 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Distance Operator Transport: A Convex and Geometry-Preserving Formulation
Jun 01, 2026We introduce Convex Distance Operator Transport (CDOT), the first convex optimal transport framework that aligns distributions across heterogeneous domains by jointly preserving feature correspondence and intrinsic geometric structure. Specifically, CDOT employs an operator-based regularization that aligns aggregated distance structures by introducing distance and conditional expectation operators. Consequently, the proposed regularization improves the robustness to local geometric variations. We further prove that the resulting CDOT discrepancy is a valid pseudometric on the space of attributed compact metric-measure spaces. In addition, we characterize the relationship between CDOT and Gromov--Wasserstein (GW) through a new notion of dispersion gap, formally elucidating the geometric source of non-convexity in GW compared to the convexity of CDOT. In the finite-sample regime, we derive a non-asymptotic risk bound decomposed into optimization and statistical errors, establishing risk consistency under a globally convergent Frank--Wolfe algorithm. Experiments on synthetic point clouds, brain connectomes, and graph classification benchmarks demonstrate better performance over existing methods, with stable and reliable behavior in practice.
Bayesian Approach to Linear Bayesian Networks
Nov 27, 2023This study proposes the first Bayesian approach for learning high-dimensional linear Bayesian networks. The proposed approach iteratively estimates each element of the topological ordering from backward and its parent using the inverse of a partial covariance matrix. The proposed method successfully recovers the underlying structure when Bayesian regularization for the inverse covariance matrix with unequal shrinkage is applied. Specifically, it shows that the number of samples $n = \Omega( d_M^2 \log p)$ and $n = \Omega(d_M^2 p^{2/m})$ are sufficient for the proposed algorithm to learn linear Bayesian networks with sub-Gaussian and 4m-th bounded-moment error distributions, respectively, where $p$ is the number of nodes and $d_M$ is the maximum degree of the moralized graph. The theoretical findings are supported by extensive simulation studies including real data analysis. Furthermore the proposed method is demonstrated to outperform state-of-the-art frequentist approaches, such as the BHLSM, LISTEN, and TD algorithms in synthetic data.
Identifiability of Gaussian Structural Equation Models with Homogeneous and Heterogeneous Error Variances
Jan 29, 2019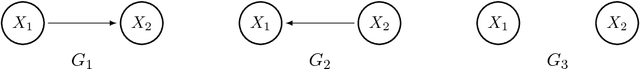
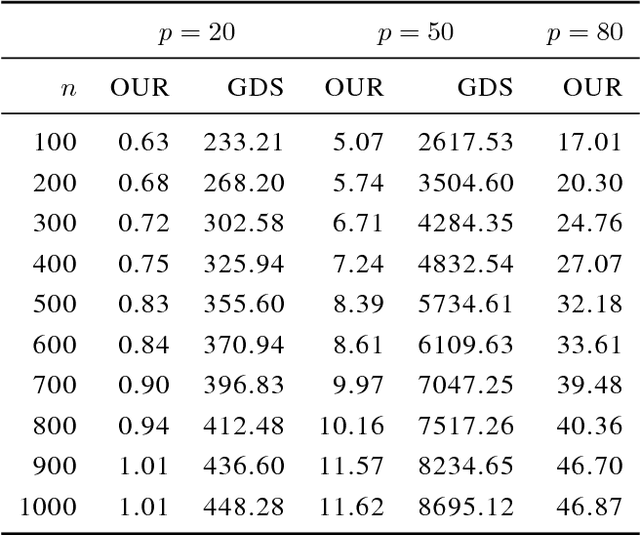


In this work, we consider the identifiability assumption of Gaussian structural equation models (SEMs) in which each variable is determined by a linear function of its parents plus normally distributed error. It has been shown that linear Gaussian structural equation models are fully identifiable if all error variances are the same or known. Hence, this work proves the identifiability of Gaussian SEMs with both homogeneous and heterogeneous unknown error variances. Our new identifiability assumption exploits not only error variances, but edge weights; hence, it is strictly milder than prior work on the identifiability result. We further provide a structure learning algorithm that is statistically consistent and computationally feasible, based on our new assumption. The proposed algorithm assumes that all relevant variables are observed, while it does not assume causal minimality and faithfulness. We verify our theoretical findings through simulations, and compare our algorithm to state-of-the-art PC, GES and GDS algorithms.
Learning Generalized Hypergeometric Distribution (GHD) DAG models
May 08, 2018
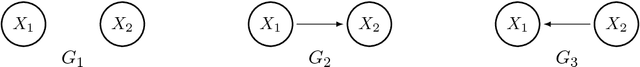
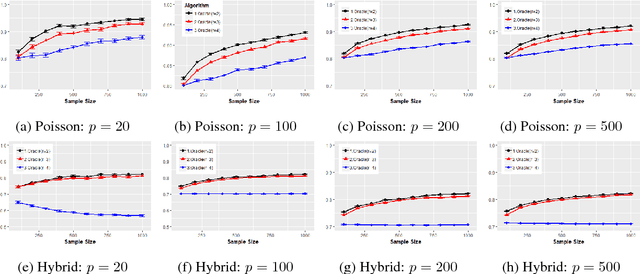

We introduce a new class of identifiable DAG models, where each node has a conditional distribution given its parents belongs to a family of generalized hypergeometric distributions (GHD). a family of generalized hypergeometric distributions (GHD) includes a lot of discrete distributions such as Binomial, Beta-binomial, Poisson, Poisson type, displaced Poisson, hyper-Poisson, logarithmic, and many more. We prove that if the data drawn from the new class of DAG models, one can fully identify the graph. We further provide a reliable and tractable algorithm that recovers the directed graph from finitely many data. We show through theoretical results and simulations that our algorithm is statistically consistent even in high-dimensional settings ($n >p$) if the degree of the graph is bounded, and performs well compared to state-of-the-art DAG-learning algorithms.
Learning Quadratic Variance Function (QVF) DAG models via OverDispersion Scoring (ODS)
Apr 28, 2017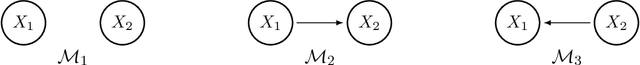
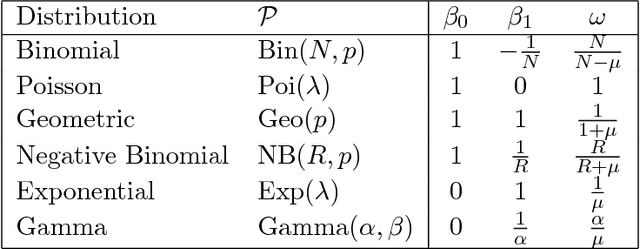


Learning DAG or Bayesian network models is an important problem in multi-variate causal inference. However, a number of challenges arises in learning large-scale DAG models including model identifiability and computational complexity since the space of directed graphs is huge. In this paper, we address these issues in a number of steps for a broad class of DAG models where the noise or variance is signal-dependent. Firstly we introduce a new class of identifiable DAG models, where each node has a distribution where the variance is a quadratic function of the mean (QVF DAG models). Our QVF DAG models include many interesting classes of distributions such as Poisson, Binomial, Geometric, Exponential, Gamma and many other distributions in which the noise variance depends on the mean. We prove that this class of QVF DAG models is identifiable, and introduce a new algorithm, the OverDispersion Scoring (ODS) algorithm, for learning large-scale QVF DAG models. Our algorithm is based on firstly learning the moralized or undirected graphical model representation of the DAG to reduce the DAG search-space, and then exploiting the quadratic variance property to learn the causal ordering. We show through theoretical results and simulations that our algorithm is statistically consistent in the high-dimensional p>n setting provided that the degree of the moralized graph is bounded and performs well compared to state-of-the-art DAG-learning algorithms.
Identifiability Assumptions and Algorithm for Directed Graphical Models with Feedback
Jul 06, 2016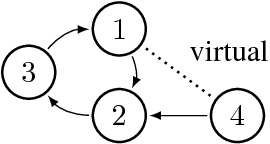
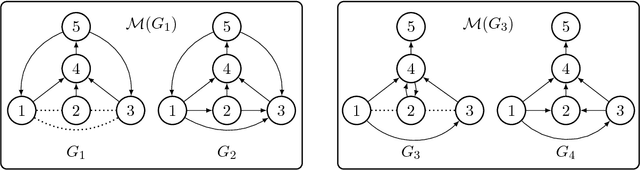
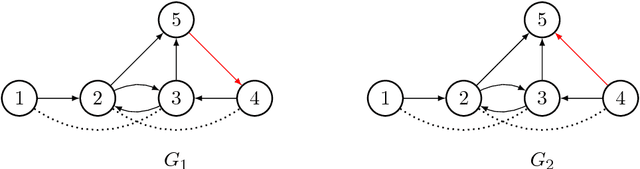
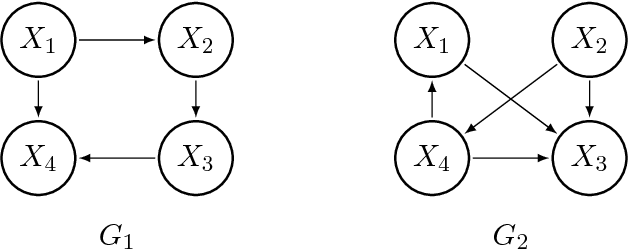
Directed graphical models provide a useful framework for modeling causal or directional relationships for multivariate data. Prior work has largely focused on identifiability and search algorithms for directed acyclic graphical (DAG) models. In many applications, feedback naturally arises and directed graphical models that permit cycles occur. In this paper we address the issue of identifiability for general directed cyclic graphical (DCG) models satisfying the Markov assumption. In particular, in addition to the faithfulness assumption which has already been introduced for cyclic models, we introduce two new identifiability assumptions, one based on selecting the model with the fewest edges and the other based on selecting the DCG model that entails the maximum number of d-separation rules. We provide theoretical results comparing these assumptions which show that: (1) selecting models with the largest number of d-separation rules is strictly weaker than the faithfulness assumption; (2) unlike for DAG models, selecting models with the fewest edges does not necessarily result in a milder assumption than the faithfulness assumption. We also provide connections between our two new principles and minimality assumptions. We use our identifiability assumptions to develop search algorithms for small-scale DCG models. Our simulation study supports our theoretical results, showing that the algorithms based on our two new principles generally out-perform algorithms based on the faithfulness assumption in terms of selecting the true skeleton for DCG models.