 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEHAVE: Dataset and Method for Tracking Human Object Interactions
Apr 14, 2022
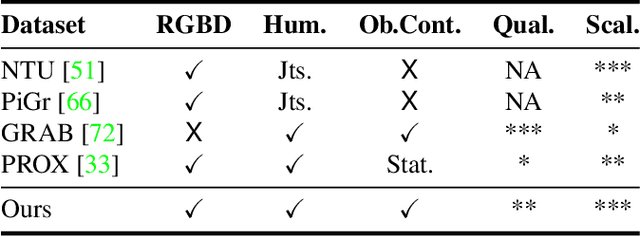


Modelling interactions between humans and objects in natural environments is central to many applications including gaming, virtual and mixed reality, as well as human behavior analysis and human-robot collaboration. This challenging operation scenario requires generalization to vast number of objects, scenes, and human actions. Unfortunately, there exist no such dataset. Moreover, this data needs to be acquired in diverse natural environments, which rules out 4D scanners and marker based capture systems. We present BEHAVE dataset, the first full body human- object interaction dataset with multi-view RGBD frames and corresponding 3D SMPL and object fits along with the annotated contacts between them. We record around 15k frames at 5 locations with 8 subjects performing a wide range of interactions with 20 common objects. We use this data to learn a model that can jointly track humans and objects in natural environments with an easy-to-use portable multi-camera setup. Our key insight is to predict correspondences from the human and the object to a statistical body model to obtain human-object contacts during interactions. Our approach can record and track not just the humans and objects but also their interactions, modeled as surface contacts, in 3D. Our code and data can be found at: http://virtualhumans.mpi-inf.mpg.de/behave
* Accepted at CVPR'22
CHORE: Contact, Human and Object REconstruction from a single RGB image
Apr 05, 2022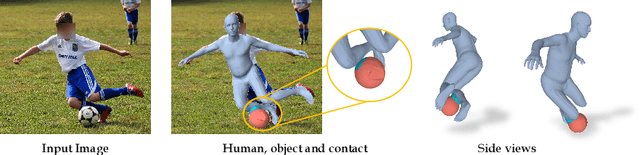
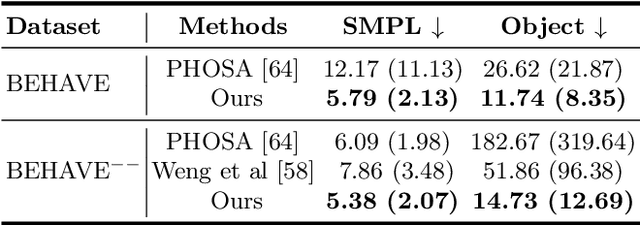
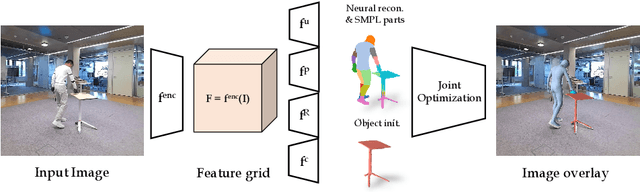
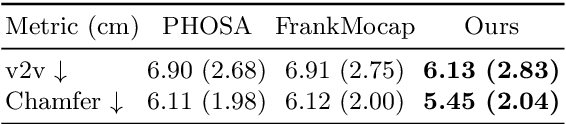
While most works in computer vision and learning have focused on perceiving 3D humans from single images in isolation, in this work we focus on capturing 3D humans interacting with objects. The problem is extremely challenging due to heavy occlusions between human and object, diverse interaction types and depth ambiguity. In this paper, we introduce CHORE, a novel method that learns to jointly reconstruct human and object from a single image. CHORE takes inspiration from recent advances in implicit surface learning and classical model-based fitting. We compute a neural reconstruction of human and object represented implicitly with two unsigned distance fields, and additionally predict a correspondence field to a parametric body as well as an object pose field. This allows us to robustly fit a parametric body model and a 3D object template, while reasoning about interactions. Furthermore, prior pixel-aligned implicit learning methods use synthetic data and make assumptions that are not met in real data. We propose a simple yet effective depth-aware scaling that allows more efficient shape learning on real data. Our experiments show that our joint reconstruction learned with the proposed strategy significantly outperforms the SOTA. Our code and models will be released to foster future research in this direction.
A Deeper Look into DeepCap
Nov 20, 2021
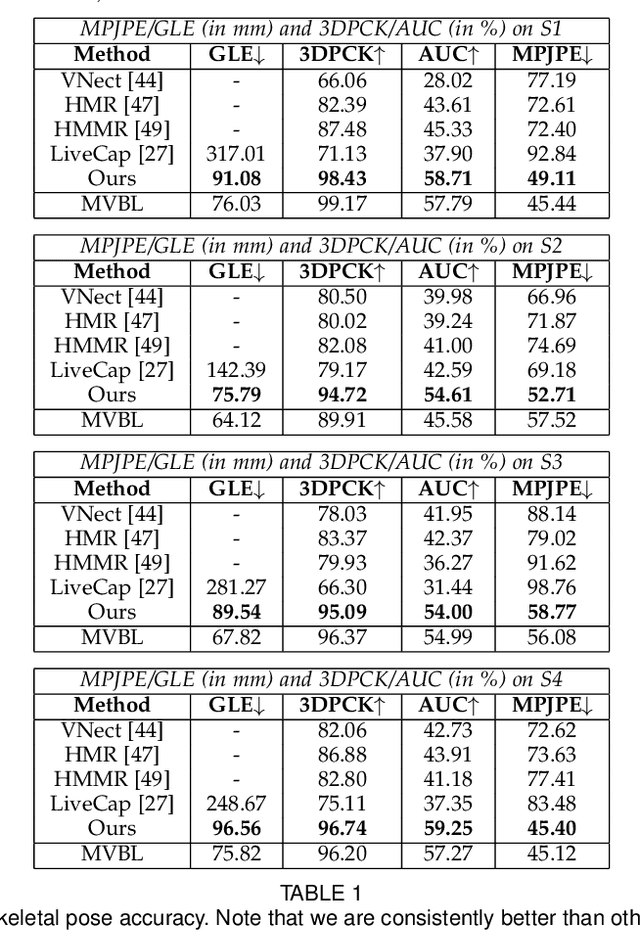
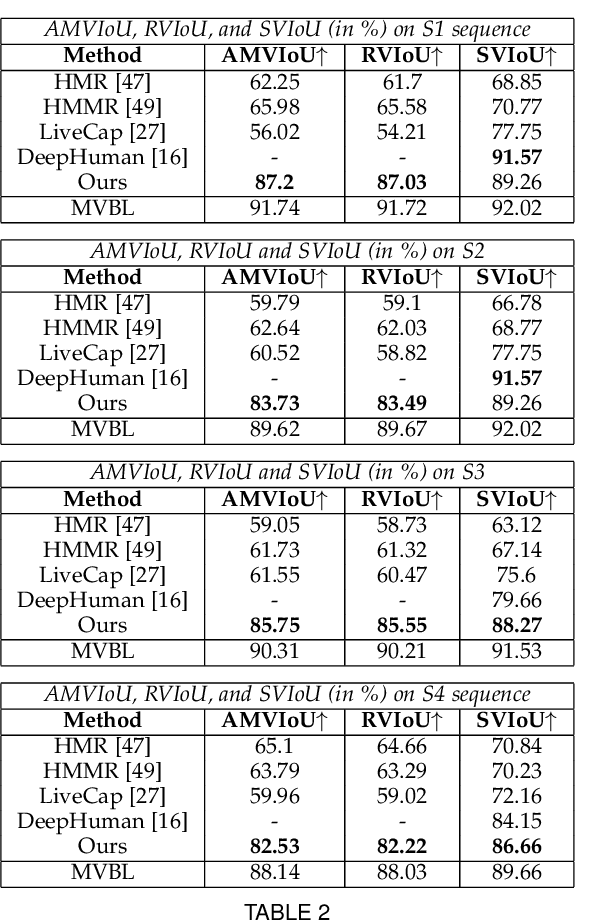
Human performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness. This work is an extended version of DeepCap where we provide more detailed explanations, comparisons and results as well as applications.
Neural-GIF: Neural Generalized Implicit Functions for Animating People in Clothing
Aug 20, 2021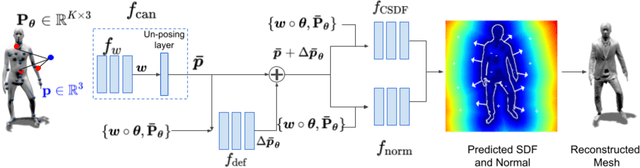


We present Neural Generalized Implicit Functions(Neural-GIF), to animate people in clothing as a function of the body pose. Given a sequence of scans of a subject in various poses, we learn to animate the character for new poses. Existing methods have relied on template-based representations of the human body (or clothing). However such models usually have fixed and limited resolutions, require difficult data pre-processing steps and cannot be used with complex clothing. We draw inspiration from template-based methods, which factorize motion into articulation and non-rigid deformation, but generalize this concept for implicit shape learning to obtain a more flexible model. We learn to map every point in the space to a canonical space, where a learned deformation field is applied to model non-rigid effects, before evaluating the signed distance field. Our formulation allows the learning of complex and non-rigid deformations of clothing and soft tissue, without computing a template registration as it is common with current approaches. Neural-GIF can be trained on raw 3D scans and reconstructs detailed complex surface geometry and deformations. Moreover, the model can generalize to new poses. We evaluate our method on a variety of characters from different public datasets in diverse clothing styles and show significant improvements over baseline methods, quantitatively and qualitatively. We also extend our model to multiple shape setting. To stimulate further research, we will make the model, code and data publicly available at: https://virtualhumans.mpi-inf.mpg.de/neuralgif/
NRST: Non-rigid Surface Tracking from Monocular Video
Jul 12, 2021

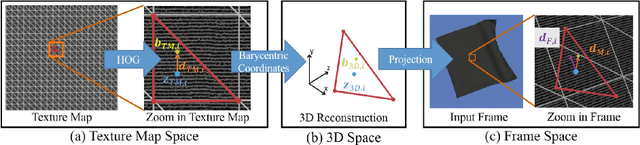

We propose an efficient method for non-rigid surface tracking from monocular RGB videos. Given a video and a template mesh, our algorithm sequentially registers the template non-rigidly to each frame. We formulate the per-frame registration as an optimization problem that includes a novel texture term specifically tailored towards tracking objects with uniform texture but fine-scale structure, such as the regular micro-structural patterns of fabric. Our texture term exploits the orientation information in the micro-structures of the objects, e.g., the yarn patterns of fabrics. This enables us to accurately track uniformly colored materials that have these high frequency micro-structures, for which traditional photometric terms are usually less effective. The results demonstrate the effectiveness of our method on both general textured non-rigid objects and monochromatic fabrics.
Real-time Deep Dynamic Characters
May 04, 2021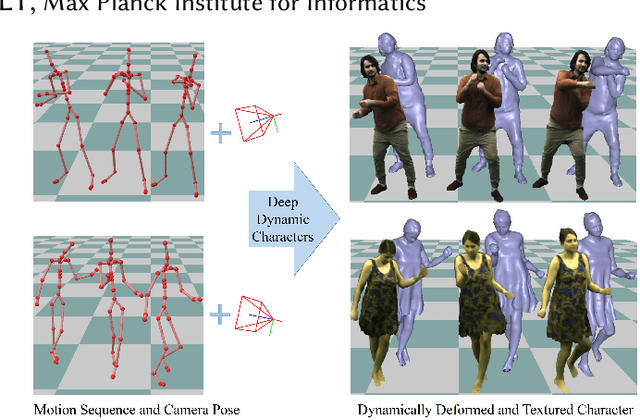

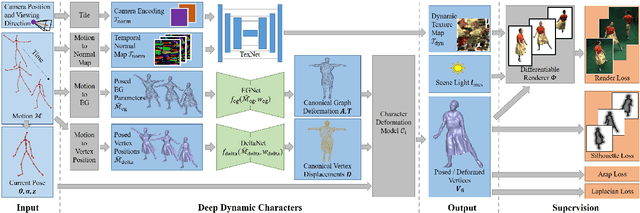

We propose a deep videorealistic 3D human character model displaying highly realistic shape, motion, and dynamic appearance learned in a new weakly supervised way from multi-view imagery. In contrast to previous work, our controllable 3D character displays dynamics, e.g., the swing of the skirt, dependent on skeletal body motion in an efficient data-driven way, without requiring complex physics simulation. Our character model also features a learned dynamic texture model that accounts for photo-realistic motion-dependent appearance details, as well as view-dependent lighting effects. During training, we do not need to resort to difficult dynamic 3D capture of the human; instead we can train our model entirely from multi-view video in a weakly supervised manner. To this end, we propose a parametric and differentiable character representation which allows us to model coarse and fine dynamic deformations, e.g., garment wrinkles, as explicit space-time coherent mesh geometry that is augmented with high-quality dynamic textures dependent on motion and view point. As input to the model, only an arbitrary 3D skeleton motion is required, making it directly compatible with the established 3D animation pipeline. We use a novel graph convolutional network architecture to enable motion-dependent deformation learning of body and clothing, including dynamics, and a neural generative dynamic texture model creates corresponding dynamic texture maps. We show that by merely providing new skeletal motions, our model creates motion-dependent surface deformations, physically plausible dynamic clothing deformations, as well as video-realistic surface textures at a much higher level of detail than previous state of the art approaches, and even in real-time.
Stereo Radiance Fields (SRF): Learning View Synthesis for Sparse Views of Novel Scenes
Apr 14, 2021

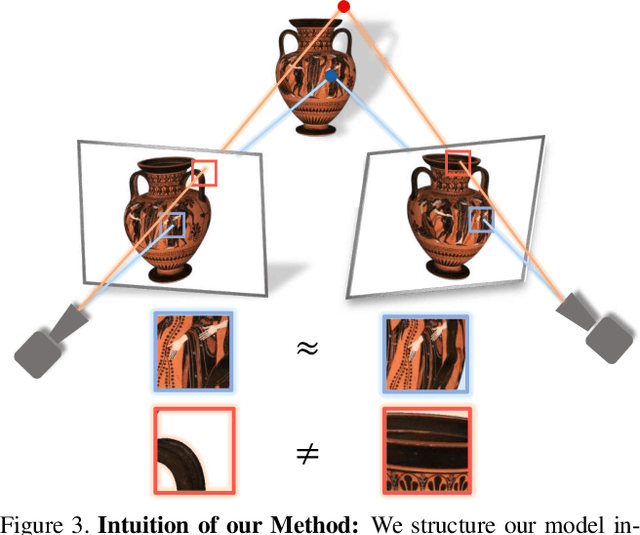
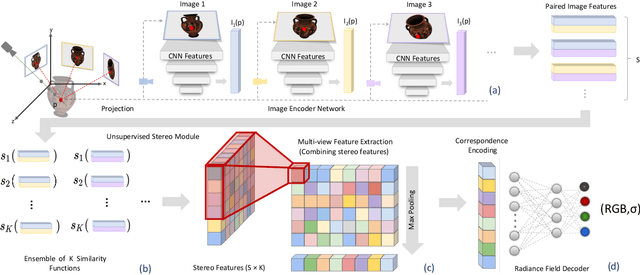
Recent neural view synthesis methods have achieved impressive quality and realism, surpassing classical pipelines which rely on multi-view reconstruction. State-of-the-Art methods, such as NeRF, are designed to learn a single scene with a neural network and require dense multi-view inputs. Testing on a new scene requires re-training from scratch, which takes 2-3 days. In this work, we introduce Stereo Radiance Fields (SRF), a neural view synthesis approach that is trained end-to-end, generalizes to new scenes, and requires only sparse views at test time. The core idea is a neural architecture inspired by classical multi-view stereo methods, which estimates surface points by finding similar image regions in stereo images. In SRF, we predict color and density for each 3D point given an encoding of its stereo correspondence in the input images. The encoding is implicitly learned by an ensemble of pair-wise similarities -- emulating classical stereo. Experiments show that SRF learns structure instead of overfitting on a scene. We train on multiple scenes of the DTU dataset and generalize to new ones without re-training, requiring only 10 sparse and spread-out views as input. We show that 10-15 minutes of fine-tuning further improve the results, achieving significantly sharper, more detailed results than scene-specific models. The code, model, and videos are available at https://virtualhumans.mpi-inf.mpg.de/srf/.
* IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
SMPLicit: Topology-aware Generative Model for Clothed People
Apr 02, 2021
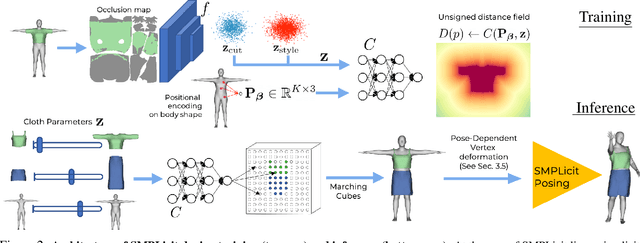
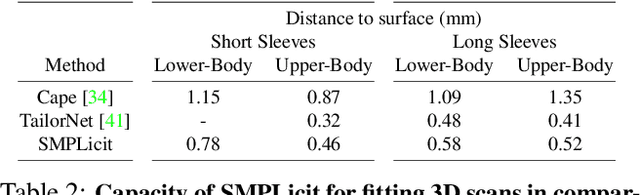
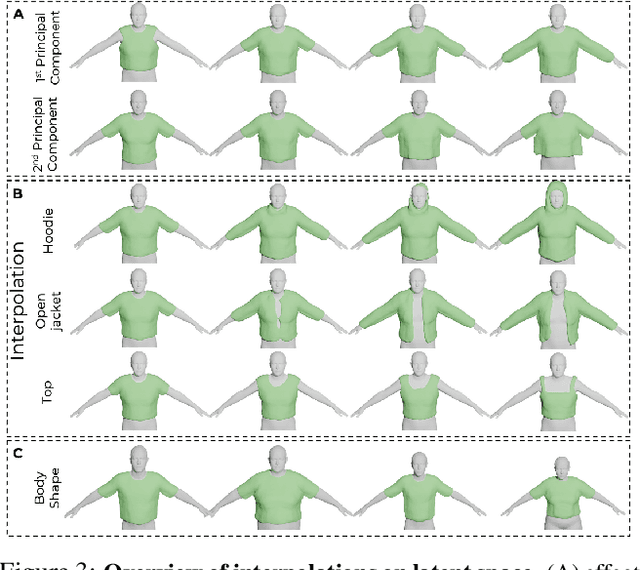
In this paper we introduce SMPLicit, a novel generative model to jointly represent body pose, shape and clothing geometry. In contrast to existing learning-based approaches that require training specific models for each type of garment, SMPLicit can represent in a unified manner different garment topologies (e.g. from sleeveless tops to hoodies and to open jackets), while controlling other properties like the garment size or tightness/looseness. We show our model to be applicable to a large variety of garments including T-shirts, hoodies, jackets, shorts, pants, skirts, shoes and even hair. The representation flexibility of SMPLicit builds upon an implicit model conditioned with the SMPL human body parameters and a learnable latent space which is semantically interpretable and aligned with the clothing attributes. The proposed model is fully differentiable, allowing for its use into larger end-to-end trainable systems. In the experimental section, we demonstrate SMPLicit can be readily used for fitting 3D scans and for 3D reconstruction in images of dressed people. In both cases we are able to go beyond state of the art, by retrieving complex garment geometries, handling situations with multiple clothing layers and providing a tool for easy outfit editing. To stimulate further research in this direction, we will make our code and model publicly available at http://www.iri.upc.edu/people/ecorona/smplicit/.
Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors
Mar 31, 2021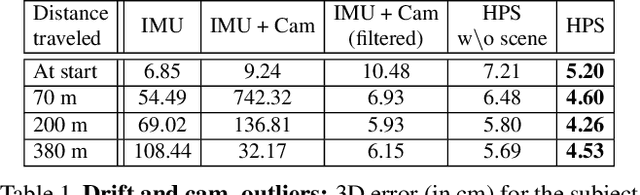
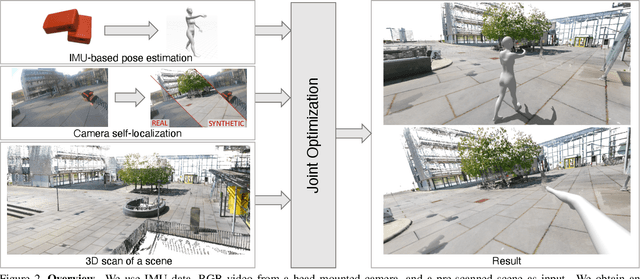
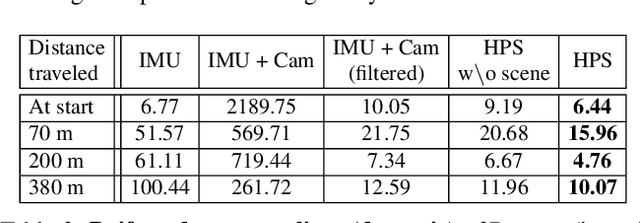
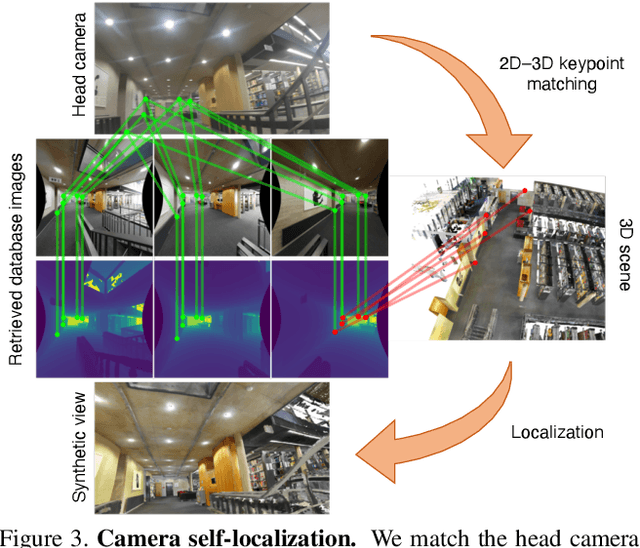
We introduce (HPS) Human POSEitioning System, a method to recover the full 3D pose of a human registered with a 3D scan of the surrounding environment using wearable sensors. Using IMUs attached at the body limbs and a head mounted camera looking outwards, HPS fuses camera based self-localization with IMU-based human body tracking. The former provides drift-free but noisy position and orientation estimates while the latter is accurate in the short-term but subject to drift over longer periods of time. We show that our optimization-based integration exploits the benefits of the two, resulting in pose accuracy free of drift. Furthermore, we integrate 3D scene constraints into our optimization, such as foot contact with the ground, resulting in physically plausible motion. HPS complements more common third-person-based 3D pose estimation methods. It allows capturing larger recording volumes and longer periods of motion, and could be used for VR/AR applications where humans interact with the scene without requiring direct line of sight with an external camera, or to train agents that navigate and interact with the environment based on first-person visual input, like real humans. With HPS, we recorded a dataset of humans interacting with large 3D scenes (300-1000 sq.m) consisting of 7 subjects and more than 3 hours of diverse motion. The dataset, code and video will be available on the project page: http://virtualhumans.mpi-inf.mpg.de/hps/ .
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021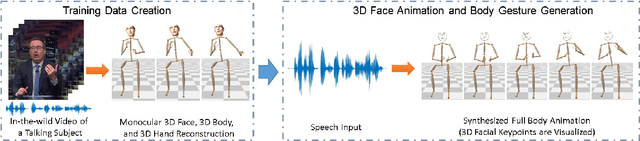
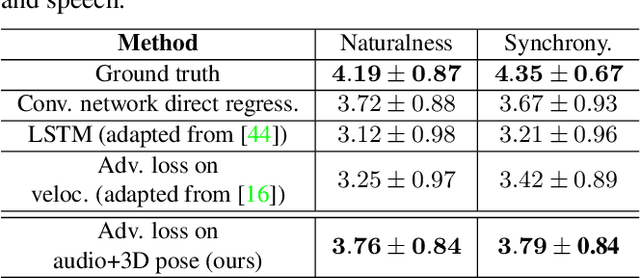
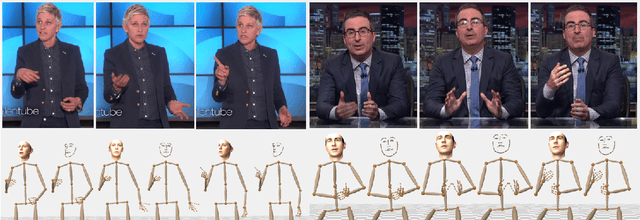
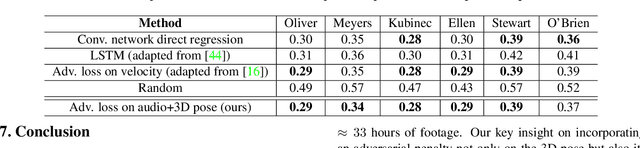
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.