 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenBibleTTS: Large-Scale Speech Resources and TTS Models for Low-Resource Languages
Jun 08, 2026Recent advances in neural text-to-speech (TTS) and multilingual speech generation have substantially improved synthetic speech quality, yet these gains remain unevenly distributed across the world's languages. Existing models are still dominated by a small set of high-resource languages, while many studies of low-resource TTS are simulated on artificially downsampled high-resource corpora that do not reflect the orthographic variation and limited phonetic coverage encountered in genuinely underrepresented settings. As such, we introduce OpenBibleTTS, which is a large-scale benchmark for low-resource speech synthesis spanning 37 underrepresented languages. Moreover, a systematic comparison of various TTS architectures and large-scale speech generation models is conducted across in-domain Biblical text and out-of-domain material. Results show that no single system dominates across languages and metrics: Gemini-TTS achieves the highest listener ratings on most evaluated languages, but monolingual EveryVoice models trained on OpenBibleTTS remain strongest for intelligibility and are preferred in several African languages, while open from-scratch systems degrade sharply on out-of-domain text, revealing a persistent gap between broad multilingual coverage and reliable synthesis quality in underserved linguistic communities. We complement automatic evaluation with subjective human judgments, and open-source all processed datasets, alignments, and trained models to support future low-resource TTS research.
SpeechJBB: Probing Safety Alignment and Comprehension in Large Audio Language Models under Code-Switched Speech
Jun 04, 2026Large audio language models (LALMs) are increasingly deployed in real-world applications, yet their safety alignment is still primarily evaluated on monolingual, text-based harmful prompts. This leaves their generalizability under multilingual and spoken settings, particularly code-switched speech, largely underexplored. To address this gap, we introduce SpeechJBB, an audio jailbreak dataset for benchmarking across multiple state-of-the-art LALMs. The extent of safety weaknesses is further probed by introducing an augmented setting where phonologically plausible pseudo-words are inserted around safety-critical terms to simulate localized obfuscation. Across models, code-switched harmful audio yields substantially high jailbreak success rates (JSR), with non-English monolingual and non-English code-switched pairs exhibiting the highest attack success. Pseudo-word insertion further reduces refusal rates, which demonstrates that natural-sounding obfuscation can effectively bypass safety policies.
PSY-STEP: Structuring Therapeutic Targets and Action Sequences for Proactive Counseling Dialogue Systems
Apr 06, 2026Cognitive Behavioral Therapy (CBT) aims to identify and restructure automatic negative thoughts pertaining to involuntary interpretations of events, yet existing counseling agents struggle to identify and address them in dialogue settings. To bridge this gap, we introduce STEP, a dataset that models CBT counseling by explicitly reflecting automatic thoughts alongside dynamic, action-level counseling sequences. Using this dataset, we train STEPPER, a counseling agent that proactively elicits automatic thoughts and executes cognitively grounded interventions. To further enhance both decision accuracy and empathic responsiveness, we refine STEPPER through preference learning based on simulated, synthesized counseling sessions. Extensive CBT-aligned evaluations show that STEPPER delivers more clinically grounded, coherent, and personalized counseling compared to other strong baseline models, and achieves higher counselor competence without inducing emotional disruption.
EnSToM: Enhancing Dialogue Systems with Entropy-Scaled Steering Vectors for Topic Maintenance
May 22, 2025Small large language models (sLLMs) offer the advantage of being lightweight and efficient, which makes them suitable for resource-constrained environments. However, sLLMs often struggle to maintain topic consistency in task-oriented dialogue systems, which is critical for scenarios such as service chatbots. Specifically, it is important to ensure that the model denies off-topic or malicious inputs and adheres to its intended functionality so as to prevent potential misuse and uphold reliability. Towards this, existing activation engineering approaches have been proposed to manipulate internal activations during inference. While these methods are effective in certain scenarios, our preliminary experiments reveal their limitations in ensuring topic adherence. Therefore, to address this, we propose a novel approach termed Entropy-scaled Steering vectors for Topic Maintenance (EnSToM). EnSToM dynamically adjusts the steering intensity based on input uncertainty, which allows the model to handle off-topic distractors effectively while preserving on-topic accuracy. Our experiments demonstrate that EnSToM achieves significant performance gain with a relatively small data size compared to fine-tuning approaches. By improving topic adherence without compromising efficiency, our approach provides a robust solution for enhancing sLLM-based dialogue systems.
PicPersona-TOD : A Dataset for Personalizing Utterance Style in Task-Oriented Dialogue with Image Persona
Apr 24, 2025



Task-Oriented Dialogue (TOD) systems are designed to fulfill user requests through natural language interactions, yet existing systems often produce generic, monotonic responses that lack individuality and fail to adapt to users' personal attributes. To address this, we introduce PicPersona-TOD, a novel dataset that incorporates user images as part of the persona, enabling personalized responses tailored to user-specific factors such as age or emotional context. This is facilitated by first impressions, dialogue policy-guided prompting, and the use of external knowledge to reduce hallucinations. Human evaluations confirm that our dataset enhances user experience, with personalized responses contributing to a more engaging interaction. Additionally, we introduce a new NLG model, Pictor, which not only personalizes responses, but also demonstrates robust performance across unseen domains https://github.com/JihyunLee1/PicPersona.
Mirror: Multimodal Cognitive Reframing Therapy for Rolling with Resistance
Apr 16, 2025
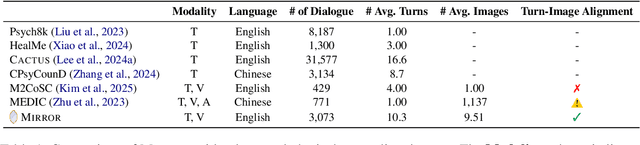
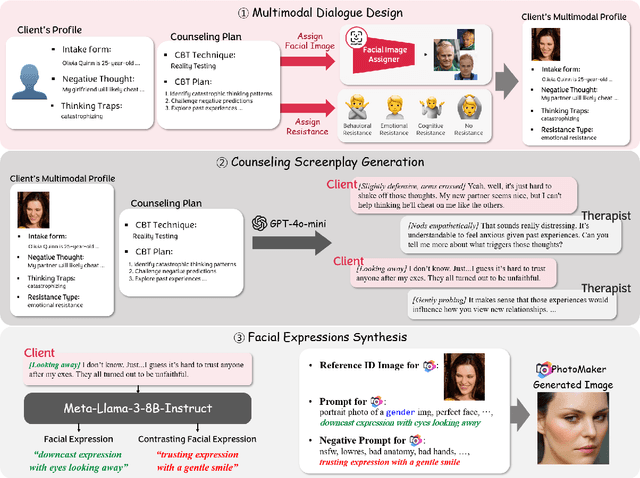
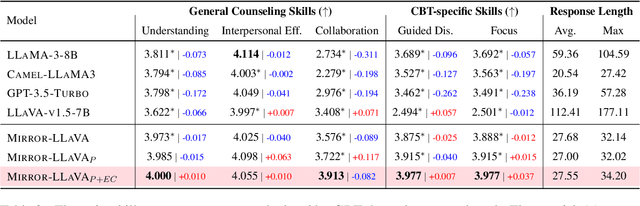
Recent studies have explored the use of large language models (LLMs) in psychotherapy; however, text-based cognitive behavioral therapy (CBT) models often struggle with client resistance, which can weaken therapeutic alliance. To address this, we propose a multimodal approach that incorporates nonverbal cues, allowing the AI therapist to better align its responses with the client's negative emotional state. Specifically, we introduce a new synthetic dataset, Multimodal Interactive Rolling with Resistance (Mirror), which is a novel synthetic dataset that pairs client statements with corresponding facial images. Using this dataset, we train baseline Vision-Language Models (VLMs) that can analyze facial cues, infer emotions, and generate empathetic responses to effectively manage resistance. They are then evaluated in terms of both the therapist's counseling skills and the strength of the therapeutic alliance in the presence of client resistance. Our results demonstrate that Mirror significantly enhances the AI therapist's ability to handle resistance, which outperforms existing text-based CBT approaches.
Retrieval-Augmented Fine-Tuning With Preference Optimization For Visual Program Generation
Feb 23, 2025



Visual programming languages (VPLs) allow users to create programs through graphical interfaces, which results in easier accessibility and their widespread usage in various domains. To further enhance this accessibility, recent research has focused on generating VPL code from user instructions using large language models (LLMs). Specifically, by employing prompting-based methods, these studies have shown promising results. Nevertheless, such approaches can be less effective for industrial VPLs such as Ladder Diagram (LD). LD is a pivotal language used in industrial automation processes and involves extensive domain-specific configurations, which are difficult to capture in a single prompt. In this work, we demonstrate that training-based methods outperform prompting-based methods for LD generation accuracy, even with smaller backbone models. Building on these findings, we propose a two-stage training strategy to further enhance VPL generation. First, we employ retrieval-augmented fine-tuning to leverage the repetitive use of subroutines commonly seen in industrial VPLs. Second, we apply direct preference optimization (DPO) to further guide the model toward accurate outputs, using systematically generated preference pairs through graph editing operations. Extensive experiments on real-world LD data demonstrate that our approach improves program-level accuracy by over 10% compared to supervised fine-tuning, which highlights its potential to advance industrial automation.
Audio-Based Linguistic Feature Extraction for Enhancing Multi-lingual and Low-Resource Text-to-Speech
Sep 27, 2024The difficulty of acquiring abundant, high-quality data, especially in multi-lingual contexts, has sparked interest in addressing low-resource scenarios. Moreover, current literature rely on fixed expressions from language IDs, which results in the inadequate learning of language representations, and the failure to generate speech in unseen languages. To address these challenges, we propose a novel method that directly extracts linguistic features from audio input while effectively filtering out miscellaneous acoustic information including speaker-specific attributes like timbre. Subjective and objective evaluations affirm the effectiveness of our approach for multi-lingual text-to-speech, and highlight its superiority in low-resource transfer learning for previously unseen language.
An Investigation Into Explainable Audio Hate Speech Detection
Aug 12, 2024Research on hate speech has predominantly revolved around detection and interpretation from textual inputs, leaving verbal content largely unexplored. While there has been limited exploration into hate speech detection within verbal acoustic speech inputs, the aspect of interpretability has been overlooked. Therefore, we introduce a new task of explainable audio hate speech detection. Specifically, we aim to identify the precise time intervals, referred to as audio frame-level rationales, which serve as evidence for hate speech classification. Towards this end, we propose two different approaches: cascading and End-to-End (E2E). The cascading approach initially converts audio to transcripts, identifies hate speech within these transcripts, and subsequently locates the corresponding audio time frames. Conversely, the E2E approach processes audio utterances directly, which allows it to pinpoint hate speech within specific time frames. Additionally, due to the lack of explainable audio hate speech datasets that include audio frame-level rationales, we curated a synthetic audio dataset to train our models. We further validated these models on actual human speech utterances and found that the E2E approach outperforms the cascading method in terms of the audio frame Intersection over Union (IoU) metric. Furthermore, we observed that including frame-level rationales significantly enhances hate speech detection accuracy for the E2E approach. \textbf{Disclaimer} The reader may encounter content of an offensive or hateful nature. However, given the nature of the work, this cannot be avoided.
Leveraging the Interplay Between Syntactic and Acoustic Cues for Optimizing Korean TTS Pause Formation
Apr 03, 2024



Contemporary neural speech synthesis models have indeed demonstrated remarkable proficiency in synthetic speech generation as they have attained a level of quality comparable to that of human-produced speech. Nevertheless, it is important to note that these achievements have predominantly been verified within the context of high-resource languages such as English. Furthermore, the Tacotron and FastSpeech variants show substantial pausing errors when applied to the Korean language, which affects speech perception and naturalness. In order to address the aforementioned issues, we propose a novel framework that incorporates comprehensive modeling of both syntactic and acoustic cues that are associated with pausing patterns. Remarkably, our framework possesses the capability to consistently generate natural speech even for considerably more extended and intricate out-of-domain (OOD) sentences, despite its training on short audio clips. Architectural design choices are validated through comparisons with baseline models and ablation studies using subjective and objective metrics, thus confirming model performance.