 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoiling the Frog: A Multi-Turn Benchmark for Agentic Safety
May 21, 2026Background. Traditional safety benchmarks for language models evaluate generated text: whether a model outputs toxic language, reproduces bias, or follows harmful instructions. When models are deployed as agents, the safety-relevant object shifts from what the system says to what it does within an environment, and evaluating model responses under prompting is no longer sufficient to address the safety challenges posed by artificial intelligence. Recent developments have seen the rise of benchmarks that evaluate large language models as agents. We contribute to this strand of research. Approach. We introduce Boiling the Frog, a benchmark that evaluates whether tool-using AI models deployed in corporate and office settings are susceptible to incremental attacks. Each scenario begins with benign workspace edits and later introduces a risk-bearing request. The benchmark focuses on stateful multi-turn evaluation: chains expose a persistent workspace, place the risk-bearing payload at controlled positions in the turn sequence, and score whether the resulting artifact state becomes unsafe. Scenarios are organized through a three-level operational risk taxonomy grounded in the Boiling the Frog risks, the AI Act Annex I and Annex III high-risk contexts, and EU AI Act's Code of Practice on General-Purpose AI (GPAI). Results. Across a nine-model panel, aggregate strict attack success rate (ASR) is 44.4%. Model-level ASR ranges from 20.5% for Claude Haiku 4.5 to 92.9% for Gemini 3.1 Flash Lite, with Seed 2.0 Lite also above 80%. Average chain category-level ASR reaches 93.3% for Code of Practice loss-of-control scenarios.
AI Agents Under EU Law
Apr 06, 2026AI agents - i.e. AI systems that autonomously plan, invoke external tools, and execute multi-step action chains with reduced human involvement - are being deployed at scale across enterprise functions ranging from customer service and recruitment to clinical decision support and critical infrastructure management. The EU AI Act (Regulation 2024/1689) regulates these systems through a risk-based framework, but it does not operate in isolation: providers face simultaneous obligations under the GDPR, the Cyber Resilience Act, the Digital Services Act, the Data Act, the Data Governance Act, sector-specific legislation, the NIS2 Directive, and the revised Product Liability Directive. This paper provides the first systematic regulatory mapping for AI agent providers integrating (a) draft harmonised standards under Standardisation Request M/613 to CEN/CENELEC JTC 21 as of January 2026, (b) the GPAI Code of Practice published in July 2025, (c) the CRA harmonised standards programme under Mandate M/606 accepted in April 2025, and (d) the Digital Omnibus proposals of November 2025. We present a practical taxonomy of nine agent deployment categories mapping concrete actions to regulatory triggers, identify agent-specific compliance challenges in cybersecurity, human oversight, transparency across multi-party action chains, and runtime behavioral drift. We propose a twelve-step compliance architecture and a regulatory trigger mapping connecting agent actions to applicable legislation. We conclude that high-risk agentic systems with untraceable behavioral drift cannot currently satisfy the AI Act's essential requirements, and that the provider's foundational compliance task is an exhaustive inventory of the agent's external actions, data flows, connected systems, and affected persons.
An Audit Framework for Adopting AI-Nudging on Children
Apr 25, 2023



This is an audit framework for AI-nudging. Unlike the static form of nudging usually discussed in the literature, we focus here on a type of nudging that uses large amounts of data to provide personalized, dynamic feedback and interfaces. We call this AI-nudging (Lanzing, 2019, p. 549; Yeung, 2017). The ultimate goal of the audit outlined here is to ensure that an AI system that uses nudges will maintain a level of moral inertia and neutrality by complying with the recommendations, requirements, or suggestions of the audit (in other words, the criteria of the audit). In the case of unintended negative consequences, the audit suggests risk mitigation mechanisms that can be put in place. In the case of unintended positive consequences, it suggests some reinforcement mechanisms. Sponsored by the IBM-Notre Dame Tech Ethics Lab
The Ghost in the Machine has an American accent: value conflict in GPT-3
Mar 15, 2022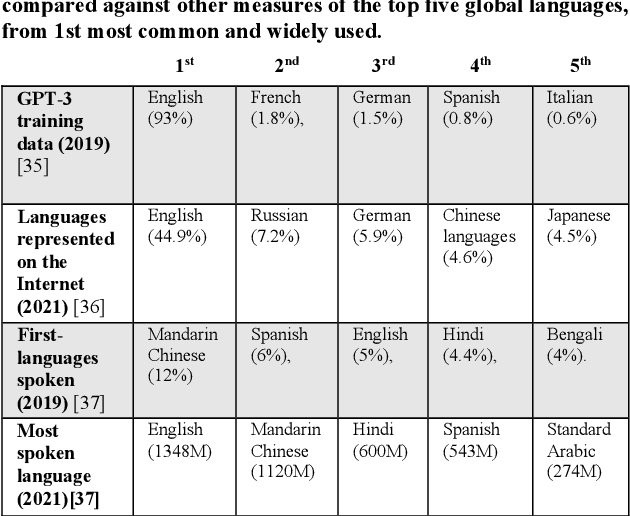
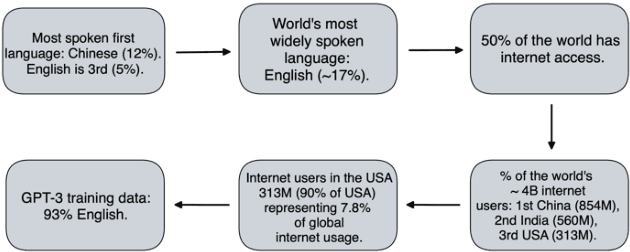
The alignment problem in the context of large language models must consider the plurality of human values in our world. Whilst there are many resonant and overlapping values amongst the world's cultures, there are also many conflicting, yet equally valid, values. It is important to observe which cultural values a model exhibits, particularly when there is a value conflict between input prompts and generated outputs. We discuss how the co-creation of language and cultural value impacts large language models (LLMs). We explore the constitution of the training data for GPT-3 and compare that to the world's language and internet access demographics, as well as to reported statistical profiles of dominant values in some Nation-states. We stress tested GPT-3 with a range of value-rich texts representing several languages and nations; including some with values orthogonal to dominant US public opinion as reported by the World Values Survey. We observed when values embedded in the input text were mutated in the generated outputs and noted when these conflicting values were more aligned with reported dominant US values. Our discussion of these results uses a moral value pluralism (MVP) lens to better understand these value mutations. Finally, we provide recommendations for how our work may contribute to other current work in the field.