 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025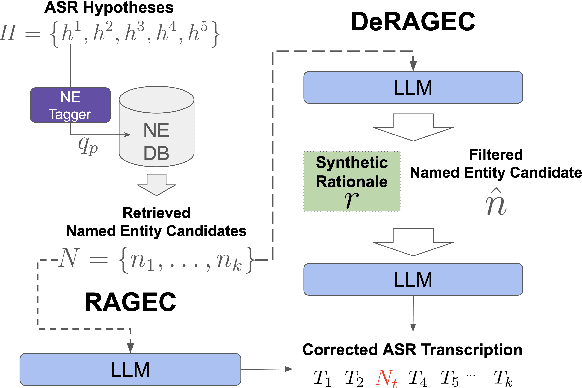
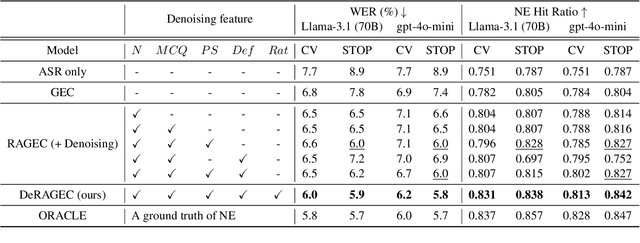
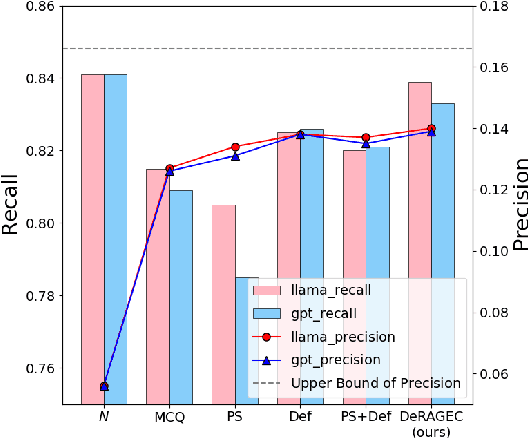
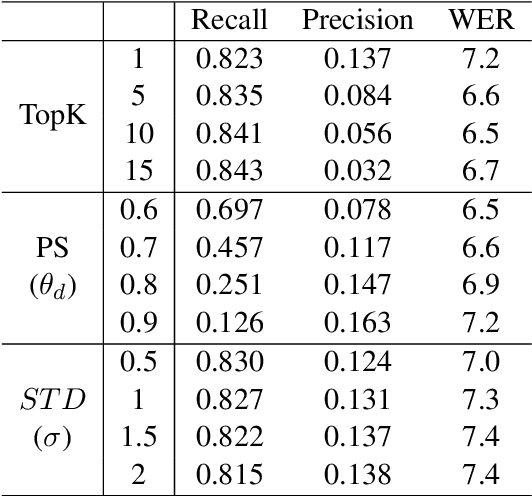
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec
DyPCL: Dynamic Phoneme-level Contrastive Learning for Dysarthric Speech Recognition
Jan 31, 2025Dysarthric speech recognition often suffers from performance degradation due to the intrinsic diversity of dysarthric severity and extrinsic disparity from normal speech. To bridge these gaps, we propose a Dynamic Phoneme-level Contrastive Learning (DyPCL) method, which leads to obtaining invariant representations across diverse speakers. We decompose the speech utterance into phoneme segments for phoneme-level contrastive learning, leveraging dynamic connectionist temporal classification alignment. Unlike prior studies focusing on utterance-level embeddings, our granular learning allows discrimination of subtle parts of speech. In addition, we introduce dynamic curriculum learning, which progressively transitions from easy negative samples to difficult-to-distinguishable negative samples based on phonetic similarity of phoneme. Our approach to training by difficulty levels alleviates the inherent variability of speakers, better identifying challenging speeches. Evaluated on the UASpeech dataset, DyPCL outperforms baseline models, achieving an average 22.10\% relative reduction in word error rate (WER) across the overall dysarthria group.
Keyword-Aware ASR Error Augmentation for Robust Dialogue State Tracking
Sep 10, 2024



Dialogue State Tracking (DST) is a key part of task-oriented dialogue systems, identifying important information in conversations. However, its accuracy drops significantly in spoken dialogue environments due to named entity errors from Automatic Speech Recognition (ASR) systems. We introduce a simple yet effective data augmentation method that targets those entities to improve the robustness of DST model. Our novel method can control the placement of errors using keyword-highlighted prompts while introducing phonetically similar errors. As a result, our method generated sufficient error patterns on keywords, leading to improved accuracy in noised and low-accuracy ASR environments.