segmental Spatiotemporal CNN on cooking and surgical action datasets for which we observe substantially improved performance relative to recent baseline methods.
Temporal Convolutional Networks: A Unified Approach to Action Segmentation
Aug 29, 2016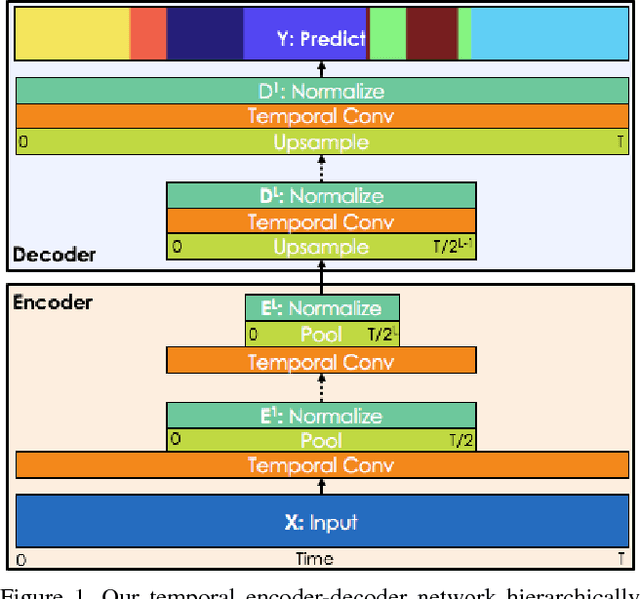
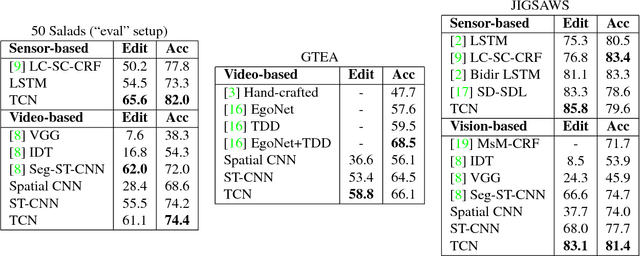
The dominant paradigm for video-based action segmentation is composed of two steps: first, for each frame, compute low-level features using Dense Trajectories or a Convolutional Neural Network that encode spatiotemporal information locally, and second, input these features into a classifier that captures high-level temporal relationships, such as a Recurrent Neural Network (RNN). While often effective, this decoupling requires specifying two separate models, each with their own complexities, and prevents capturing more nuanced long-range spatiotemporal relationships. We propose a unified approach, as demonstrated by our Temporal Convolutional Network (TCN), that hierarchically captures relationships at low-, intermediate-, and high-level time-scales. Our model achieves superior or competitive performance using video or sensor data on three public action segmentation datasets and can be trained in a fraction of the time it takes to train an RNN.