 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
FlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Jan 08, 2023



Sequence-based deep learning recommendation models (DLRMs) are an emerging class of DLRMs showing great improvements over their prior sum-pooling based counterparts at capturing users' long term interests. These improvements come at immense system cost however, with sequence-based DLRMs requiring substantial amounts of data to be dynamically materialized and communicated by each accelerator during a single iteration. To address this rapidly growing bottleneck, we present FlexShard, a new tiered sequence embedding table sharding algorithm which operates at a per-row granularity by exploiting the insight that not every row is equal. Through precise replication of embedding rows based on their underlying probability distribution, along with the introduction of a new sharding strategy adapted to the heterogeneous, skewed performance of real-world cluster network topologies, FlexShard is able to significantly reduce communication demand while using no additional memory compared to the prior state-of-the-art. When evaluated on production-scale sequence DLRMs, FlexShard was able to reduce overall global all-to-all communication traffic by over 85%, resulting in end-to-end training communication latency improvements of almost 6x over the prior state-of-the-art approach.
RecShard: Statistical Feature-Based Memory Optimization for Industry-Scale Neural Recommendation
Jan 25, 2022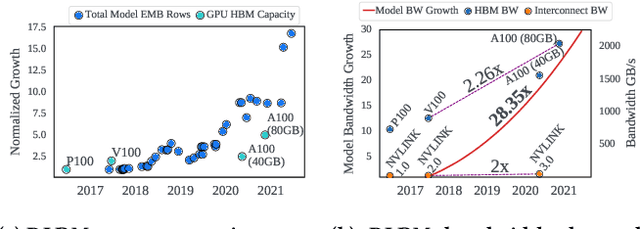
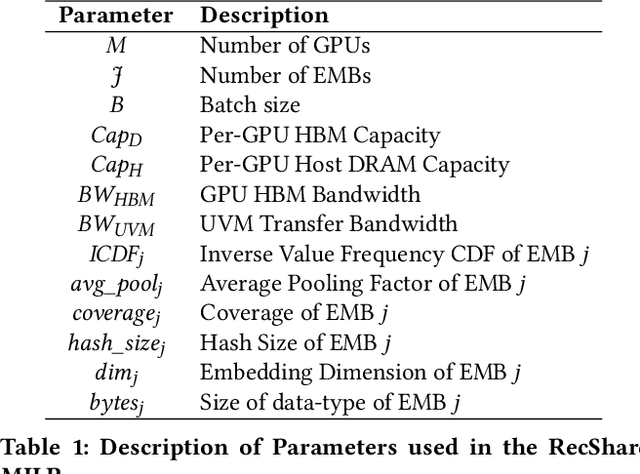
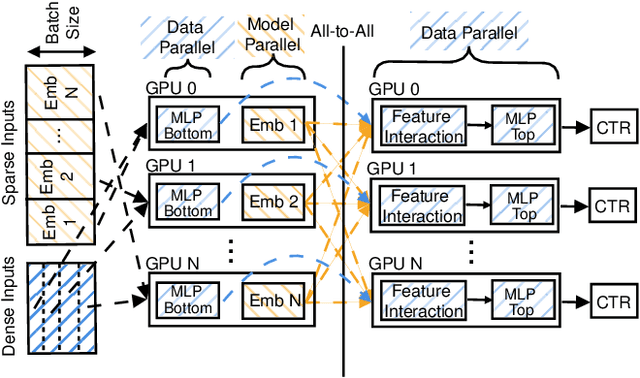
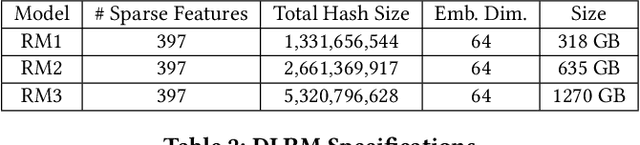
We propose RecShard, a fine-grained embedding table (EMB) partitioning and placement technique for deep learning recommendation models (DLRMs). RecShard is designed based on two key observations. First, not all EMBs are equal, nor all rows within an EMB are equal in terms of access patterns. EMBs exhibit distinct memory characteristics, providing performance optimization opportunities for intelligent EMB partitioning and placement across a tiered memory hierarchy. Second, in modern DLRMs, EMBs function as hash tables. As a result, EMBs display interesting phenomena, such as the birthday paradox, leaving EMBs severely under-utilized. RecShard determines an optimal EMB sharding strategy for a set of EMBs based on training data distributions and model characteristics, along with the bandwidth characteristics of the underlying tiered memory hierarchy. In doing so, RecShard achieves over 6 times higher EMB training throughput on average for capacity constrained DLRMs. The throughput increase comes from improved EMB load balance by over 12 times and from the reduced access to the slower memory by over 87 times.