 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Perspective on Randomized Sketching for Ordinary Least-Squares
Paper and Code
Aug 25, 2015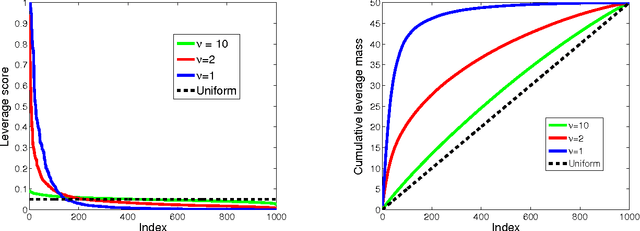
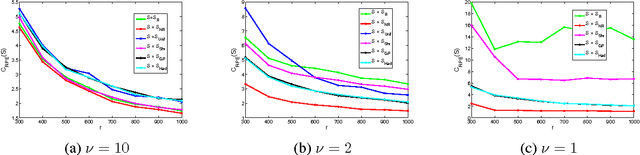
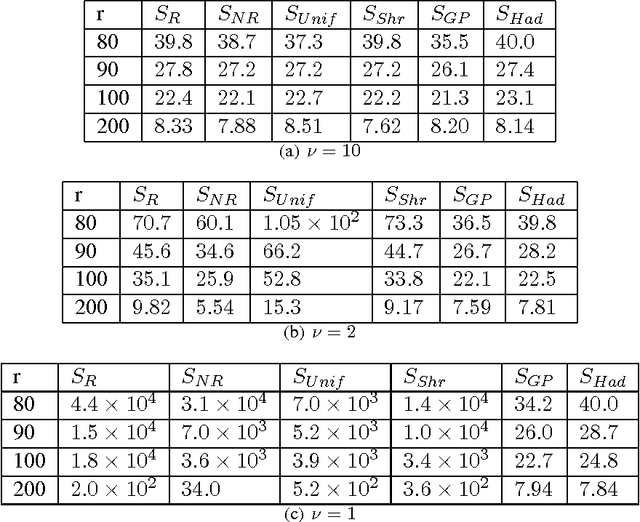
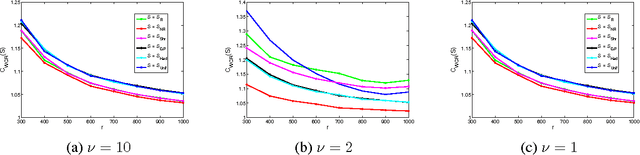
We consider statistical as well as algorithmic aspects of solving large-scale least-squares (LS) problems using randomized sketching algorithms. For a LS problem with input data $(X, Y) \in \mathbb{R}^{n \times p} \times \mathbb{R}^n$, sketching algorithms use a sketching matrix, $S\in\mathbb{R}^{r \times n}$ with $r \ll n$. Then, rather than solving the LS problem using the full data $(X,Y)$, sketching algorithms solve the LS problem using only the sketched data $(SX, SY)$. Prior work has typically adopted an algorithmic perspective, in that it has made no statistical assumptions on the input $X$ and $Y$, and instead it has been assumed that the data $(X,Y)$ are fixed and worst-case (WC). Prior results show that, when using sketching matrices such as random projections and leverage-score sampling algorithms, with $p < r \ll n$, the WC error is the same as solving the original problem, up to a small constant. From a statistical perspective, we typically consider the mean-squared error performance of randomized sketching algorithms, when data $(X, Y)$ are generated according to a statistical model $Y = X \beta + \epsilon$, where $\epsilon$ is a noise process. We provide a rigorous comparison of both perspectives leading to insights on how they differ. To do this, we first develop a framework for assessing algorithmic and statistical aspects of randomized sketching methods. We then consider the statistical prediction efficiency (PE) and the statistical residual efficiency (RE) of the sketched LS estimator; and we use our framework to provide upper bounds for several types of random projection and random sampling sketching algorithms. Among other results, we show that the RE can be upper bounded when $p < r \ll n$ while the PE typically requires the sample size $r$ to be substantially larger. Lower bounds developed in subsequent results show that our upper bounds on PE can not be improved.