 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SIGMORPHON 2020 Shared Task on Unsupervised Morphological Paradigm Completion
May 28, 2020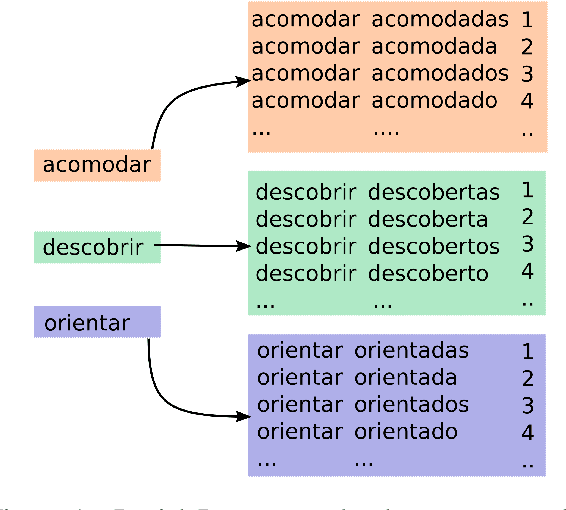
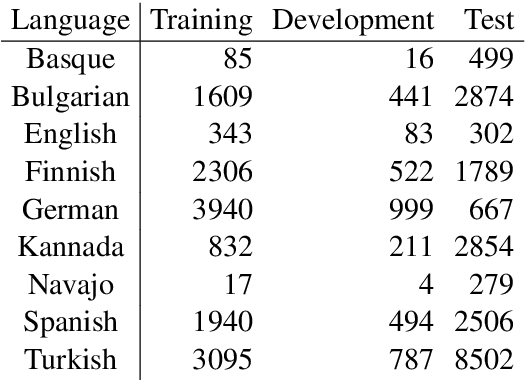
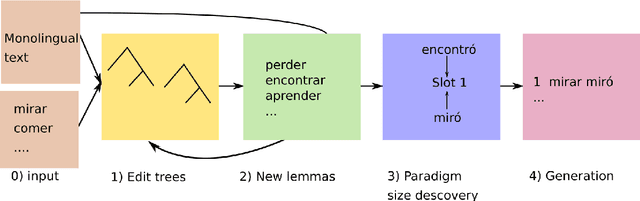
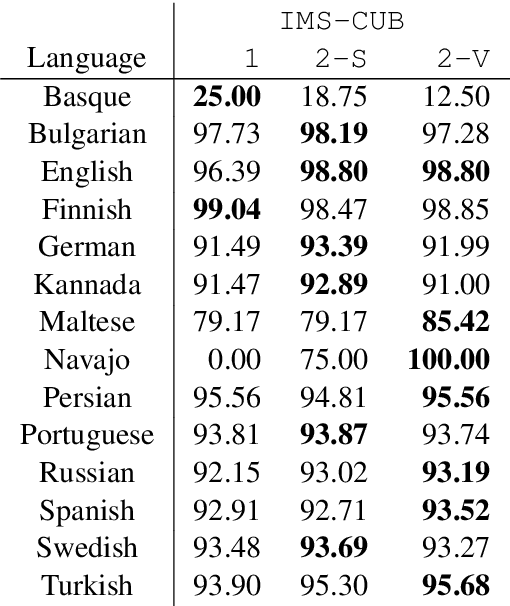
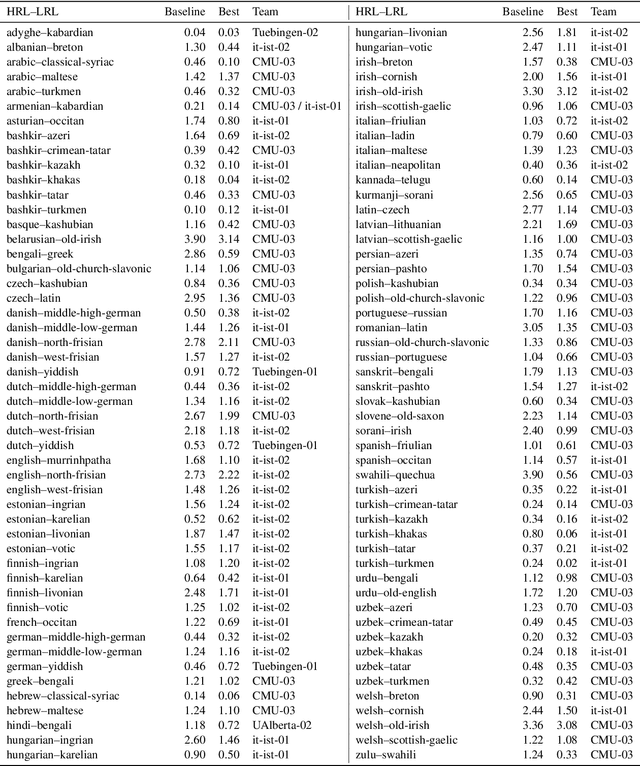
In this paper, we describe the findings of the SIGMORPHON 2020 shared task on unsupervised morphological paradigm completion (SIGMORPHON 2020 Task 2), a novel task in the field of inflectional morphology. Participants were asked to submit systems which take raw text and a list of lemmas as input, and output all inflected forms, i.e., the entire morphological paradigm, of each lemma. In order to simulate a realistic use case, we first released data for 5 development languages. However, systems were officially evaluated on 9 surprise languages, which were only revealed a few days before the submission deadline. We provided a modular baseline system, which is a pipeline of 4 components. 3 teams submitted a total of 7 systems, but, surprisingly, none of the submitted systems was able to improve over the baseline on average over all 9 test languages. Only on 3 languages did a submitted system obtain the best results. This shows that unsupervised morphological paradigm completion is still largely unsolved. We present an analysis here, so that this shared task will ground further research on the topic.
Cross-Linguistic Syntactic Evaluation of Word Prediction Models
May 21, 2020
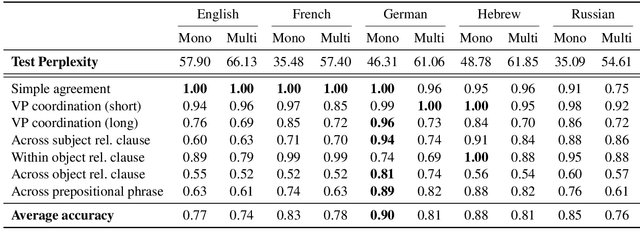
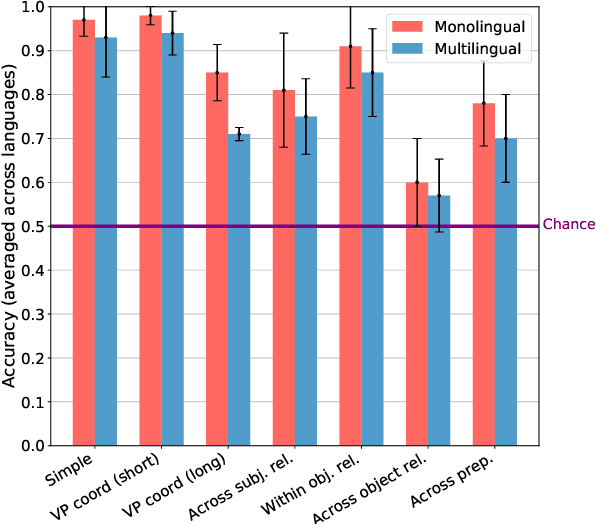
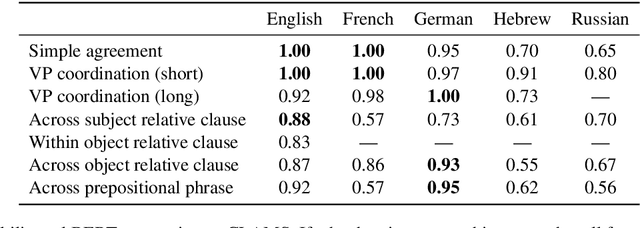
A range of studies have concluded that neural word prediction models can distinguish grammatical from ungrammatical sentences with high accuracy. However, these studies are based primarily on monolingual evidence from English. To investigate how these models' ability to learn syntax varies by language, we introduce CLAMS (Cross-Linguistic Assessment of Models on Syntax), a syntactic evaluation suite for monolingual and multilingual models. CLAMS includes subject-verb agreement challenge sets for English, French, German, Hebrew and Russian, generated from grammars we develop. We use CLAMS to evaluate LSTM language models as well as monolingual and multilingual BERT. Across languages, monolingual LSTMs achieved high accuracy on dependencies without attractors, and generally poor accuracy on agreement across object relative clauses. On other constructions, agreement accuracy was generally higher in languages with richer morphology. Multilingual models generally underperformed monolingual models. Multilingual BERT showed high syntactic accuracy on English, but noticeable deficiencies in other languages.
Induced Inflection-Set Keyword Search in Speech
Oct 27, 2019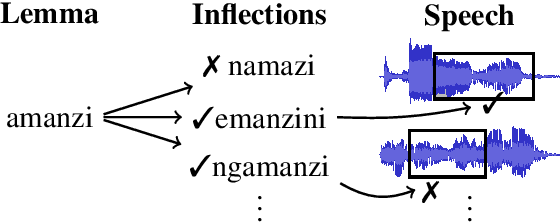
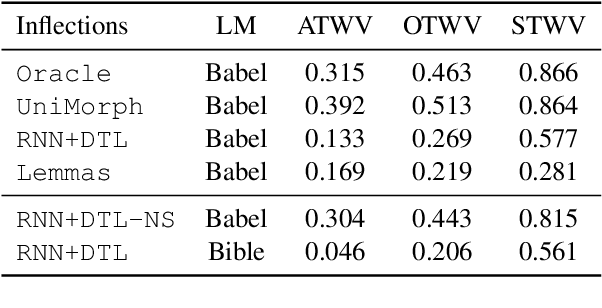
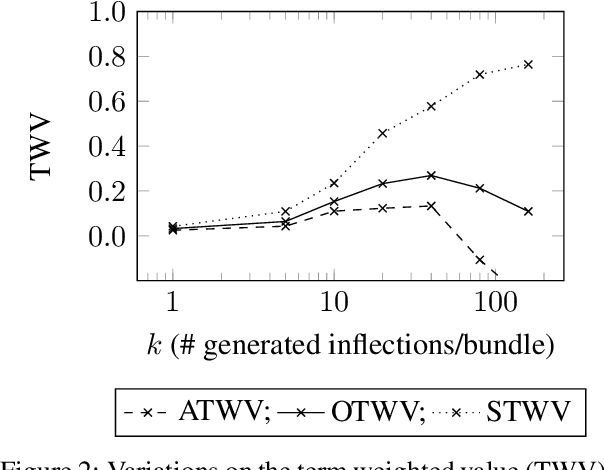
We investigate the problem of searching for a lexeme-set in speech by searching for its inflectional variants. Experimental results indicate how lexeme-set search performance changes with the number of hypothesized inflections, while ablation experiments highlight the relative importance of different components in the lexeme-set search pipeline. We provide a recipe and evaluation set for the community to use as an extrinsic measure of the performance of inflection generation approaches.
The SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
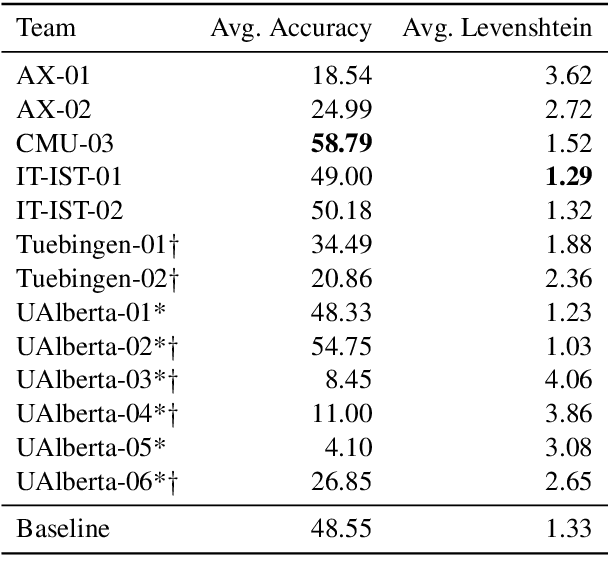
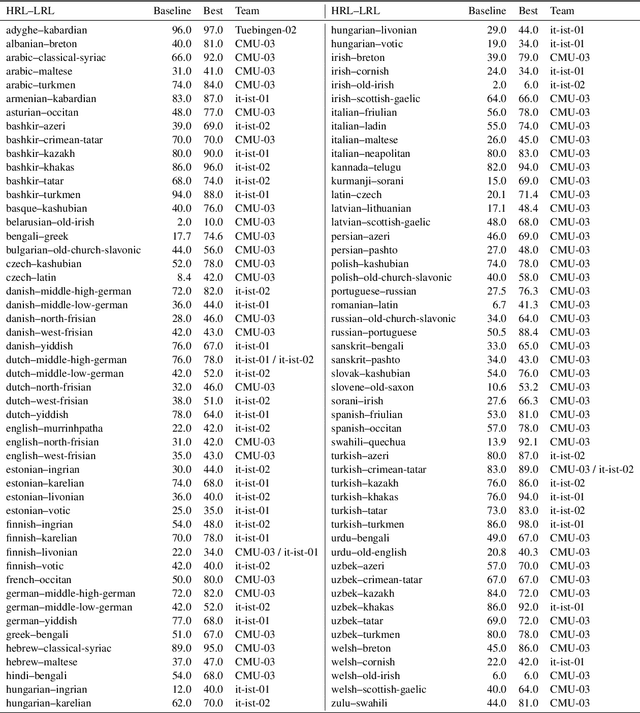
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
The CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Oct 18, 2018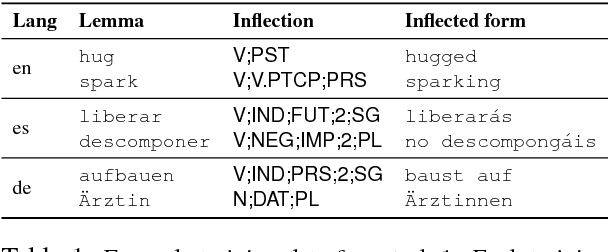
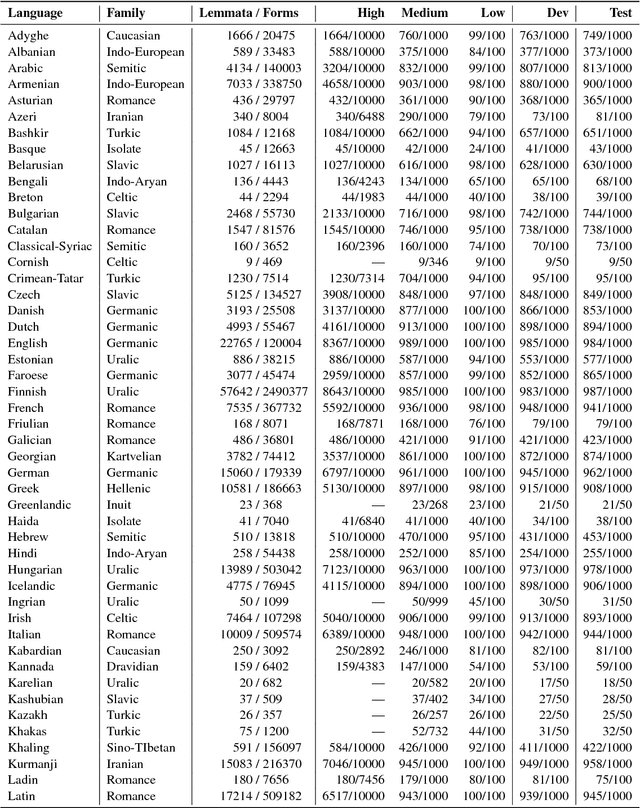
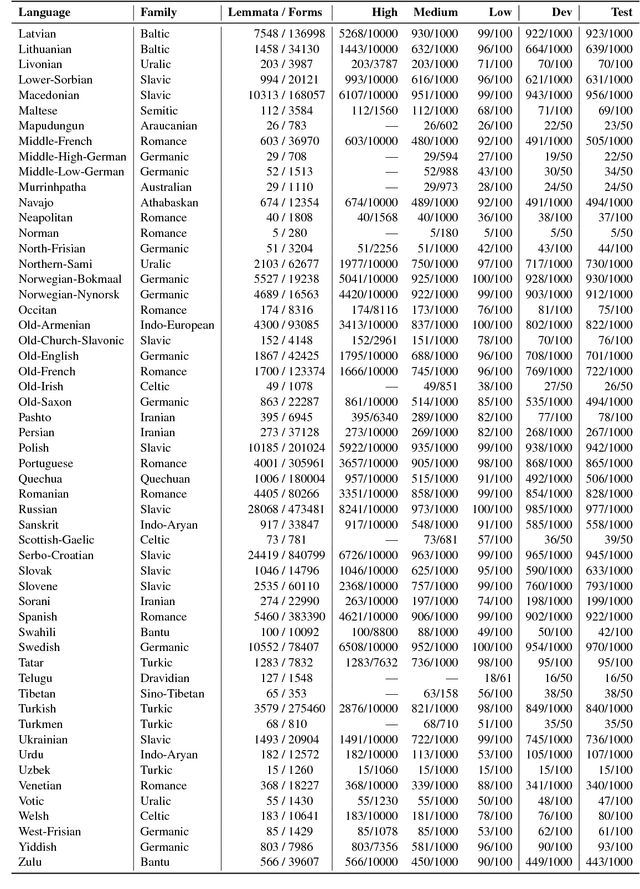

The CoNLL--SIGMORPHON 2018 shared task on supervised learning of morphological generation featured data sets from 103 typologically diverse languages. Apart from extending the number of languages involved in earlier supervised tasks of generating inflected forms, this year the shared task also featured a new second task which asked participants to inflect words in sentential context, similar to a cloze task. This second task featured seven languages. Task 1 received 27 submissions and task 2 received 6 submissions. Both tasks featured a low, medium, and high data condition. Nearly all submissions featured a neural component and built on highly-ranked systems from the earlier 2017 shared task. In the inflection task (task 1), 41 of the 52 languages present in last year's inflection task showed improvement by the best systems in the low-resource setting. The cloze task (task 2) proved to be difficult, and few submissions managed to consistently improve upon both a simple neural baseline system and a lemma-repeating baseline.
String Transduction with Target Language Models and Insertion Handling
Sep 19, 2018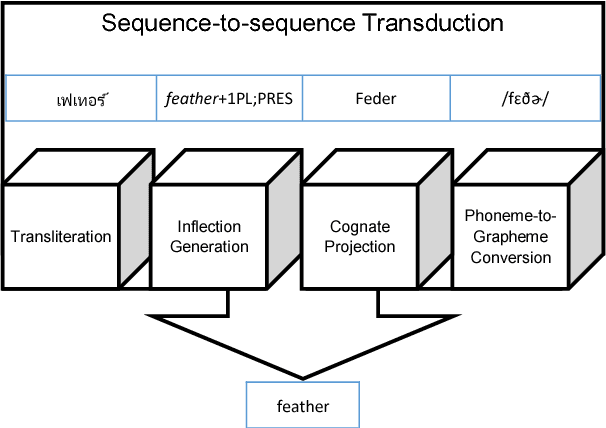
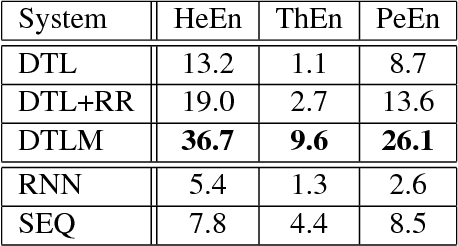
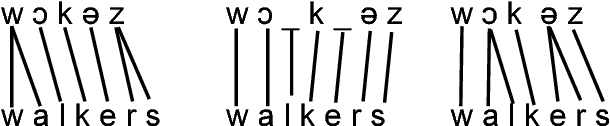
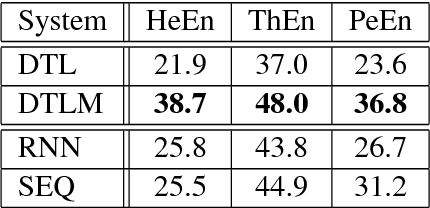
Many character-level tasks can be framed as sequence-to-sequence transduction, where the target is a word from a natural language. We show that leveraging target language models derived from unannotated target corpora, combined with a precise alignment of the training data, yields state-of-the art results on cognate projection, inflection generation, and phoneme-to-grapheme conversion.