 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTanbih: Get To Know What You Are Reading
Oct 04, 2019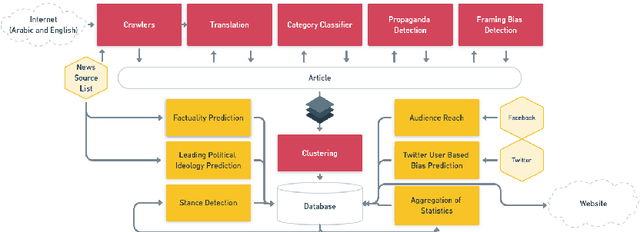
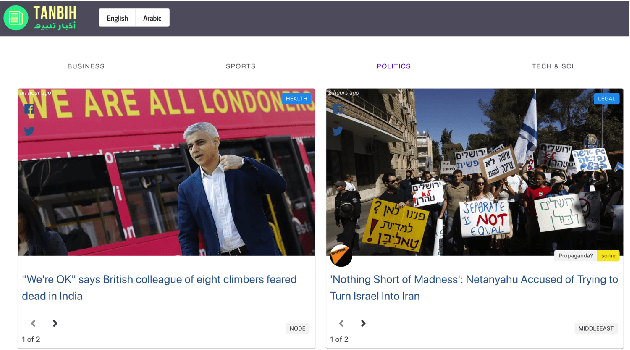
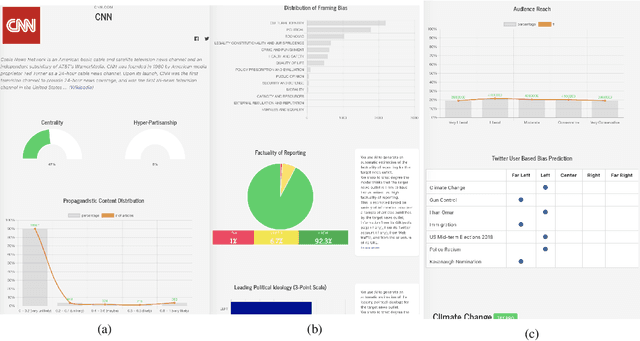
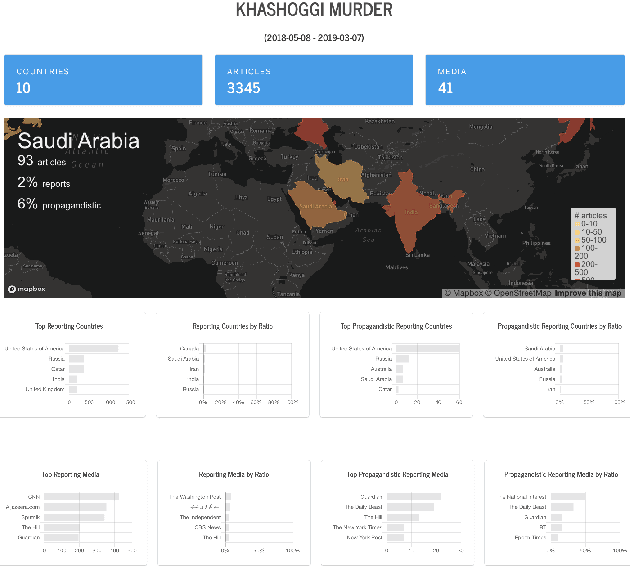
We introduce Tanbih, a news aggregator with intelligent analysis tools to help readers understanding what's behind a news story. Our system displays news grouped into events and generates media profiles that show the general factuality of reporting, the degree of propagandistic content, hyper-partisanship, leading political ideology, general frame of reporting, and stance with respect to various claims and topics of a news outlet. In addition, we automatically analyse each article to detect whether it is propagandistic and to determine its stance with respect to a number of controversial topics.
Automatic Fact-Checking Using Context and Discourse Information
Aug 04, 2019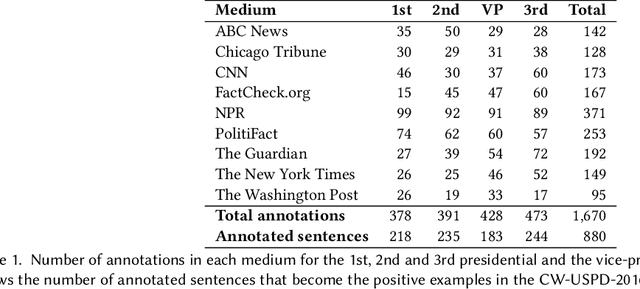

We study the problem of automatic fact-checking, paying special attention to the impact of contextual and discourse information. We address two related tasks: (i) detecting check-worthy claims, and (ii) fact-checking claims. We develop supervised systems based on neural networks, kernel-based support vector machines, and combinations thereof, which make use of rich input representations in terms of discourse cues and contextual features. For the check-worthiness estimation task, we focus on political debates, and we model the target claim in the context of the full intervention of a participant and the previous and the following turns in the debate, taking into account contextual meta information. For the fact-checking task, we focus on answer verification in a community forum, and we model the veracity of the answer with respect to the entire question--answer thread in which it occurs as well as with respect to other related posts from the entire forum. We develop annotated datasets for both tasks and we run extensive experimental evaluation, confirming that both types of information ---but especially contextual features--- play an important role.
* JDIQ,Special Issue on Combating Digital Misinformation and Disinformation
Multi-Task Ordinal Regression for Jointly Predicting the Trustworthiness and the Leading Political Ideology of News Media
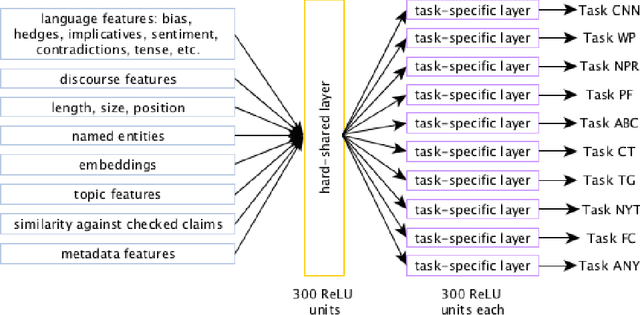
Apr 01, 2019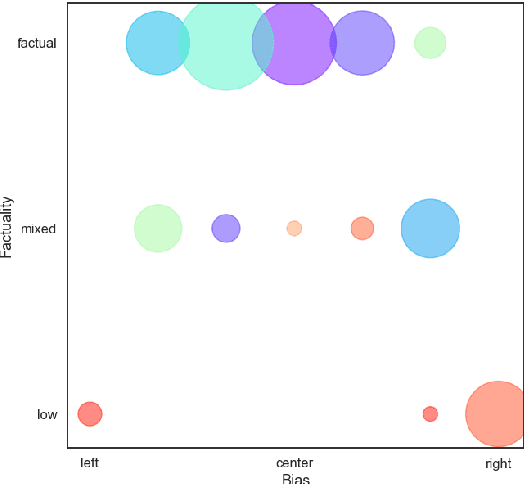
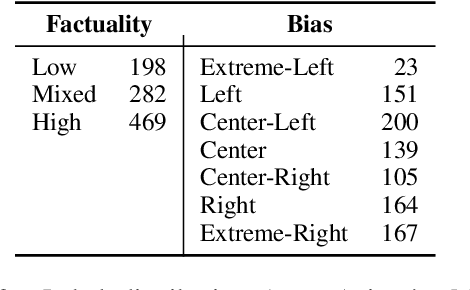
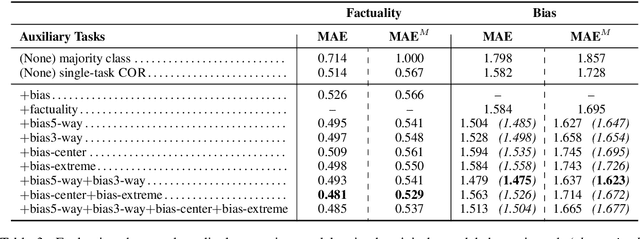
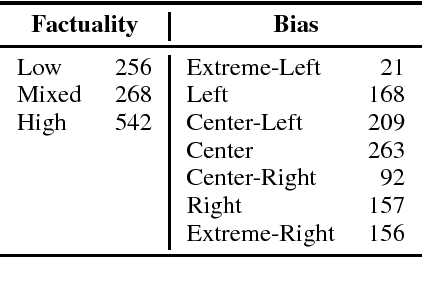
In the context of fake news, bias, and propaganda, we study two important but relatively under-explored problems: (i) trustworthiness estimation (on a 3-point scale) and (ii) political ideology detection (left/right bias on a 7-point scale) of entire news outlets, as opposed to evaluating individual articles. In particular, we propose a multi-task ordinal regression framework that models the two problems jointly. This is motivated by the observation that hyper-partisanship is often linked to low trustworthiness, e.g., appealing to emotions rather than sticking to the facts, while center media tend to be generally more impartial and trustworthy. We further use several auxiliary tasks, modeling centrality, hyperpartisanship, as well as left-vs.-right bias on a coarse-grained scale. The evaluation results show sizable performance gains by the joint models over models that target the problems in isolation.
Predicting Factuality of Reporting and Bias of News Media Sources
Oct 02, 2018

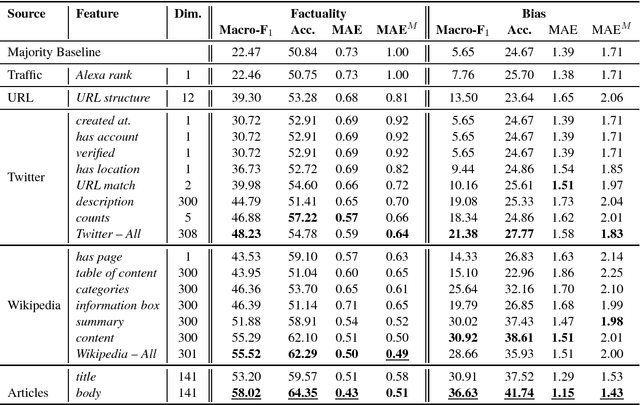
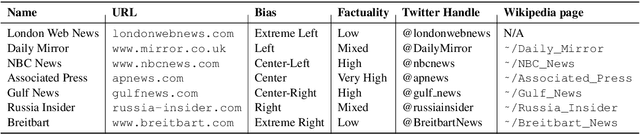
We present a study on predicting the factuality of reporting and bias of news media. While previous work has focused on studying the veracity of claims or documents, here we are interested in characterizing entire news media. These are under-studied but arguably important research problems, both in their own right and as a prior for fact-checking systems. We experiment with a large list of news websites and with a rich set of features derived from (i) a sample of articles from the target news medium, (ii) its Wikipedia page, (iii) its Twitter account, (iv) the structure of its URL, and (v) information about the Web traffic it attracts. The experimental results show sizable performance gains over the baselines, and confirm the importance of each feature type.
We Built a Fake News & Click-bait Filter: What Happened Next Will Blow Your Mind!
Mar 10, 2018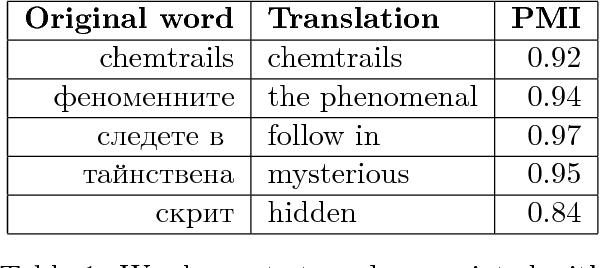
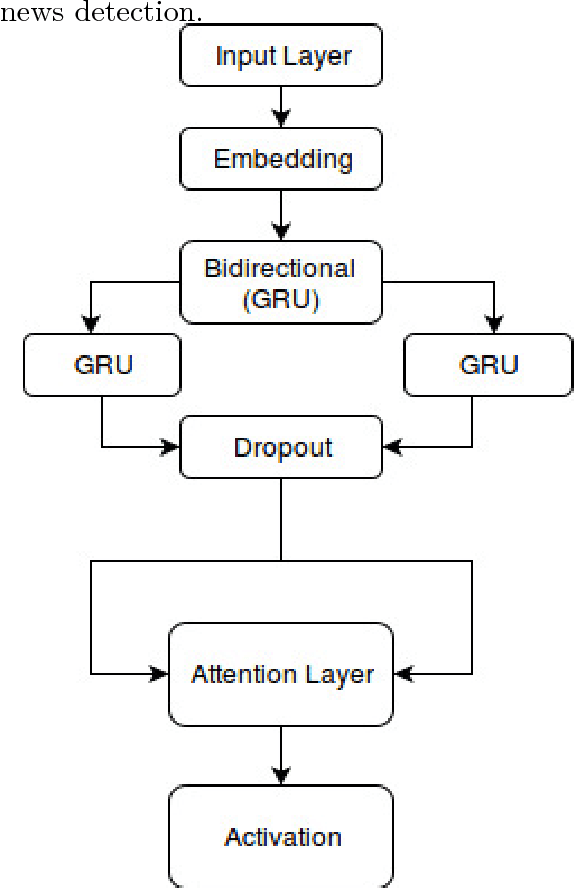
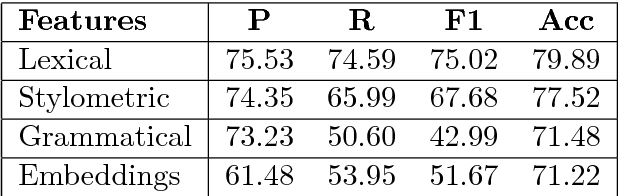
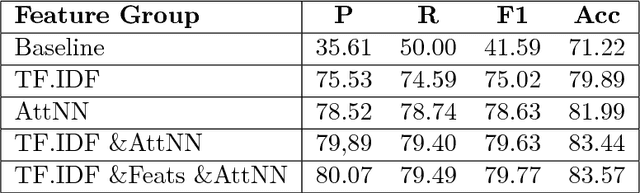
It is completely amazing! Fake news and click-baits have totally invaded the cyber space. Let us face it: everybody hates them for three simple reasons. Reason #2 will absolutely amaze you. What these can achieve at the time of election will completely blow your mind! Now, we all agree, this cannot go on, you know, somebody has to stop it. So, we did this research on fake news/click-bait detection and trust us, it is totally great research, it really is! Make no mistake. This is the best research ever! Seriously, come have a look, we have it all: neural networks, attention mechanism, sentiment lexicons, author profiling, you name it. Lexical features, semantic features, we absolutely have it all. And we have totally tested it, trust us! We have results, and numbers, really big numbers. The best numbers ever! Oh, and analysis, absolutely top notch analysis. Interested? Come read the shocking truth about fake news and click-bait in the Bulgarian cyber space. You won't believe what we have found!
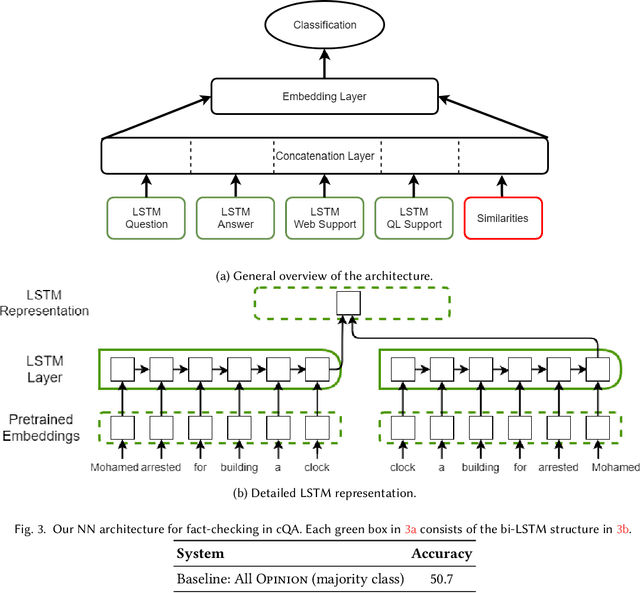
Fact Checking in Community Forums
Mar 08, 2018
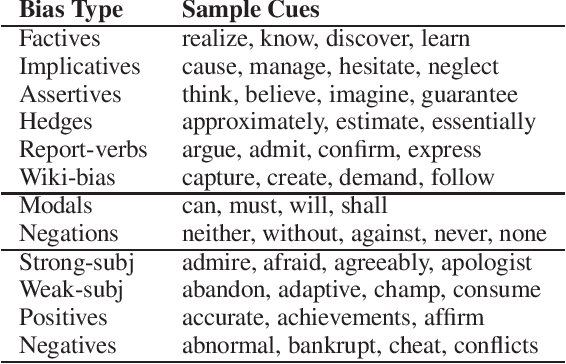
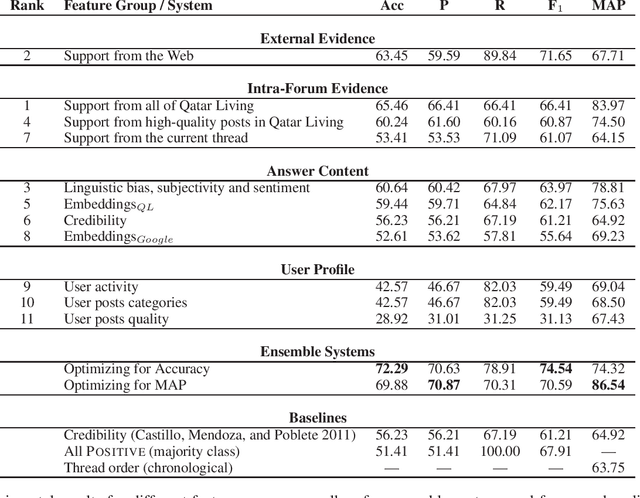

Community Question Answering (cQA) forums are very popular nowadays, as they represent effective means for communities around particular topics to share information. Unfortunately, this information is not always factual. Thus, here we explore a new dimension in the context of cQA, which has been ignored so far: checking the veracity of answers to particular questions in cQA forums. As this is a new problem, we create a specialized dataset for it. We further propose a novel multi-faceted model, which captures information from the answer content (what is said and how), from the author profile (who says it), from the rest of the community forum (where it is said), and from external authoritative sources of information (external support). Evaluation results show a MAP value of 86.54, which is 21 points absolute above the baseline.
Fully Automated Fact Checking Using External Sources
Oct 01, 2017
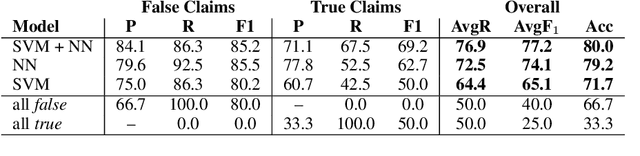
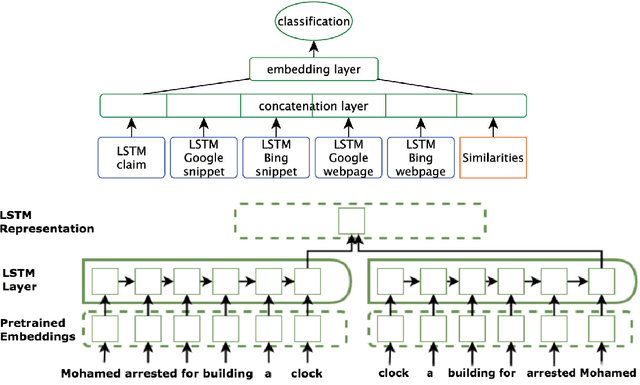
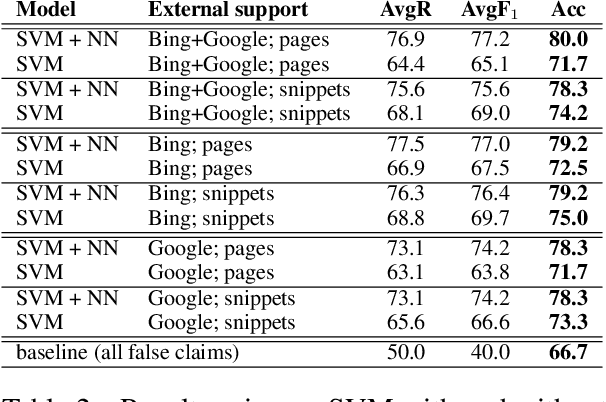
Given the constantly growing proliferation of false claims online in recent years, there has been also a growing research interest in automatically distinguishing false rumors from factually true claims. Here, we propose a general-purpose framework for fully-automatic fact checking using external sources, tapping the potential of the entire Web as a knowledge source to confirm or reject a claim. Our framework uses a deep neural network with LSTM text encoding to combine semantic kernels with task-specific embeddings that encode a claim together with pieces of potentially-relevant text fragments from the Web, taking the source reliability into account. The evaluation results show good performance on two different tasks and datasets: (i) rumor detection and (ii) fact checking of the answers to a question in community question answering forums.