 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovements to deep convolutional neural networks for LVCSR
Paper and Code
Dec 10, 2013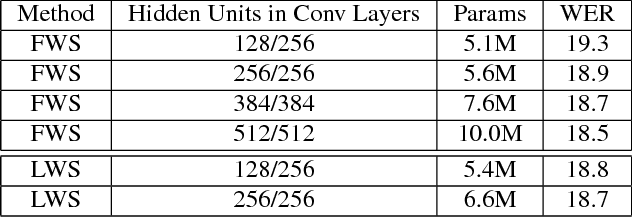
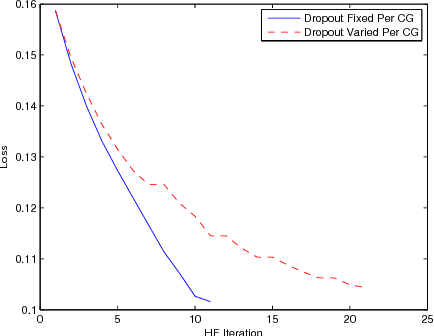
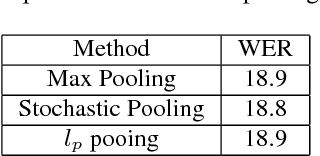

Deep Convolutional Neural Networks (CNNs) are more powerful than Deep Neural Networks (DNN), as they are able to better reduce spectral variation in the input signal. This has also been confirmed experimentally, with CNNs showing improvements in word error rate (WER) between 4-12% relative compared to DNNs across a variety of LVCSR tasks. In this paper, we describe different methods to further improve CNN performance. First, we conduct a deep analysis comparing limited weight sharing and full weight sharing with state-of-the-art features. Second, we apply various pooling strategies that have shown improvements in computer vision to an LVCSR speech task. Third, we introduce a method to effectively incorporate speaker adaptation, namely fMLLR, into log-mel features. Fourth, we introduce an effective strategy to use dropout during Hessian-free sequence training. We find that with these improvements, particularly with fMLLR and dropout, we are able to achieve an additional 2-3% relative improvement in WER on a 50-hour Broadcast News task over our previous best CNN baseline. On a larger 400-hour BN task, we find an additional 4-5% relative improvement over our previous best CNN baseline.