 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupled Gradient Estimators for Discrete Latent Variables
Jun 15, 2021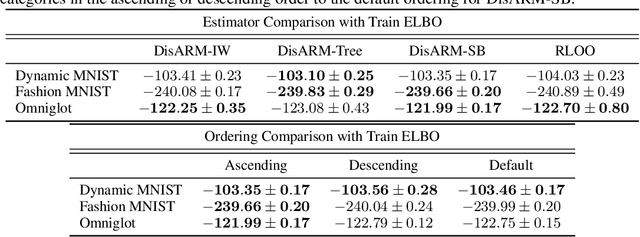
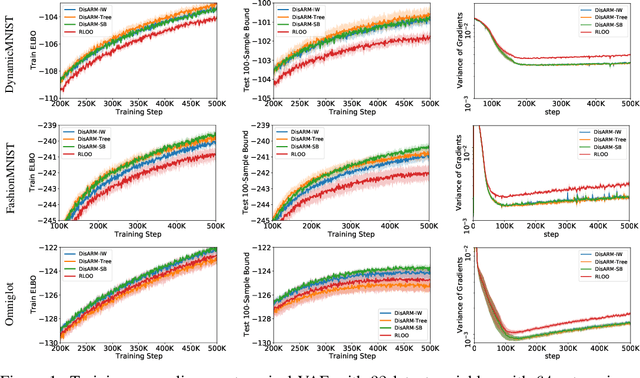
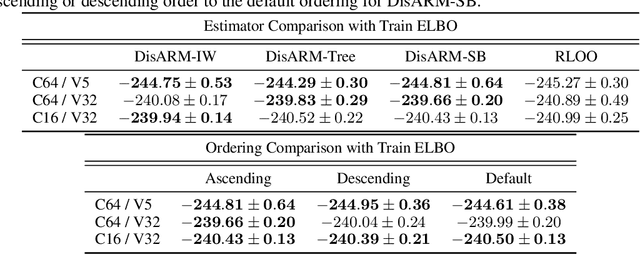
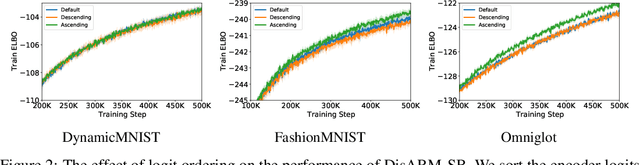
Training models with discrete latent variables is challenging due to the high variance of unbiased gradient estimators. While low-variance reparameterization gradients of a continuous relaxation can provide an effective solution, a continuous relaxation is not always available or tractable. Dong et al. (2020) and Yin et al. (2020) introduced a performant estimator that does not rely on continuous relaxations; however, it is limited to binary random variables. We introduce a novel derivation of their estimator based on importance sampling and statistical couplings, which we extend to the categorical setting. Motivated by the construction of a stick-breaking coupling, we introduce gradient estimators based on reparameterizing categorical variables as sequences of binary variables and Rao-Blackwellization. In systematic experiments, we show that our proposed categorical gradient estimators provide state-of-the-art performance, whereas even with additional Rao-Blackwellization, previous estimators (Yin et al., 2019) underperform a simpler REINFORCE with a leave-one-out-baseline estimator (Kool et al., 2019).
Autoregressive Dynamics Models for Offline Policy Evaluation and Optimization
Apr 28, 2021

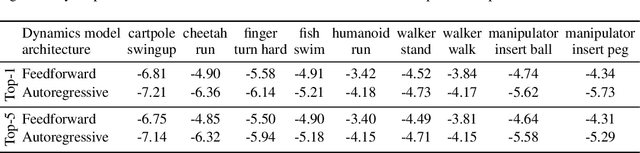

Standard dynamics models for continuous control make use of feedforward computation to predict the conditional distribution of next state and reward given current state and action using a multivariate Gaussian with a diagonal covariance structure. This modeling choice assumes that different dimensions of the next state and reward are conditionally independent given the current state and action and may be driven by the fact that fully observable physics-based simulation environments entail deterministic transition dynamics. In this paper, we challenge this conditional independence assumption and propose a family of expressive autoregressive dynamics models that generate different dimensions of the next state and reward sequentially conditioned on previous dimensions. We demonstrate that autoregressive dynamics models indeed outperform standard feedforward models in log-likelihood on heldout transitions. Furthermore, we compare different model-based and model-free off-policy evaluation (OPE) methods on RL Unplugged, a suite of offline MuJoCo datasets, and find that autoregressive dynamics models consistently outperform all baselines, achieving a new state-of-the-art. Finally, we show that autoregressive dynamics models are useful for offline policy optimization by serving as a way to enrich the replay buffer through data augmentation and improving performance using model-based planning.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021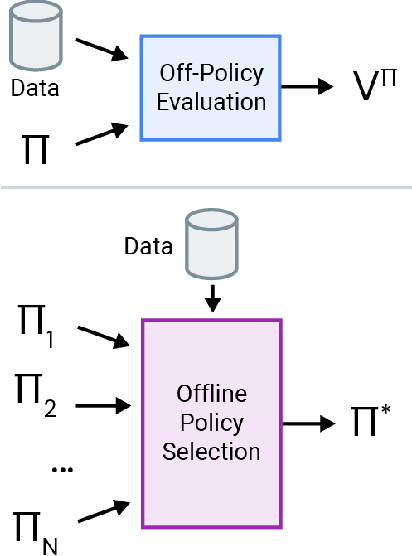
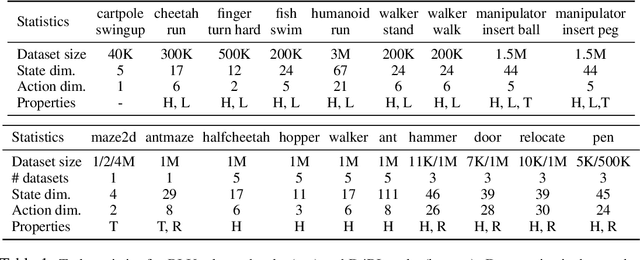
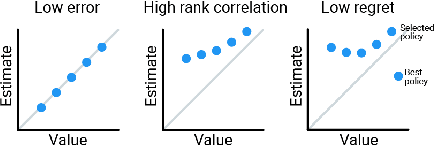
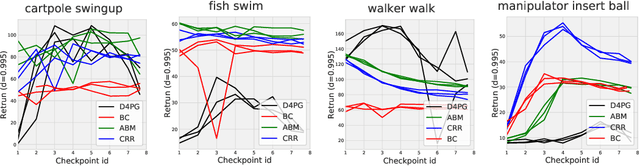
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Offline Policy Selection under Uncertainty
Dec 12, 2020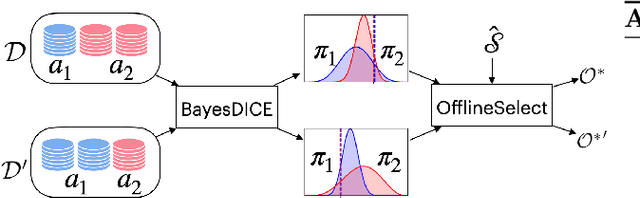
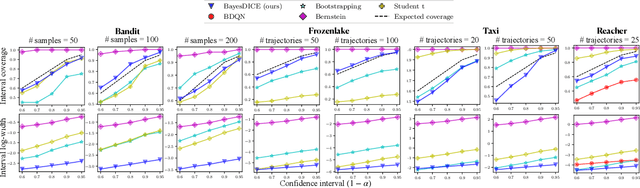
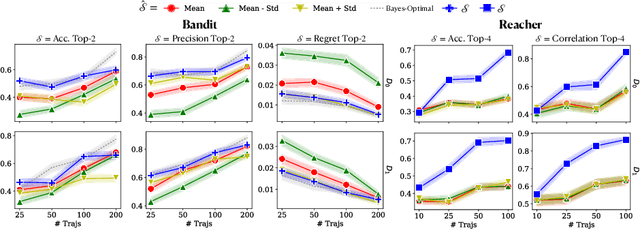
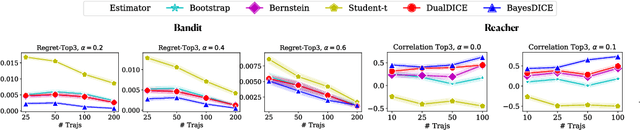
The presence of uncertainty in policy evaluation significantly complicates the process of policy ranking and selection in real-world settings. We formally consider offline policy selection as learning preferences over a set of policy prospects given a fixed experience dataset. While one can select or rank policies based on point estimates of their policy values or high-confidence intervals, access to the full distribution over one's belief of the policy value enables more flexible selection algorithms under a wider range of downstream evaluation metrics. We propose BayesDICE for estimating this belief distribution in terms of posteriors of distribution correction ratios derived from stochastic constraints (as opposed to explicit likelihood, which is not available). Empirically, BayesDICE is highly competitive to existing state-of-the-art approaches in confidence interval estimation. More importantly, we show how the belief distribution estimated by BayesDICE may be used to rank policies with respect to any arbitrary downstream policy selection metric, and we empirically demonstrate that this selection procedure significantly outperforms existing approaches, such as ranking policies according to mean or high-confidence lower bound value estimates.
RL Unplugged: Benchmarks for Offline Reinforcement Learning
Jul 02, 2020
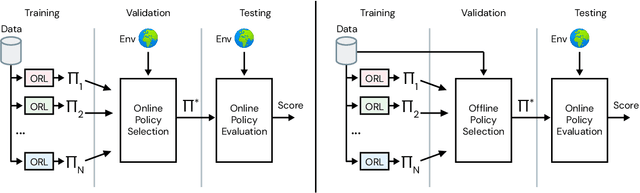
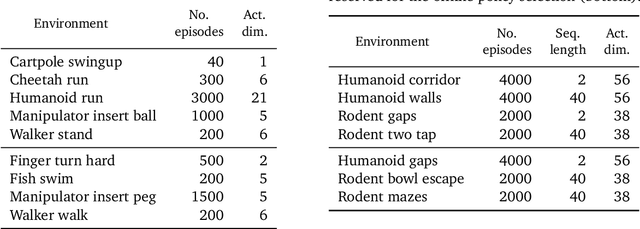
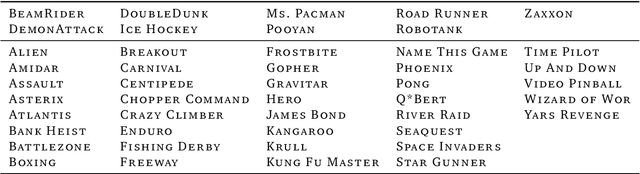
Offline methods for reinforcement learning have a potential to help bridge the gap between reinforcement learning research and real-world applications. They make it possible to learn policies from offline datasets, thus overcoming concerns associated with online data collection in the real-world, including cost, safety, or ethical concerns. In this paper, we propose a benchmark called RL Unplugged to evaluate and compare offline RL methods. RL Unplugged includes data from a diverse range of domains including games ({\em e.g.,} Atari benchmark) and simulated motor control problems ({\em e.g.,} DM Control Suite). The datasets include domains that are partially or fully observable, use continuous or discrete actions, and have stochastic vs. deterministic dynamics. We propose detailed evaluation protocols for each domain in RL Unplugged and provide an extensive analysis of supervised learning and offline RL methods using these protocols. We will release data for all our tasks and open-source all algorithms presented in this paper. We hope that our suite of benchmarks will increase the reproducibility of experiments and make it possible to study challenging tasks with a limited computational budget, thus making RL research both more systematic and more accessible across the community. Moving forward, we view RL Unplugged as a living benchmark suite that will evolve and grow with datasets contributed by the research community and ourselves. Our project page is available on github (https://git.io/JJUhd).
Conservative Q-Learning for Offline Reinforcement Learning
Jun 29, 2020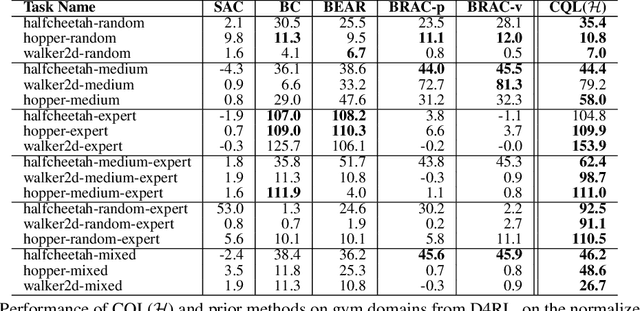

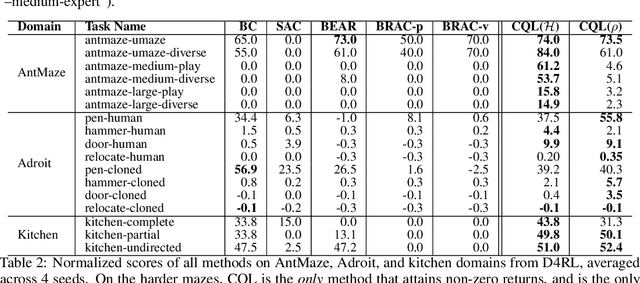
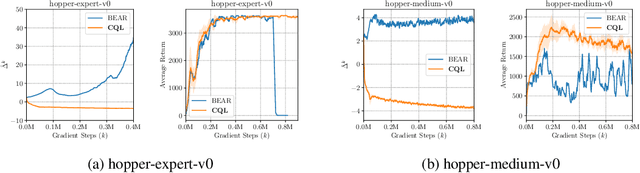
Effectively leveraging large, previously collected datasets in reinforcement learning (RL) is a key challenge for large-scale real-world applications. Offline RL algorithms promise to learn effective policies from previously-collected, static datasets without further interaction. However, in practice, offline RL presents a major challenge, and standard off-policy RL methods can fail due to overestimation of values induced by the distributional shift between the dataset and the learned policy, especially when training on complex and multi-modal data distributions. In this paper, we propose conservative Q-learning (CQL), which aims to address these limitations by learning a conservative Q-function such that the expected value of a policy under this Q-function lower-bounds its true value. We theoretically show that CQL produces a lower bound on the value of the current policy and that it can be incorporated into a principled policy improvement procedure. In practice, CQL augments the standard Bellman error objective with a simple Q-value regularizer which is straightforward to implement on top of existing deep Q-learning and actor-critic implementations. On both discrete and continuous control domains, we show that CQL substantially outperforms existing offline RL methods, often learning policies that attain 2-5 times higher final return, especially when learning from complex and multi-modal data distributions.
DisARM: An Antithetic Gradient Estimator for Binary Latent Variables
Jun 18, 2020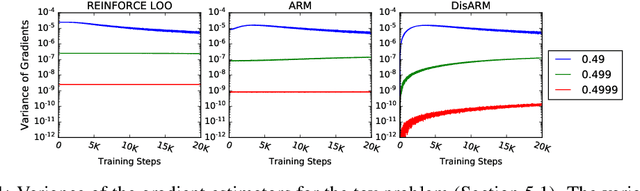
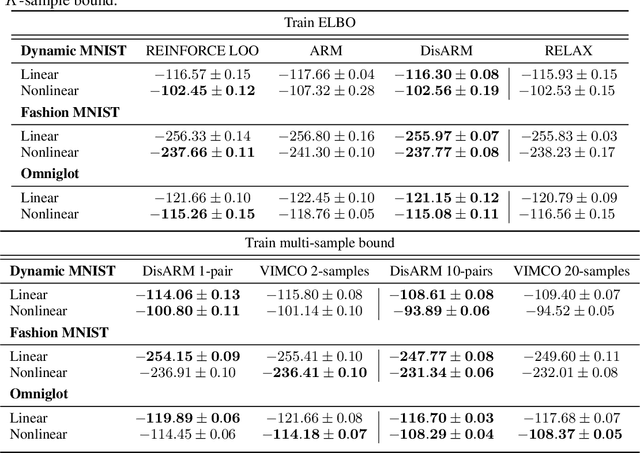
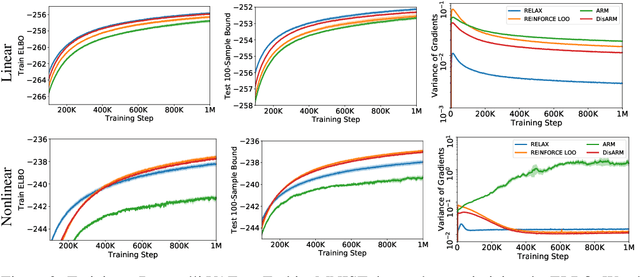
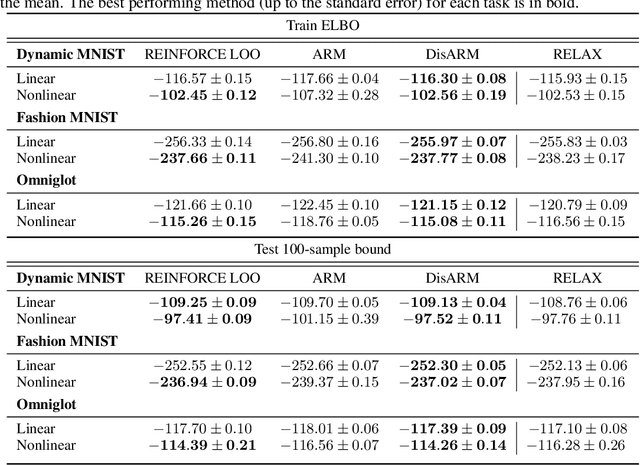
Training models with discrete latent variables is challenging due to the difficulty of estimating the gradients accurately. Much of the recent progress has been achieved by taking advantage of continuous relaxations of the system, which are not always available or even possible. The Augment-REINFORCE-Merge (ARM) estimator provides an alternative that, instead of relaxation, uses continuous augmentation. Applying antithetic sampling over the augmenting variables yields a relatively low-variance and unbiased estimator applicable to any model with binary latent variables. However, while antithetic sampling reduces variance, the augmentation process increases variance. We show that ARM can be improved by analytically integrating out the randomness introduced by the augmentation process, guaranteeing substantial variance reduction. Our estimator, \emph{DisARM}, is simple to implement and has the same computational cost as ARM. We evaluate DisARM on several generative modeling benchmarks and show that it consistently outperforms ARM and a strong independent sample baseline in terms of both variance and log-likelihood. Furthermore, we propose a local version of DisARM designed for optimizing the multi-sample variational bound, and show that it outperforms VIMCO, the current state-of-the-art method.
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
May 04, 2020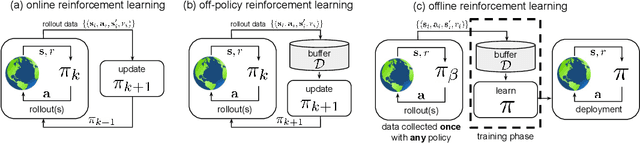
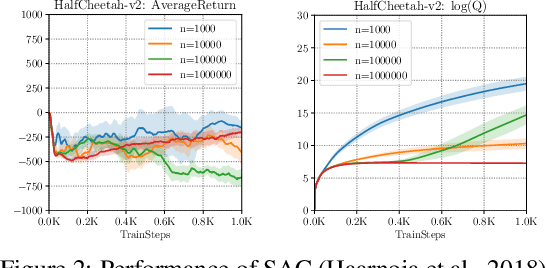
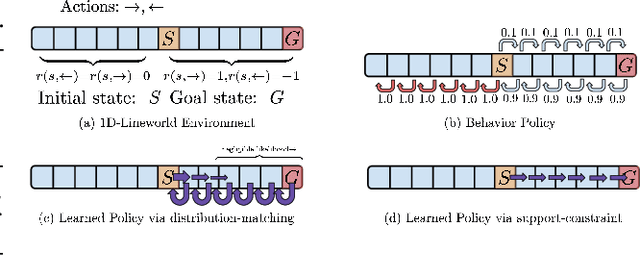
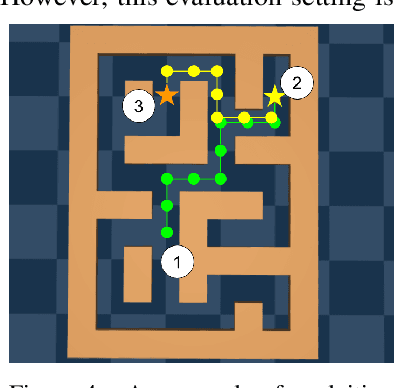
In this tutorial article, we aim to provide the reader with the conceptual tools needed to get started on research on offline reinforcement learning algorithms: reinforcement learning algorithms that utilize previously collected data, without additional online data collection. Offline reinforcement learning algorithms hold tremendous promise for making it possible to turn large datasets into powerful decision making engines. Effective offline reinforcement learning methods would be able to extract policies with the maximum possible utility out of the available data, thereby allowing automation of a wide range of decision-making domains, from healthcare and education to robotics. However, the limitations of current algorithms make this difficult. We will aim to provide the reader with an understanding of these challenges, particularly in the context of modern deep reinforcement learning methods, and describe some potential solutions that have been explored in recent work to mitigate these challenges, along with recent applications, and a discussion of perspectives on open problems in the field.
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Apr 20, 2020
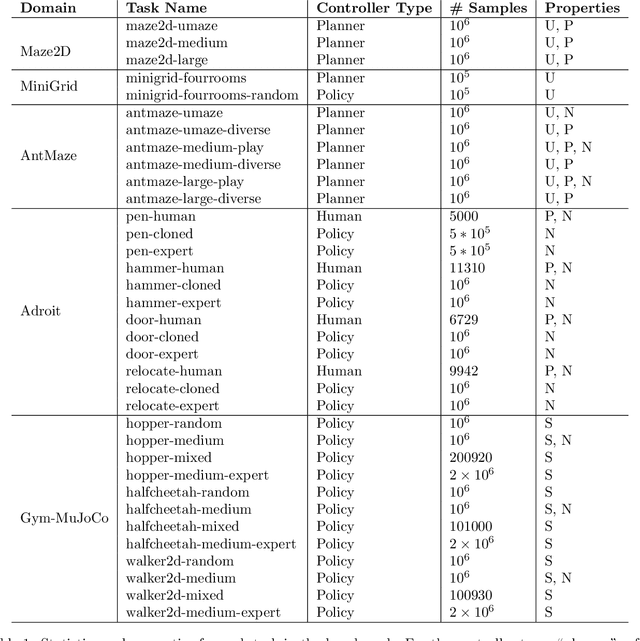
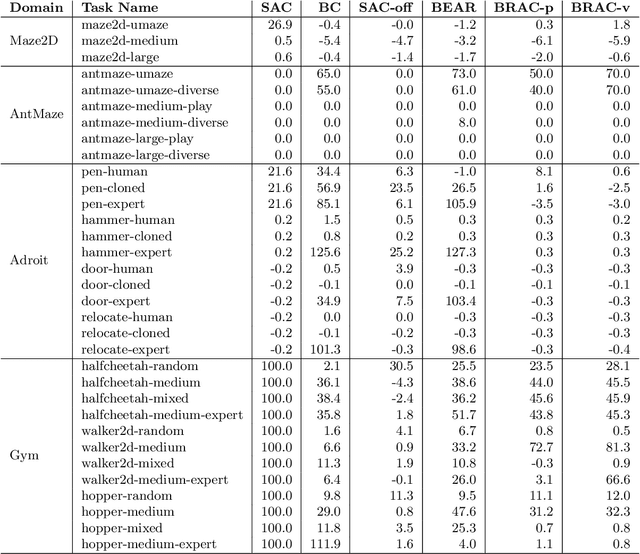
The offline reinforcement learning (RL) problem, also referred to as batch RL, refers to the setting where a policy must be learned from a dataset of previously collected data, without additional online data collection. In supervised learning, large datasets and complex deep neural networks have fueled impressive progress, but in contrast, conventional RL algorithms must collect large amounts of on-policy data and have had little success leveraging previously collected datasets. As a result, existing RL benchmarks are not well-suited for the offline setting, making progress in this area difficult to measure. To design a benchmark tailored to offline RL, we start by outlining key properties of datasets relevant to applications of offline RL. Based on these properties, we design a set of benchmark tasks and datasets that evaluate offline RL algorithms under these conditions. Examples of such properties include: datasets generated via hand-designed controllers and human demonstrators, multi-objective datasets, where an agent can perform different tasks in the same environment, and datasets consisting of a heterogeneous mix of high-quality and low-quality trajectories. By designing the benchmark tasks and datasets to reflect properties of real-world offline RL problems, our benchmark will focus research effort on methods that drive substantial improvements not just on simulated benchmarks, but ultimately on the kinds of real-world problems where offline RL will have the largest impact.
Meta-Learning without Memorization
Dec 24, 2019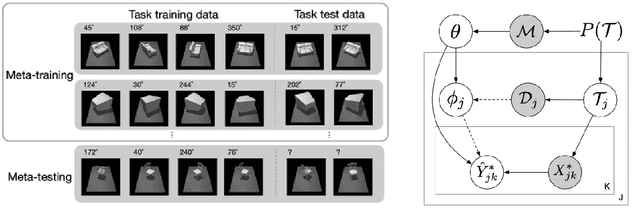

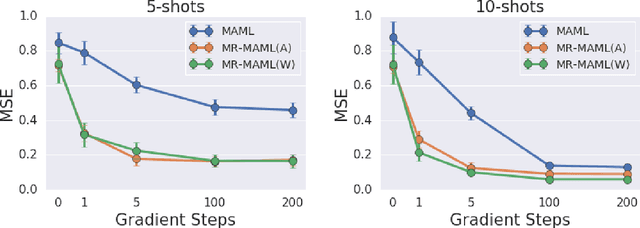

The ability to learn new concepts with small amounts of data is a critical aspect of intelligence that has proven challenging for deep learning methods. Meta-learning has emerged as a promising technique for leveraging data from previous tasks to enable efficient learning of new tasks. However, most meta-learning algorithms implicitly require that the meta-training tasks be mutually-exclusive, such that no single model can solve all of the tasks at once. For example, when creating tasks for few-shot image classification, prior work uses a per-task random assignment of image classes to N-way classification labels. If this is not done, the meta-learner can ignore the task training data and learn a single model that performs all of the meta-training tasks zero-shot, but does not adapt effectively to new image classes. This requirement means that the user must take great care in designing the tasks, for example by shuffling labels or removing task identifying information from the inputs. In some domains, this makes meta-learning entirely inapplicable. In this paper, we address this challenge by designing a meta-regularization objective using information theory that places precedence on data-driven adaptation. This causes the meta-learner to decide what must be learned from the task training data and what should be inferred from the task testing input. By doing so, our algorithm can successfully use data from non-mutually-exclusive tasks to efficiently adapt to novel tasks. We demonstrate its applicability to both contextual and gradient-based meta-learning algorithms, and apply it in practical settings where applying standard meta-learning has been difficult. Our approach substantially outperforms standard meta-learning algorithms in these settings.