 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
A Neural Network-based SAT-Resilient Obfuscation Towards Enhanced Logic Locking
Sep 13, 2022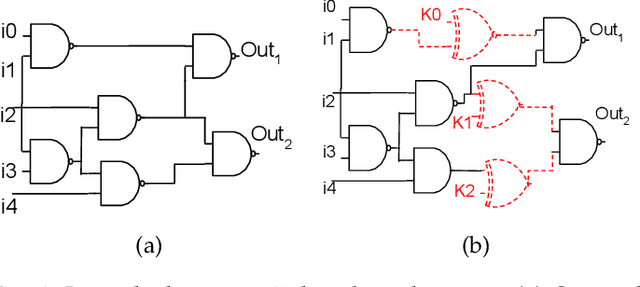
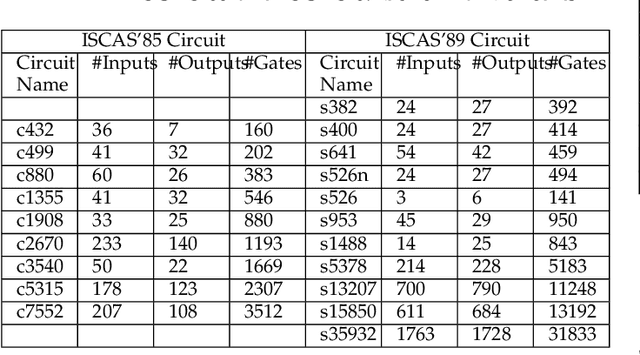
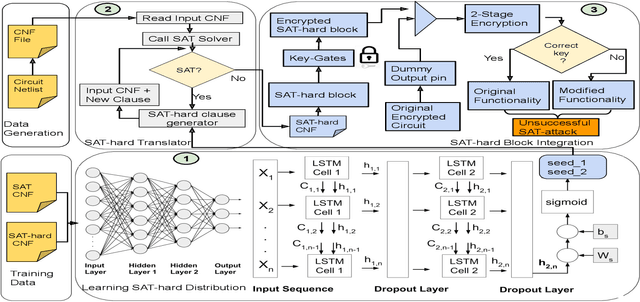
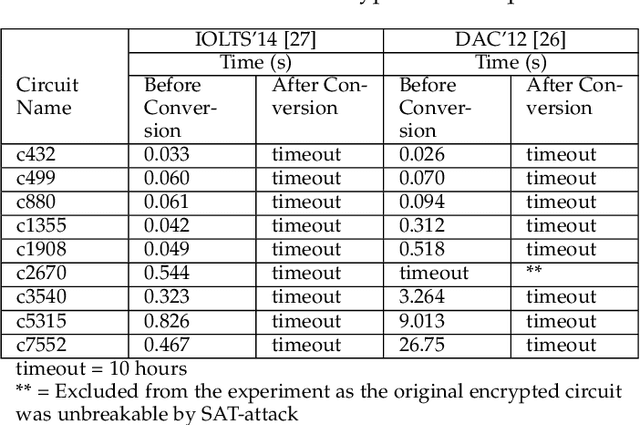
Logic obfuscation is introduced as a pivotal defense against multiple hardware threats on Integrated Circuits (ICs), including reverse engineering (RE) and intellectual property (IP) theft. The effectiveness of logic obfuscation is challenged by the recently introduced Boolean satisfiability (SAT) attack and its variants. A plethora of countermeasures has also been proposed to thwart the SAT attack. Irrespective of the implemented defense against SAT attacks, large power, performance, and area overheads are indispensable. In contrast, we propose a cognitive solution: a neural network-based unSAT clause translator, SATConda, that incurs a minimal area and power overhead while preserving the original functionality with impenetrable security. SATConda is incubated with an unSAT clause generator that translates the existing conjunctive normal form (CNF) through minimal perturbations such as the inclusion of pair of inverters or buffers or adding a new lightweight unSAT block depending on the provided CNF. For efficient unSAT clause generation, SATConda is equipped with a multi-layer neural network that first learns the dependencies of features (literals and clauses), followed by a long-short-term-memory (LSTM) network to validate and backpropagate the SAT-hardness for better learning and translation. Our proposed SATConda is evaluated on ISCAS85 and ISCAS89 benchmarks and is seen to defend against multiple state-of-the-art successfully SAT attacks devised for hardware RE. In addition, we also evaluate our proposed SATCondas empirical performance against MiniSAT, Lingeling and Glucose SAT solvers that form the base for numerous existing deobfuscation SAT attacks.
Estimating the Circuit Deobfuscating Runtime based on Graph Deep Learning
Feb 14, 2019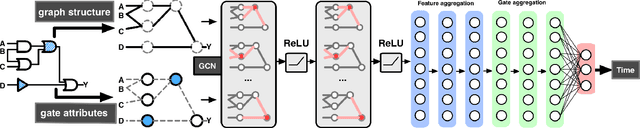
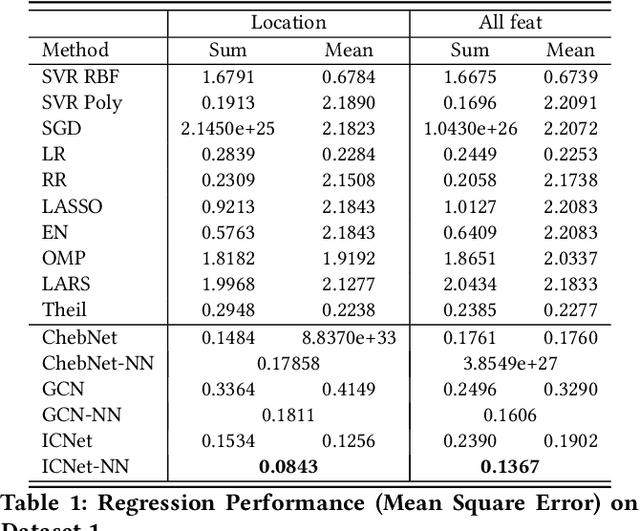
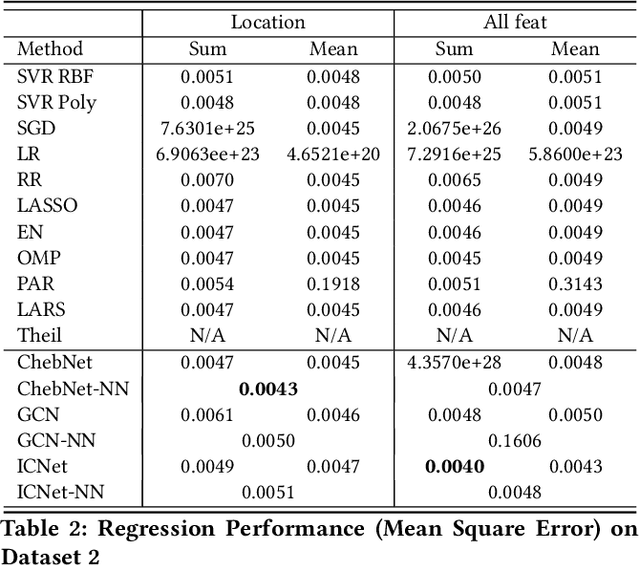
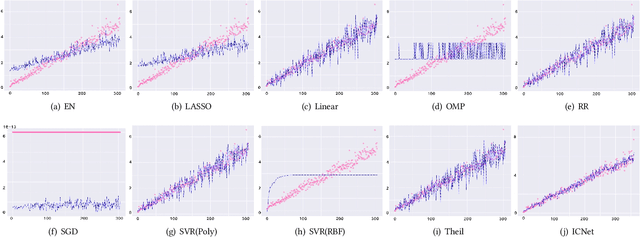
Circuit obfuscation is a recently proposed defense mechanism to protect digital integrated circuits (ICs) from reverse engineering by using camouflaged gates i.e., logic gates whose functionality cannot be precisely determined by the attacker. There have been effective schemes such as satisfiability-checking (SAT)-based attacks that can potentially decrypt obfuscated circuits, called deobfuscation. Deobfuscation runtime could have a large span ranging from few milliseconds to thousands of years or more, depending on the number and layouts of the ICs and camouflaged gates. And hence accurately pre-estimating the deobfuscation runtime is highly crucial for the defenders to maximize it and optimize their defense. However, estimating the deobfuscation runtime is a challenging task due to 1) the complexity and heterogeneity of graph-structured circuit, 2) the unknown and sophisticated mechanisms of the attackers for deobfuscation. To address the above mentioned challenges, this work proposes the first machine-learning framework that predicts the deobfuscation runtime based on graph deep learning techniques. Specifically, we design a new model, ICNet with new input and convolution layers to characterize and extract graph frequencies from ICs, which are then integrated by heterogeneous deep fully-connected layers to obtain final output. ICNet is an end-to-end framework which can automatically extract the determinant features for deobfuscation runtime. Extensive experiments demonstrate its effectiveness and efficiency.