 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-dependent self-exciting point processes: models, methods, and risk bounds in high dimensions
Mar 16, 2020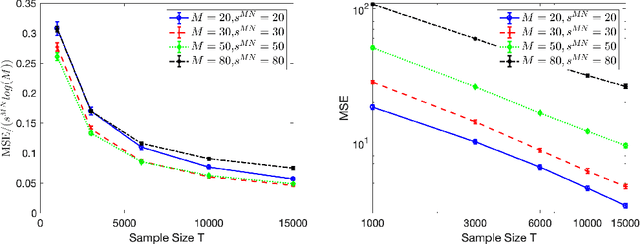
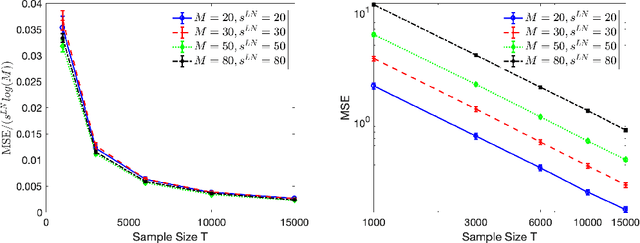
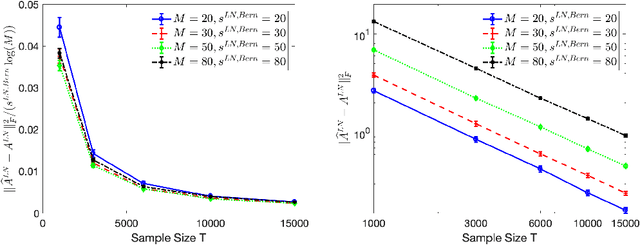
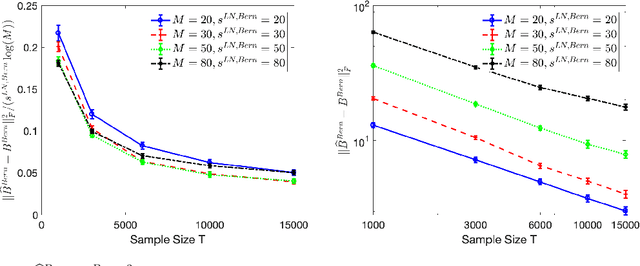
High-dimensional autoregressive point processes model how current events trigger or inhibit future events, such as activity by one member of a social network can affect the future activity of his or her neighbors. While past work has focused on estimating the underlying network structure based solely on the times at which events occur on each node of the network, this paper examines the more nuanced problem of estimating context-dependent networks that reflect how features associated with an event (such as the content of a social media post) modulate the strength of influences among nodes. Specifically, we leverage ideas from compositional time series and regularization methods in machine learning to conduct network estimation for high-dimensional marked point processes. Two models and corresponding estimators are considered in detail: an autoregressive multinomial model suited to categorical marks and a logistic-normal model suited to marks with mixed membership in different categories. Importantly, the logistic-normal model leads to a convex negative log-likelihood objective and captures dependence across categories. We provide theoretical guarantees for both estimators, which we validate by simulations and a synthetic data-generating model. We further validate our methods through two real data examples and demonstrate the advantages and disadvantages of both approaches.
ISLET: Fast and Optimal Low-rank Tensor Regression via Importance Sketching
Nov 09, 2019
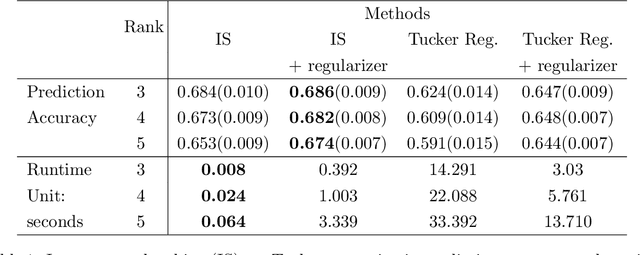
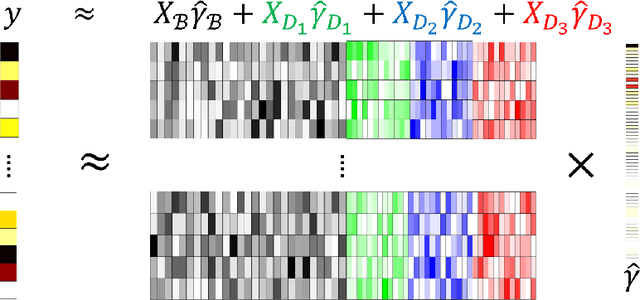
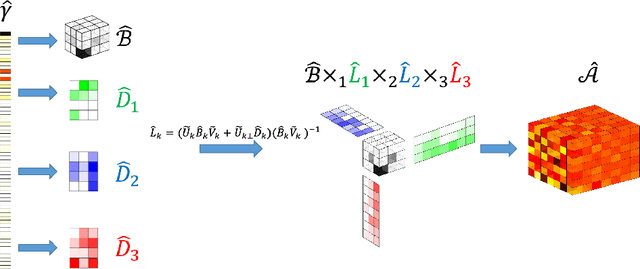
In this paper, we develop a novel procedure for low-rank tensor regression, namely \underline{I}mportance \underline{S}ketching \underline{L}ow-rank \underline{E}stimation for \underline{T}ensors (ISLET). The central idea behind ISLET is \emph{importance sketching}, i.e., carefully designed sketches based on both the responses and low-dimensional structure of the parameter of interest. We show that the proposed method is sharply minimax optimal in terms of the mean-squared error under low-rank Tucker assumptions and under randomized Gaussian ensemble design. In addition, if a tensor is low-rank with group sparsity, our procedure also achieves minimax optimality. Further, we show through numerical studies that ISLET achieves comparable or better mean-squared error performance to existing state-of-the-art methods whilst having substantial storage and run-time advantages including capabilities for parallel and distributed computing. In particular, our procedure performs reliable estimation with tensors of dimension $p = O(10^8)$ and is $1$ or $2$ orders of magnitude faster than baseline methods.
Minimizing Negative Transfer of Knowledge in Multivariate Gaussian Processes: A Scalable and Regularized Approach
Mar 31, 2019
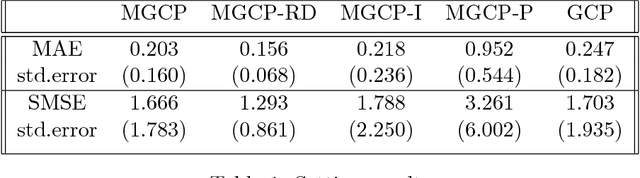
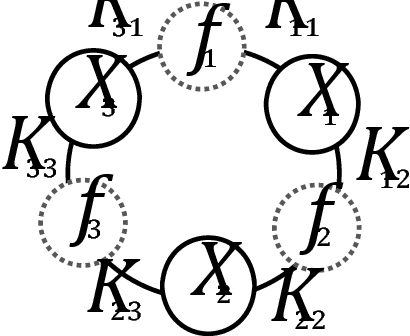
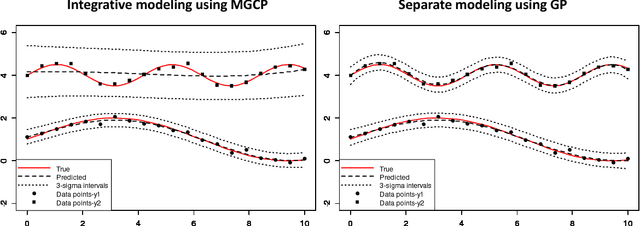
Recently there has been an increasing interest in the multivariate Gaussian process (MGP) which extends the Gaussian process (GP) to deal with multiple outputs. One approach to construct the MGP and account for non-trivial commonalities amongst outputs employs a convolution process (CP). The CP is based on the idea of sharing latent functions across several convolutions. Despite the elegance of the CP construction, it provides new challenges that need yet to be tackled. First, even with a moderate number of outputs, model building is extremely prohibitive due to the huge increase in computational demands and number of parameters to be estimated. Second, the negative transfer of knowledge may occur when some outputs do not share commonalities. In this paper we address these issues. We propose a regularized pairwise modeling approach for the MGP established using CP. The key feature of our approach is to distribute the estimation of the full multivariate model into a group of bivariate GPs which are individually built. Interestingly pairwise modeling turns out to possess unique characteristics, which allows us to tackle the challenge of negative transfer through penalizing the latent function that facilitates information sharing in each bivariate model. Predictions are then made through combining predictions from the bivariate models within a Bayesian framework. The proposed method has excellent scalability when the number of outputs is large and minimizes the negative transfer of knowledge between uncorrelated outputs. Statistical guarantees for the proposed method are studied and its advantageous features are demonstrated through numerical studies.
Estimating Network Structure from Incomplete Event Data
Nov 07, 2018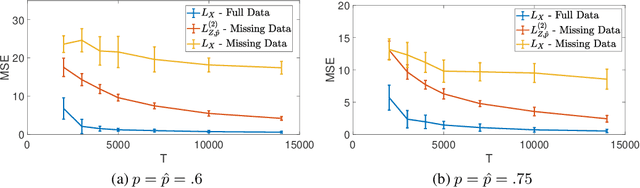
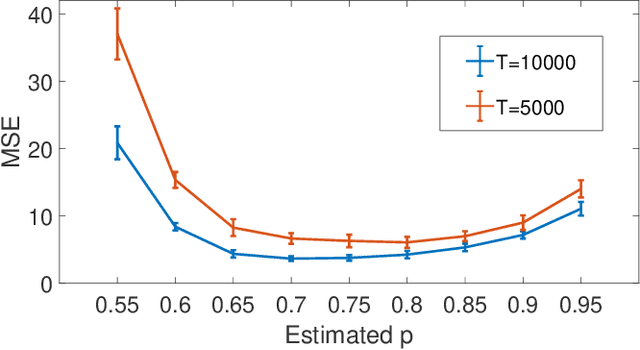
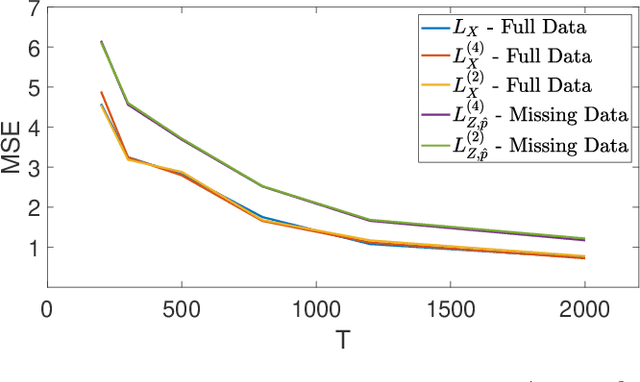
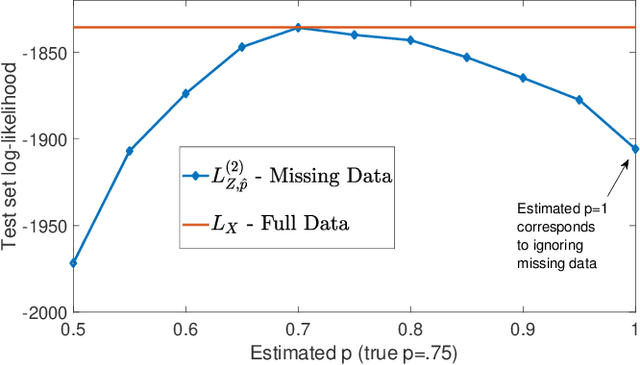
Multivariate Bernoulli autoregressive (BAR) processes model time series of events in which the likelihood of current events is determined by the times and locations of past events. These processes can be used to model nonlinear dynamical systems corresponding to criminal activity, responses of patients to different medical treatment plans, opinion dynamics across social networks, epidemic spread, and more. Past work examines this problem under the assumption that the event data is complete, but in many cases only a fraction of events are observed. Incomplete observations pose a significant challenge in this setting because the unobserved events still govern the underlying dynamical system. In this work, we develop a novel approach to estimating the parameters of a BAR process in the presence of unobserved events via an unbiased estimator of the complete data log-likelihood function. We propose a computationally efficient estimation algorithm which approximates this estimator via Taylor series truncation and establish theoretical results for both the statistical error and optimization error of our algorithm. We further justify our approach by testing our method on both simulated data and a real data set consisting of crimes recorded by the city of Chicago.
Graph-based regularization for regression problems with highly-correlated designs
Jun 05, 2018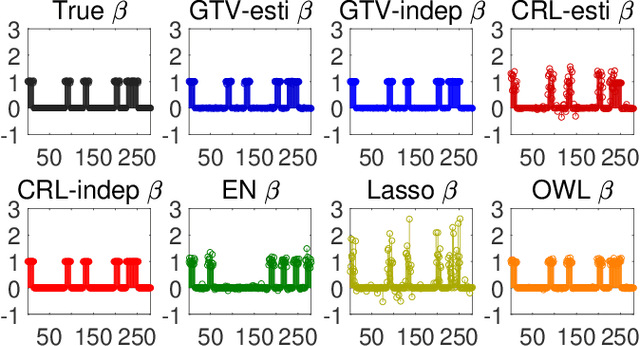
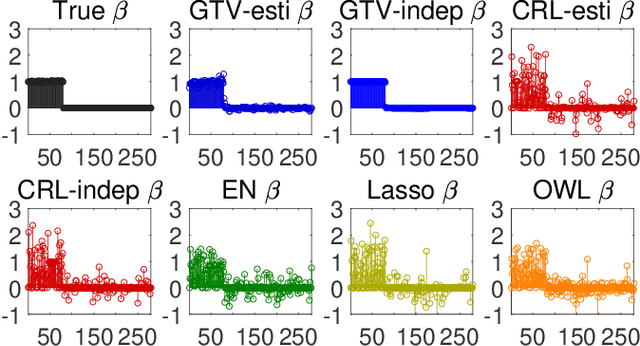
Sparse models for high-dimensional linear regression and machine learning have received substantial attention over the past two decades. Model selection, or determining which features or covariates are the best explanatory variables, is critical to the interpretability of a learned model. Much of the current literature assumes that covariates are only mildly correlated. However, in modern applications ranging from functional MRI to genome-wide association studies, covariates are highly correlated and do not exhibit key properties (such as the restricted eigenvalue condition, RIP, or other related assumptions). This paper considers a high-dimensional regression setting in which a graph governs both correlations among the covariates and the similarity among regression coefficients. Using side information about the strength of correlations among features, we form a graph with edge weights corresponding to pairwise covariances. This graph is used to define a graph total variation regularizer that promotes similar weights for highly correlated features. The graph structure encapsulated by this regularizer helps precondition correlated features to yield provably accurate estimates. Using graph-based regularizers to develop theoretical guarantees for highly-correlated covariates has not been previously examined. This paper shows how our proposed graph-based regularization yields mean-squared error guarantees for a broad range of covariance graph structures and correlation strengths which in many cases are optimal by imposing additional structure on $\beta^{\star}$ which encourages \emph{alignment} with the covariance graph. Our proposed approach outperforms other state-of-the-art methods for highly-correlated design in a variety of experiments on simulated and real fMRI data.
Network Estimation from Point Process Data
Feb 13, 2018
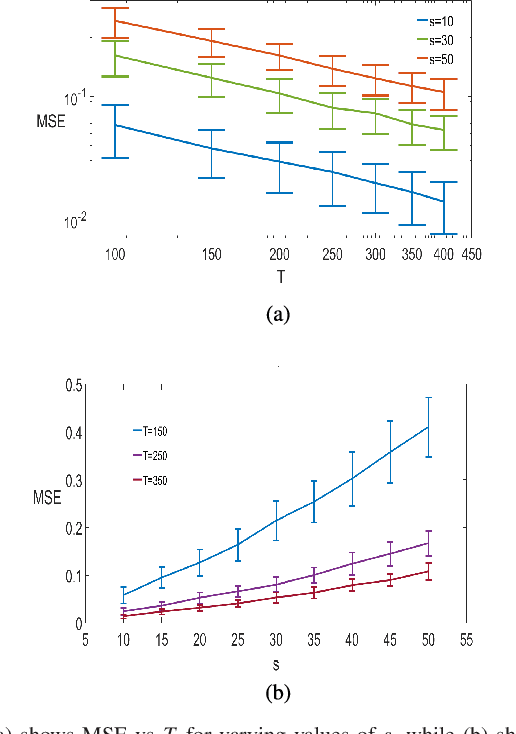
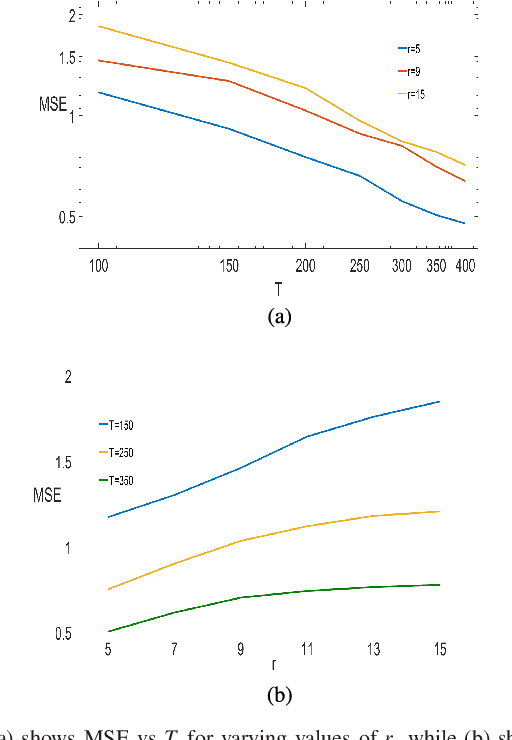
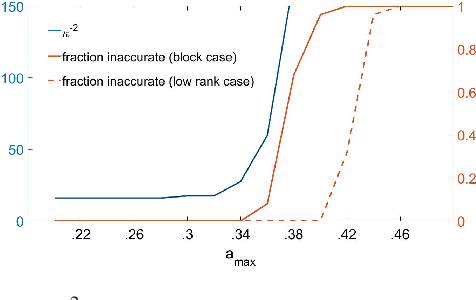
Consider observing a collection of discrete events within a network that reflect how network nodes influence one another. Such data are common in spike trains recorded from biological neural networks, interactions within a social network, and a variety of other settings. Data of this form may be modeled as self-exciting point processes, in which the likelihood of future events depends on the past events. This paper addresses the problem of estimating self-excitation parameters and inferring the underlying functional network structure from self-exciting point process data. Past work in this area was limited by strong assumptions which are addressed by the novel approach here. Specifically, in this paper we (1) incorporate saturation in a point process model which both ensures stability and models non-linear thresholding effects; (2) impose general low-dimensional structural assumptions that include sparsity, group sparsity and low-rankness that allows bounds to be developed in the high-dimensional setting; and (3) incorporate long-range memory effects through moving average and higher-order auto-regressive components. Using our general framework, we provide a number of novel theoretical guarantees for high-dimensional self-exciting point processes that reflect the role played by the underlying network structure and long-term memory. We also provide simulations and real data examples to support our methodology and main results.
Non-parametric Sparse Additive Auto-regressive Network Models
Jan 24, 2018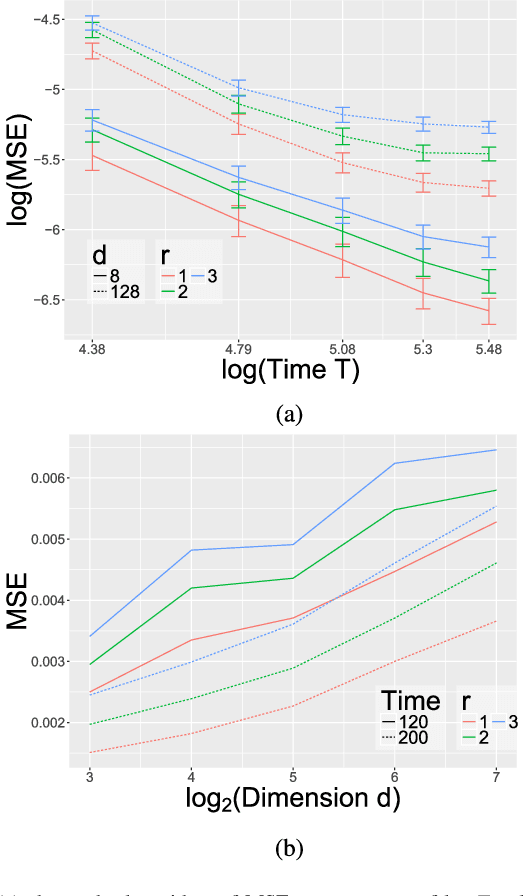
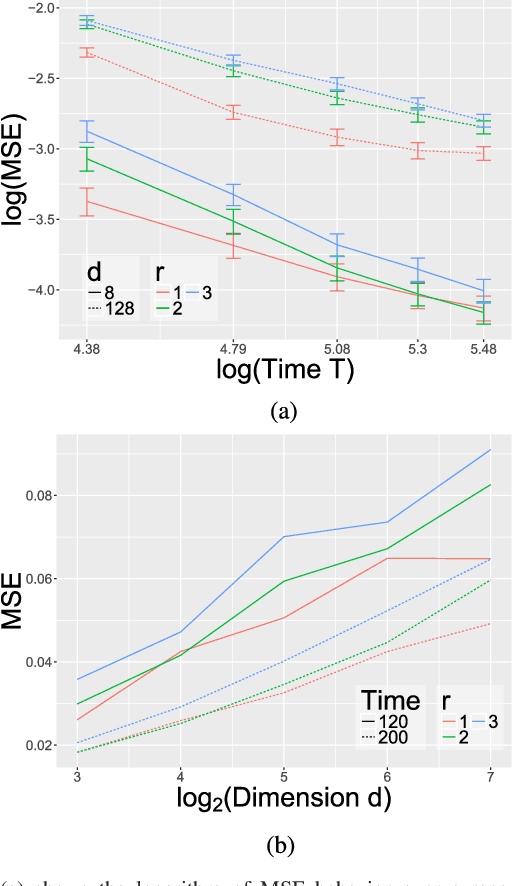
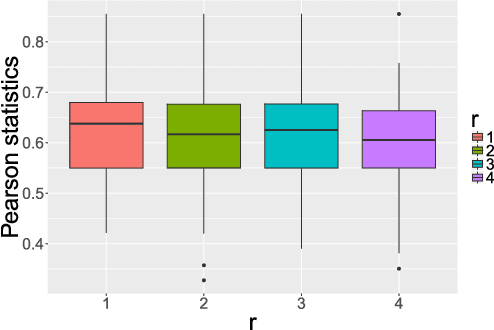
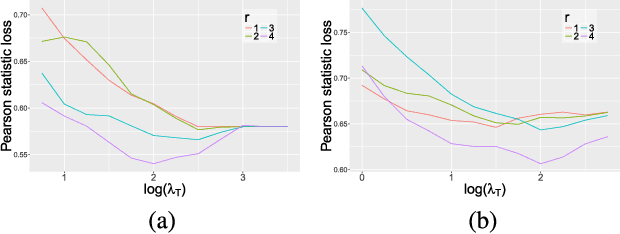
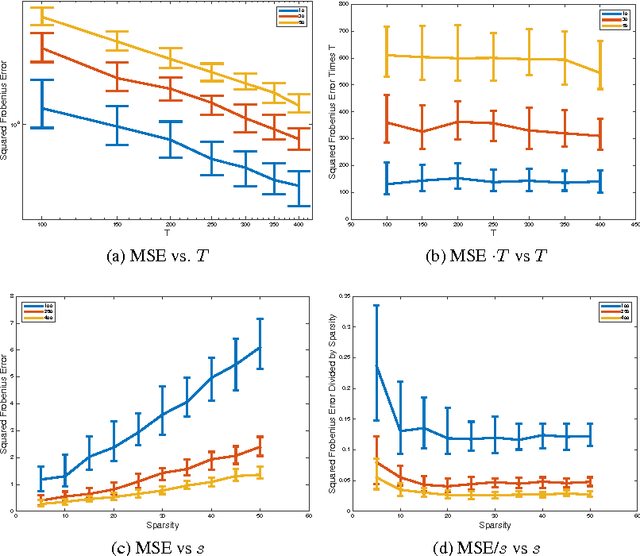
Consider a multi-variate time series $(X_t)_{t=0}^{T}$ where $X_t \in \mathbb{R}^d$ which may represent spike train responses for multiple neurons in a brain, crime event data across multiple regions, and many others. An important challenge associated with these time series models is to estimate an influence network between the $d$ variables, especially when the number of variables $d$ is large meaning we are in the high-dimensional setting. Prior work has focused on parametric vector auto-regressive models. However, parametric approaches are somewhat restrictive in practice. In this paper, we use the non-parametric sparse additive model (SpAM) framework to address this challenge. Using a combination of $\beta$ and $\phi$-mixing properties of Markov chains and empirical process techniques for reproducing kernel Hilbert spaces (RKHSs), we provide upper bounds on mean-squared error in terms of the sparsity $s$, logarithm of the dimension $\log d$, number of time points $T$, and the smoothness of the RKHSs. Our rates are sharp up to logarithm factors in many cases. We also provide numerical experiments that support our theoretical results and display potential advantages of using our non-parametric SpAM framework for a Chicago crime dataset.
Inference of High-dimensional Autoregressive Generalized Linear Models
Jun 24, 2017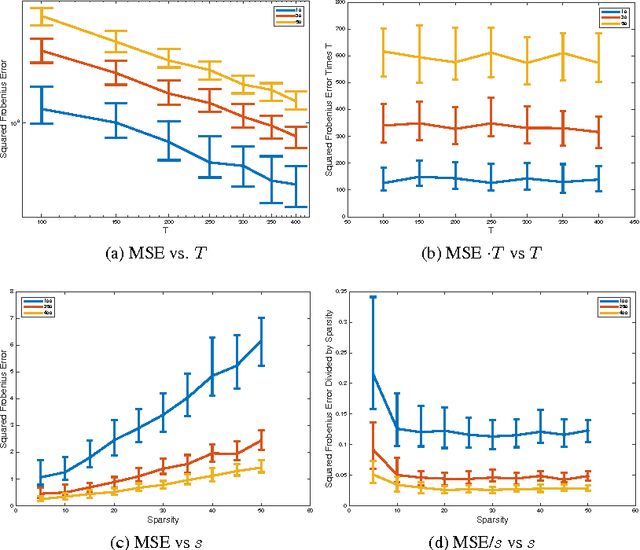

Vector autoregressive models characterize a variety of time series in which linear combinations of current and past observations can be used to accurately predict future observations. For instance, each element of an observation vector could correspond to a different node in a network, and the parameters of an autoregressive model would correspond to the impact of the network structure on the time series evolution. Often these models are used successfully in practice to learn the structure of social, epidemiological, financial, or biological neural networks. However, little is known about statistical guarantees on estimates of such models in non-Gaussian settings. This paper addresses the inference of the autoregressive parameters and associated network structure within a generalized linear model framework that includes Poisson and Bernoulli autoregressive processes. At the heart of this analysis is a sparsity-regularized maximum likelihood estimator. While sparsity-regularization is well-studied in the statistics and machine learning communities, those analysis methods cannot be applied to autoregressive generalized linear models because of the correlations and potential heteroscedasticity inherent in the observations. Sample complexity bounds are derived using a combination of martingale concentration inequalities and modern empirical process techniques for dependent random variables. These bounds, which are supported by several simulation studies, characterize the impact of various network parameters on estimator performance.
Learning Quadratic Variance Function (QVF) DAG models via OverDispersion Scoring (ODS)
Apr 28, 2017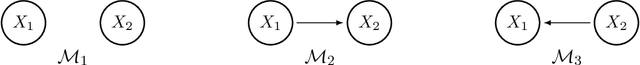
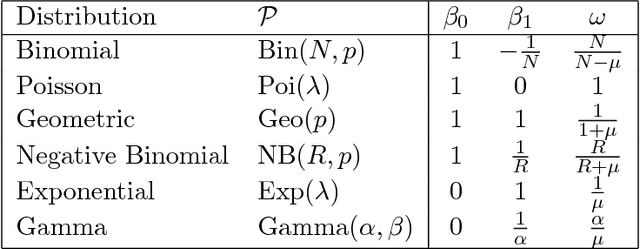


Learning DAG or Bayesian network models is an important problem in multi-variate causal inference. However, a number of challenges arises in learning large-scale DAG models including model identifiability and computational complexity since the space of directed graphs is huge. In this paper, we address these issues in a number of steps for a broad class of DAG models where the noise or variance is signal-dependent. Firstly we introduce a new class of identifiable DAG models, where each node has a distribution where the variance is a quadratic function of the mean (QVF DAG models). Our QVF DAG models include many interesting classes of distributions such as Poisson, Binomial, Geometric, Exponential, Gamma and many other distributions in which the noise variance depends on the mean. We prove that this class of QVF DAG models is identifiable, and introduce a new algorithm, the OverDispersion Scoring (ODS) algorithm, for learning large-scale QVF DAG models. Our algorithm is based on firstly learning the moralized or undirected graphical model representation of the DAG to reduce the DAG search-space, and then exploiting the quadratic variance property to learn the causal ordering. We show through theoretical results and simulations that our algorithm is statistically consistent in the high-dimensional p>n setting provided that the degree of the moralized graph is bounded and performs well compared to state-of-the-art DAG-learning algorithms.
Non-Convex Projected Gradient Descent for Generalized Low-Rank Tensor Regression
Nov 30, 2016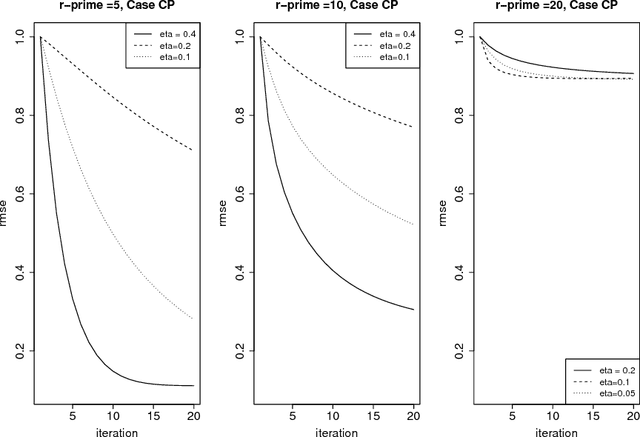
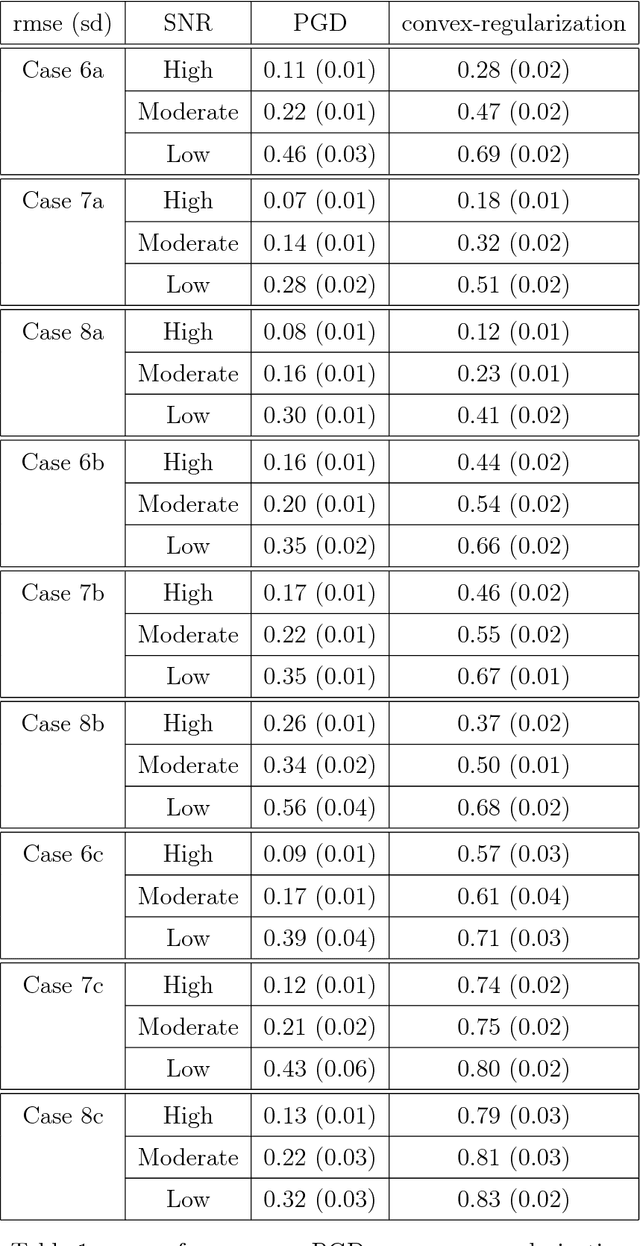
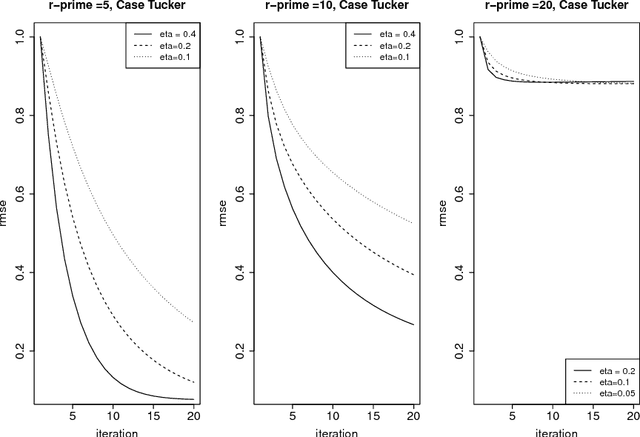
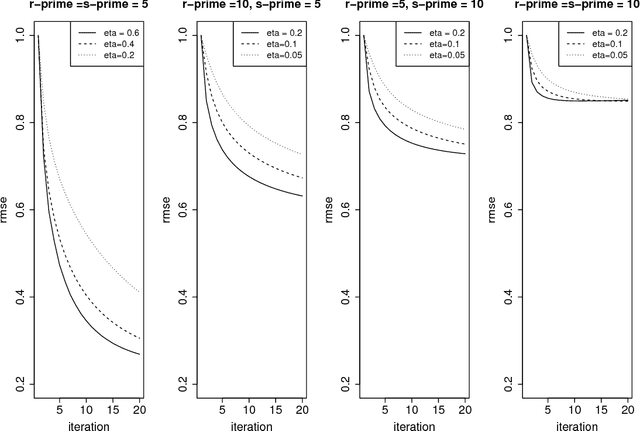
In this paper, we consider the problem of learning high-dimensional tensor regression problems with low-rank structure. One of the core challenges associated with learning high-dimensional models is computation since the underlying optimization problems are often non-convex. While convex relaxations could lead to polynomial-time algorithms they are often slow in practice. On the other hand, limited theoretical guarantees exist for non-convex methods. In this paper we provide a general framework that provides theoretical guarantees for learning high-dimensional tensor regression models under different low-rank structural assumptions using the projected gradient descent algorithm applied to a potentially non-convex constraint set $\Theta$ in terms of its \emph{localized Gaussian width}. We juxtapose our theoretical results for non-convex projected gradient descent algorithms with previous results on regularized convex approaches. The two main differences between the convex and non-convex approach are: (i) from a computational perspective whether the non-convex projection operator is computable and whether the projection has desirable contraction properties and (ii) from a statistical upper bound perspective, the non-convex approach has a superior rate for a number of examples. We provide three concrete examples of low-dimensional structure which address these issues and explain the pros and cons for the non-convex and convex approaches. We supplement our theoretical results with simulations which show that, under several common settings of generalized low rank tensor regression, the projected gradient descent approach is superior both in terms of statistical error and run-time provided the step-sizes of the projected descent algorithm are suitably chosen.