 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Distillation of Image Representations into Point Clouds for Autonomous Driving
Oct 26, 2023



Self-supervised image networks can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. However, self-supervised 3D networks on lidar data do not perform as well for now. A few methods therefore propose to distill high-quality self-supervised 2D features into 3D networks. The most recent ones doing so on autonomous driving data show promising results. Yet, a performance gap persists between these distilled features and fully-supervised ones. In this work, we revisit 2D-to-3D distillation. First, we propose, for semantic segmentation, a simple approach that leads to a significant improvement compared to prior 3D distillation methods. Second, we show that distillation in high capacity 3D networks is key to reach high quality 3D features. This actually allows us to significantly close the gap between unsupervised distilled 3D features and fully-supervised ones. Last, we show that our high-quality distilled representations can also be used for open-vocabulary segmentation and background/foreground discovery.
BEVContrast: Self-Supervision in BEV Space for Automotive Lidar Point Clouds
Oct 26, 2023



We present a surprisingly simple and efficient method for self-supervision of 3D backbone on automotive Lidar point clouds. We design a contrastive loss between features of Lidar scans captured in the same scene. Several such approaches have been proposed in the literature from PointConstrast, which uses a contrast at the level of points, to the state-of-the-art TARL, which uses a contrast at the level of segments, roughly corresponding to objects. While the former enjoys a great simplicity of implementation, it is surpassed by the latter, which however requires a costly pre-processing. In BEVContrast, we define our contrast at the level of 2D cells in the Bird's Eye View plane. Resulting cell-level representations offer a good trade-off between the point-level representations exploited in PointContrast and segment-level representations exploited in TARL: we retain the simplicity of PointContrast (cell representations are cheap to compute) while surpassing the performance of TARL in downstream semantic segmentation.
Unsupervised Object Localization in the Era of Self-Supervised ViTs: A Survey
Oct 19, 2023The recent enthusiasm for open-world vision systems show the high interest of the community to perform perception tasks outside of the closed-vocabulary benchmark setups which have been so popular until now. Being able to discover objects in images/videos without knowing in advance what objects populate the dataset is an exciting prospect. But how to find objects without knowing anything about them? Recent works show that it is possible to perform class-agnostic unsupervised object localization by exploiting self-supervised pre-trained features. We propose here a survey of unsupervised object localization methods that discover objects in images without requiring any manual annotation in the era of self-supervised ViTs. We gather links of discussed methods in the repository https://github.com/valeoai/Awesome-Unsupervised-Object-Localization.
You Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
Apr 23, 2023We propose SeedAL, a method to seed active learning for efficient annotation of 3D point clouds for semantic segmentation. Active Learning (AL) iteratively selects relevant data fractions to annotate within a given budget, but requires a first fraction of the dataset (a 'seed') to be already annotated to estimate the benefit of annotating other data fractions. We first show that the choice of the seed can significantly affect the performance of many AL methods. We then propose a method for automatically constructing a seed that will ensure good performance for AL. Assuming that images of the point clouds are available, which is common, our method relies on powerful unsupervised image features to measure the diversity of the point clouds. It selects the point clouds for the seed by optimizing the diversity under an annotation budget, which can be done by solving a linear optimization problem. Our experiments demonstrate the effectiveness of our approach compared to random seeding and existing methods on both the S3DIS and SemanticKitti datasets. Code is available at \url{https://github.com/nerminsamet/seedal}.
SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation
Apr 06, 2023



Learning models on one labeled dataset that generalize well on another domain is a difficult task, as several shifts might happen between the data domains. This is notably the case for lidar data, for which models can exhibit large performance discrepancies due for instance to different lidar patterns or changes in acquisition conditions. This paper addresses the corresponding Unsupervised Domain Adaptation (UDA) task for semantic segmentation. To mitigate this problem, we introduce an unsupervised auxiliary task of learning an implicit underlying surface representation simultaneously on source and target data. As both domains share the same latent representation, the model is forced to accommodate discrepancies between the two sources of data. This novel strategy differs from classical minimization of statistical divergences or lidar-specific state-of-the-art domain adaptation techniques. Our experiments demonstrate that our method achieves a better performance than the current state of the art in synthetic-to-real and real-to-real scenarios.
Using a Waffle Iron for Automotive Point Cloud Semantic Segmentation
Jan 24, 2023Semantic segmentation of point clouds in autonomous driving datasets requires techniques that can process large numbers of points over large field of views. Today, most deep networks designed for this task exploit 3D sparse convolutions to reduce memory and computational loads. The best methods then further exploit specificities of rotating lidar sampling patterns to further improve the performance, e.g., cylindrical voxels, or range images (for feature fusion from multiple point cloud representations). In contrast, we show that one can build a well-performing point-based backbone free of these specialized tools. This backbone, WaffleIron, relies heavily on generic MLPs and dense 2D convolutions, making it easy to implement, and contains just a few parameters easy to tune. Despite its simplicity, our experiments on SemanticKITTI and nuScenes show that WaffleIron competes with the best methods designed specifically for these autonomous driving datasets. Hence, WaffleIron is a strong, easy-to-implement, baseline for semantic segmentation of sparse outdoor point clouds.
RangeViT: Towards Vision Transformers for 3D Semantic Segmentation in Autonomous Driving
Jan 24, 2023Casting semantic segmentation of outdoor LiDAR point clouds as a 2D problem, e.g., via range projection, is an effective and popular approach. These projection-based methods usually benefit from fast computations and, when combined with techniques which use other point cloud representations, achieve state-of-the-art results. Today, projection-based methods leverage 2D CNNs but recent advances in computer vision show that vision transformers (ViTs) have achieved state-of-the-art results in many image-based benchmarks. In this work, we question if projection-based methods for 3D semantic segmentation can benefit from these latest improvements on ViTs. We answer positively but only after combining them with three key ingredients: (a) ViTs are notoriously hard to train and require a lot of training data to learn powerful representations. By preserving the same backbone architecture as for RGB images, we can exploit the knowledge from long training on large image collections that are much cheaper to acquire and annotate than point clouds. We reach our best results with pre-trained ViTs on large image datasets. (b) We compensate ViTs' lack of inductive bias by substituting a tailored convolutional stem for the classical linear embedding layer. (c) We refine pixel-wise predictions with a convolutional decoder and a skip connection from the convolutional stem to combine low-level but fine-grained features of the the convolutional stem with the high-level but coarse predictions of the ViT encoder. With these ingredients, we show that our method, called RangeViT, outperforms existing projection-based methods on nuScenes and SemanticKITTI. We provide the implementation code at https://github.com/valeoai/rangevit.
Unsupervised Object Localization: Observing the Background to Discover Objects
Dec 15, 2022Recent advances in self-supervised visual representation learning have paved the way for unsupervised methods tackling tasks such as object discovery and instance segmentation. However, discovering objects in an image with no supervision is a very hard task; what are the desired objects, when to separate them into parts, how many are there, and of what classes? The answers to these questions depend on the tasks and datasets of evaluation. In this work, we take a different approach and propose to look for the background instead. This way, the salient objects emerge as a by-product without any strong assumption on what an object should be. We propose FOUND, a simple model made of a single $conv1\times1$ initialized with coarse background masks extracted from self-supervised patch-based representations. After fast training and refining these seed masks, the model reaches state-of-the-art results on unsupervised saliency detection and object discovery benchmarks. Moreover, we show that our approach yields good results in the unsupervised semantic segmentation retrieval task. The code to reproduce our results is available at https://github.com/valeoai/FOUND.
ALSO: Automotive Lidar Self-supervision by Occupancy estimation
Dec 13, 2022



We propose a new self-supervised method for pre-training the backbone of deep perception models operating on point clouds. The core idea is to train the model on a pretext task which is the reconstruction of the surface on which the 3D points are sampled, and to use the underlying latent vectors as input to the perception head. The intuition is that if the network is able to reconstruct the scene surface, given only sparse input points, then it probably also captures some fragments of semantic information, that can be used to boost an actual perception task. This principle has a very simple formulation, which makes it both easy to implement and widely applicable to a large range of 3D sensors and deep networks performing semantic segmentation or object detection. In fact, it supports a single-stream pipeline, as opposed to most contrastive learning approaches, allowing training on limited resources. We conducted extensive experiments on various autonomous driving datasets, involving very different kinds of lidars, for both semantic segmentation and object detection. The results show the effectiveness of our method to learn useful representations without any annotation, compared to existing approaches. Code is available at https://github.com/valeoai/ALSO
Take One Gram of Neural Features, Get Enhanced Group Robustness
Aug 26, 2022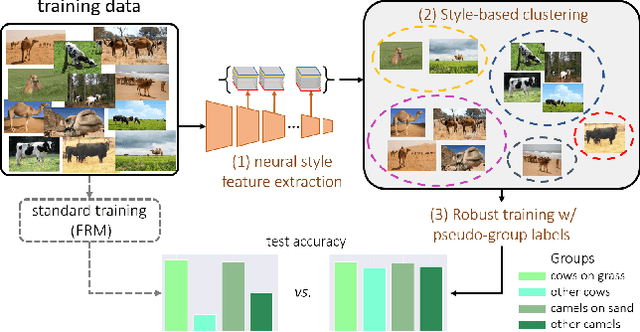
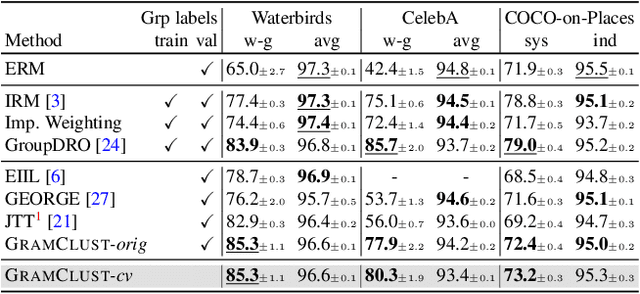
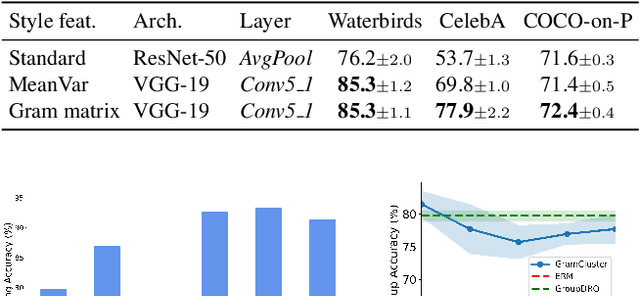

Predictive performance of machine learning models trained with empirical risk minimization (ERM) can degrade considerably under distribution shifts. The presence of spurious correlations in training datasets leads ERM-trained models to display high loss when evaluated on minority groups not presenting such correlations. Extensive attempts have been made to develop methods improving worst-group robustness. However, they require group information for each training input or at least, a validation set with group labels to tune their hyperparameters, which may be expensive to get or unknown a priori. In this paper, we address the challenge of improving group robustness without group annotation during training or validation. To this end, we propose to partition the training dataset into groups based on Gram matrices of features extracted by an ``identification'' model and to apply robust optimization based on these pseudo-groups. In the realistic context where no group labels are available, our experiments show that our approach not only improves group robustness over ERM but also outperforms all recent baselines