 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Message Passing for Quantum Chemistry
Jun 12, 2017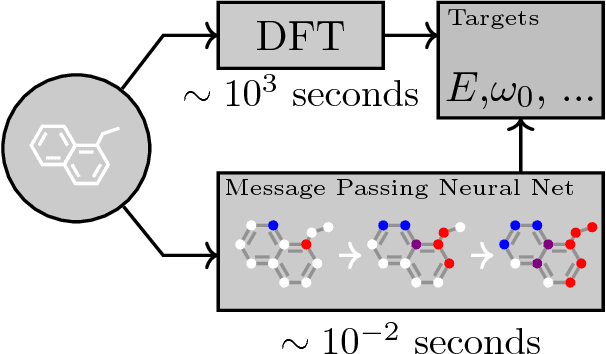

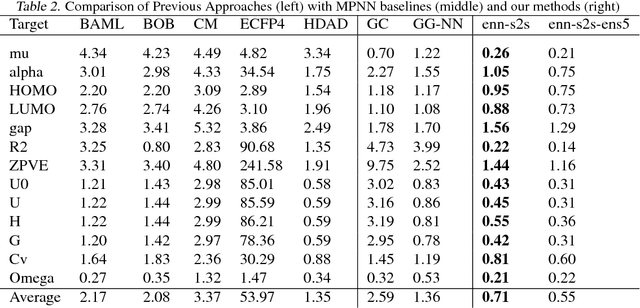
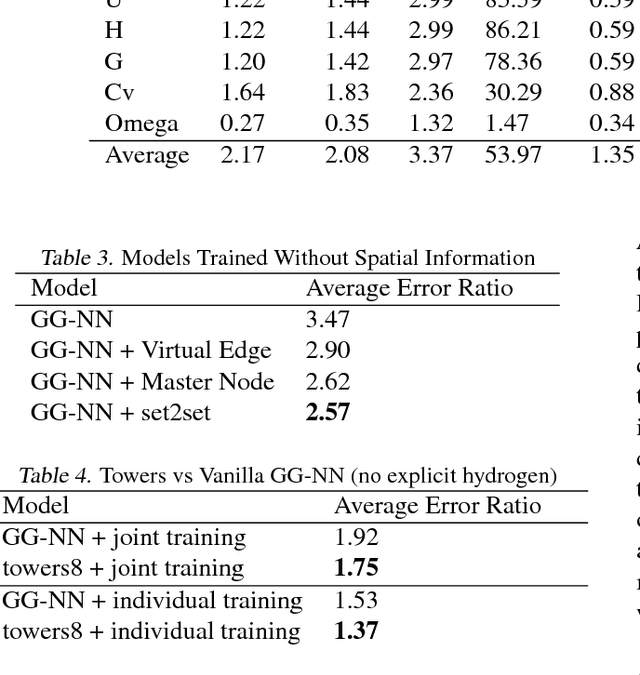
Supervised learning on molecules has incredible potential to be useful in chemistry, drug discovery, and materials science. Luckily, several promising and closely related neural network models invariant to molecular symmetries have already been described in the literature. These models learn a message passing algorithm and aggregation procedure to compute a function of their entire input graph. At this point, the next step is to find a particularly effective variant of this general approach and apply it to chemical prediction benchmarks until we either solve them or reach the limits of the approach. In this paper, we reformulate existing models into a single common framework we call Message Passing Neural Networks (MPNNs) and explore additional novel variations within this framework. Using MPNNs we demonstrate state of the art results on an important molecular property prediction benchmark; these results are strong enough that we believe future work should focus on datasets with larger molecules or more accurate ground truth labels.
Detecting Cancer Metastases on Gigapixel Pathology Images
Mar 08, 2017
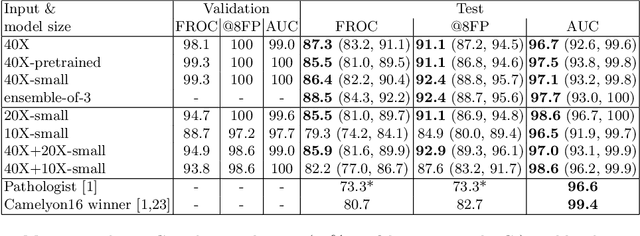
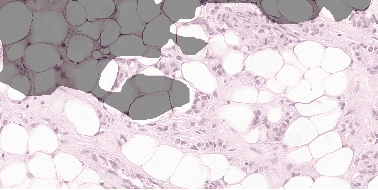
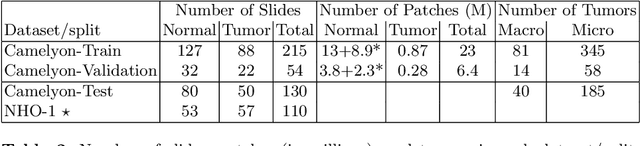
Each year, the treatment decisions for more than 230,000 breast cancer patients in the U.S. hinge on whether the cancer has metastasized away from the breast. Metastasis detection is currently performed by pathologists reviewing large expanses of biological tissues. This process is labor intensive and error-prone. We present a framework to automatically detect and localize tumors as small as 100 x 100 pixels in gigapixel microscopy images sized 100,000 x 100,000 pixels. Our method leverages a convolutional neural network (CNN) architecture and obtains state-of-the-art results on the Camelyon16 dataset in the challenging lesion-level tumor detection task. At 8 false positives per image, we detect 92.4% of the tumors, relative to 82.7% by the previous best automated approach. For comparison, a human pathologist attempting exhaustive search achieved 73.2% sensitivity. We achieve image-level AUC scores above 97% on both the Camelyon16 test set and an independent set of 110 slides. In addition, we discover that two slides in the Camelyon16 training set were erroneously labeled normal. Our approach could considerably reduce false negative rates in metastasis detection.
Incorporating Side Information in Probabilistic Matrix Factorization with Gaussian Processes
Aug 09, 2014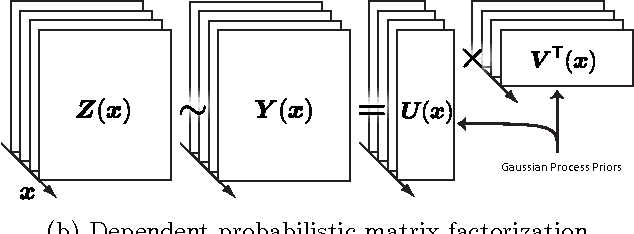
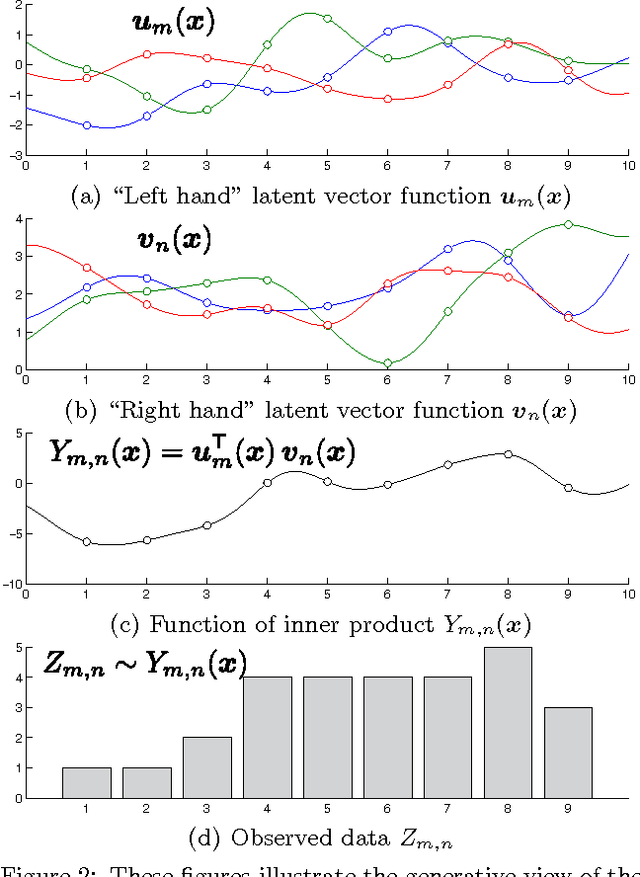
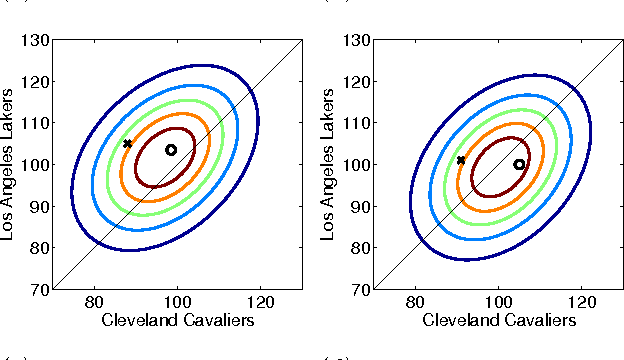
Probabilistic matrix factorization (PMF) is a powerful method for modeling data associ- ated with pairwise relationships, Finding use in collaborative Filtering, computational bi- ology, and document analysis, among other areas. In many domains, there are additional covariates that can assist in prediction. For example, when modeling movie ratings, we might know when the rating occurred, where the user lives, or what actors appear in the movie. It is difficult, however, to incorporate this side information into the PMF model. We propose a framework for incorporating side information by coupling together multi- ple PMF problems via Gaussian process priors. We replace scalar latent features with func- tions that vary over the covariate space. The GP priors on these functions require them to vary smoothly and share information. We apply this new method to predict the scores of professional basketball games, where side information about the venue and date of the game are relevant for the outcome.
Multi-task Neural Networks for QSAR Predictions
Jun 04, 2014
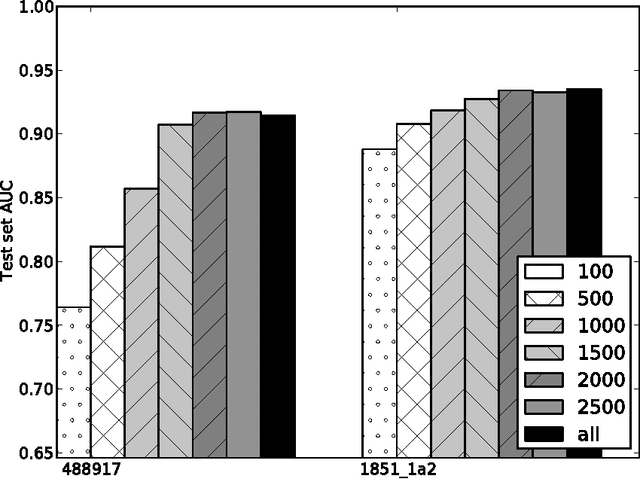
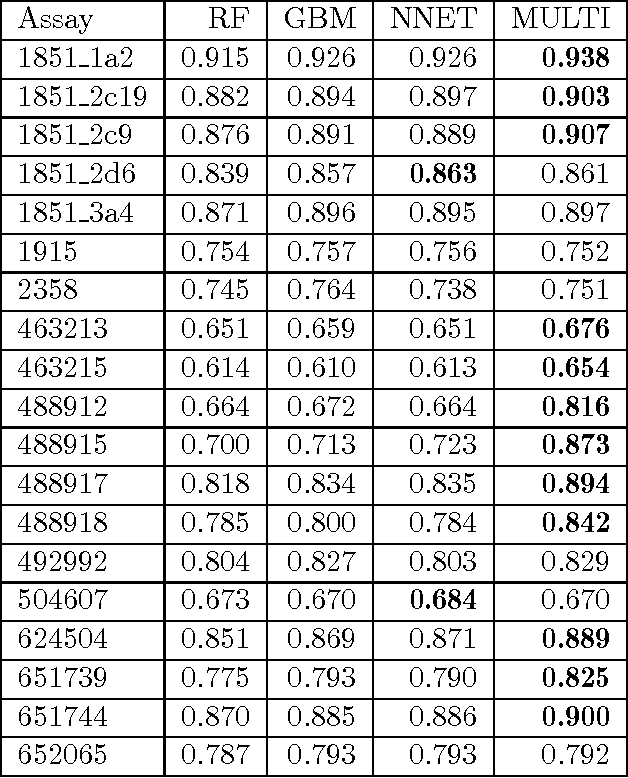
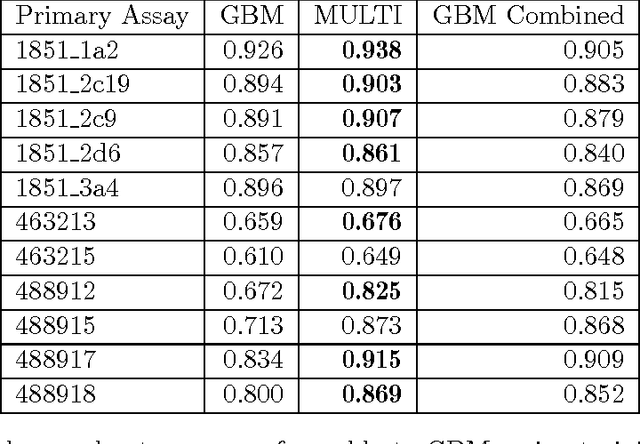
Although artificial neural networks have occasionally been used for Quantitative Structure-Activity/Property Relationship (QSAR/QSPR) studies in the past, the literature has of late been dominated by other machine learning techniques such as random forests. However, a variety of new neural net techniques along with successful applications in other domains have renewed interest in network approaches. In this work, inspired by the winning team's use of neural networks in a recent QSAR competition, we used an artificial neural network to learn a function that predicts activities of compounds for multiple assays at the same time. We conducted experiments leveraging recent methods for dealing with overfitting in neural networks as well as other tricks from the neural networks literature. We compared our methods to alternative methods reported to perform well on these tasks and found that our neural net methods provided superior performance.
Improvements to deep convolutional neural networks for LVCSR
Dec 10, 2013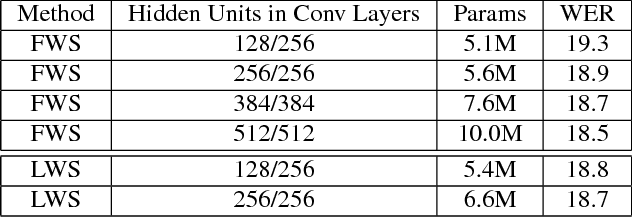
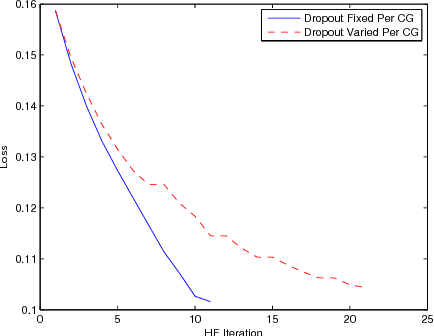
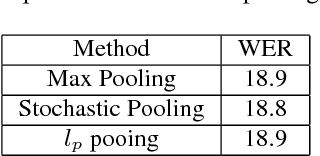

Deep Convolutional Neural Networks (CNNs) are more powerful than Deep Neural Networks (DNN), as they are able to better reduce spectral variation in the input signal. This has also been confirmed experimentally, with CNNs showing improvements in word error rate (WER) between 4-12% relative compared to DNNs across a variety of LVCSR tasks. In this paper, we describe different methods to further improve CNN performance. First, we conduct a deep analysis comparing limited weight sharing and full weight sharing with state-of-the-art features. Second, we apply various pooling strategies that have shown improvements in computer vision to an LVCSR speech task. Third, we introduce a method to effectively incorporate speaker adaptation, namely fMLLR, into log-mel features. Fourth, we introduce an effective strategy to use dropout during Hessian-free sequence training. We find that with these improvements, particularly with fMLLR and dropout, we are able to achieve an additional 2-3% relative improvement in WER on a 50-hour Broadcast News task over our previous best CNN baseline. On a larger 400-hour BN task, we find an additional 4-5% relative improvement over our previous best CNN baseline.
Training Restricted Boltzmann Machines on Word Observations
Jul 05, 2012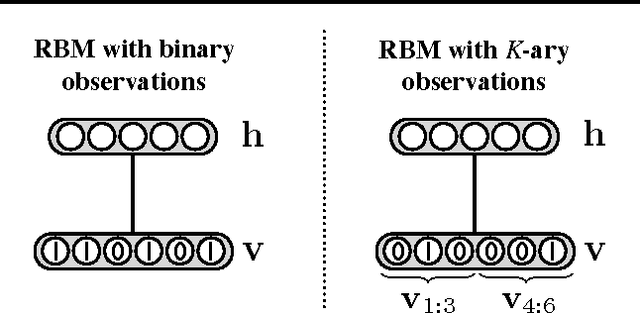
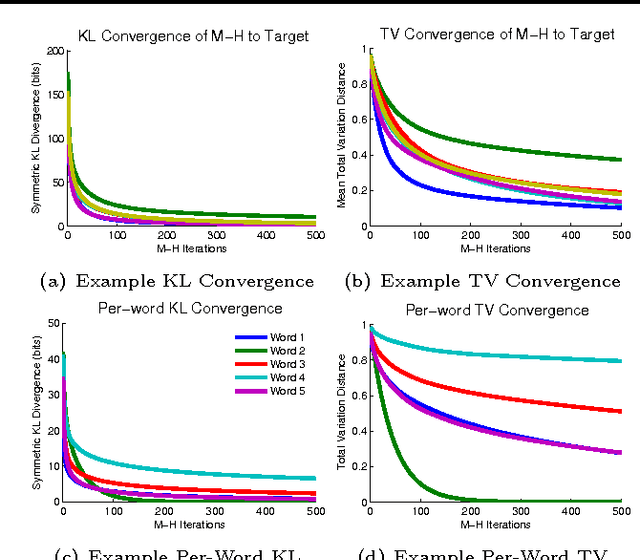

The restricted Boltzmann machine (RBM) is a flexible tool for modeling complex data, however there have been significant computational difficulties in using RBMs to model high-dimensional multinomial observations. In natural language processing applications, words are naturally modeled by K-ary discrete distributions, where K is determined by the vocabulary size and can easily be in the hundreds of thousands. The conventional approach to training RBMs on word observations is limited because it requires sampling the states of K-way softmax visible units during block Gibbs updates, an operation that takes time linear in K. In this work, we address this issue by employing a more general class of Markov chain Monte Carlo operators on the visible units, yielding updates with computational complexity independent of K. We demonstrate the success of our approach by training RBMs on hundreds of millions of word n-grams using larger vocabularies than previously feasible and using the learned features to improve performance on chunking and sentiment classification tasks, achieving state-of-the-art results on the latter.