 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaShare: Task and Instance Conditioned Parameter Sharing for Multi-Task Learning
May 26, 2023Multi-task networks rely on effective parameter sharing to achieve robust generalization across tasks. In this paper, we present a novel parameter sharing method for multi-task learning that conditions parameter sharing on both the task and the intermediate feature representations at inference time. In contrast to traditional parameter sharing approaches, which fix or learn a deterministic sharing pattern during training and apply the same pattern to all examples during inference, we propose to dynamically decide which parts of the network to activate based on both the task and the input instance. Our approach learns a hierarchical gating policy consisting of a task-specific policy for coarse layer selection and gating units for individual input instances, which work together to determine the execution path at inference time. Experiments on the NYU v2, Cityscapes and MIMIC-III datasets demonstrate the potential of the proposed approach and its applicability across problem domains.
Constant Memory Attentive Neural Processes
May 23, 2023



Neural Processes (NPs) are efficient methods for estimating predictive uncertainties. NPs comprise of a conditioning phase where a context dataset is encoded, a querying phase where the model makes predictions using the context dataset encoding, and an updating phase where the model updates its encoding with newly received datapoints. However, state-of-the-art methods require additional memory which scales linearly or quadratically with the size of the dataset, limiting their applications, particularly in low-resource settings. In this work, we propose Constant Memory Attentive Neural Processes (CMANPs), an NP variant which only requires constant memory for the conditioning, querying, and updating phases. In building CMANPs, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that can compute its output in constant memory and perform updates in constant computation. Empirically, we show CMANPs achieve state-of-the-art results on meta-regression and image completion tasks while being (1) significantly more memory efficient than prior methods and (2) more scalable to harder settings.
Ranking Regularization for Critical Rare Classes: Minimizing False Positives at a High True Positive Rate
Mar 31, 2023



In many real-world settings, the critical class is rare and a missed detection carries a disproportionately high cost. For example, tumors are rare and a false negative diagnosis could have severe consequences on treatment outcomes; fraudulent banking transactions are rare and an undetected occurrence could result in significant losses or legal penalties. In such contexts, systems are often operated at a high true positive rate, which may require tolerating high false positives. In this paper, we present a novel approach to address the challenge of minimizing false positives for systems that need to operate at a high true positive rate. We propose a ranking-based regularization (RankReg) approach that is easy to implement, and show empirically that it not only effectively reduces false positives, but also complements conventional imbalanced learning losses. With this novel technique in hand, we conduct a series of experiments on three broadly explored datasets (CIFAR-10&100 and Melanoma) and show that our approach lifts the previous state-of-the-art performance by notable margins.
Meta Temporal Point Processes
Jan 27, 2023



A temporal point process (TPP) is a stochastic process where its realization is a sequence of discrete events in time. Recent work in TPPs model the process using a neural network in a supervised learning framework, where a training set is a collection of all the sequences. In this work, we propose to train TPPs in a meta learning framework, where each sequence is treated as a different task, via a novel framing of TPPs as neural processes (NPs). We introduce context sets to model TPPs as an instantiation of NPs. Motivated by attentive NP, we also introduce local history matching to help learn more informative features. We demonstrate the potential of the proposed method on popular public benchmark datasets and tasks, and compare with state-of-the-art TPP methods.
Gumbel-Softmax Selective Networks
Nov 19, 2022


ML models often operate within the context of a larger system that can adapt its response when the ML model is uncertain, such as falling back on safe defaults or a human in the loop. This commonly encountered operational context calls for principled techniques for training ML models with the option to abstain from predicting when uncertain. Selective neural networks are trained with an integrated option to abstain, allowing them to learn to recognize and optimize for the subset of the data distribution for which confident predictions can be made. However, optimizing selective networks is challenging due to the non-differentiability of the binary selection function (the discrete decision of whether to predict or abstain). This paper presents a general method for training selective networks that leverages the Gumbel-softmax reparameterization trick to enable selection within an end-to-end differentiable training framework. Experiments on public datasets demonstrate the potential of Gumbel-softmax selective networks for selective regression and classification.
RankSim: Ranking Similarity Regularization for Deep Imbalanced Regression
May 30, 2022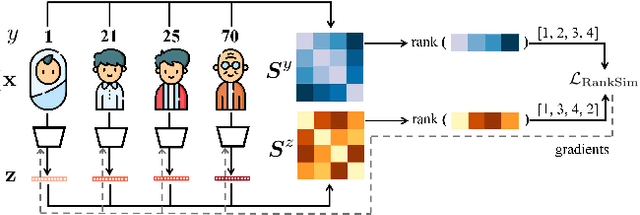
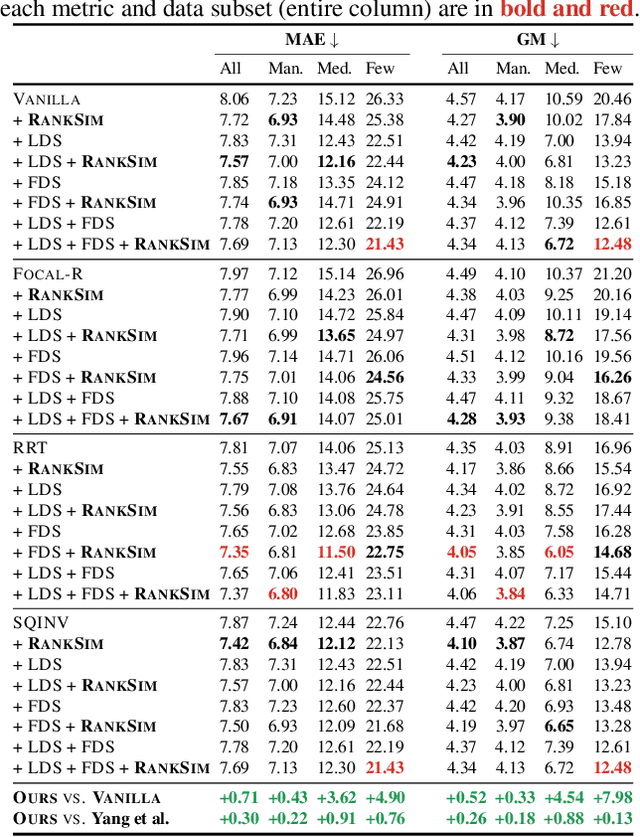
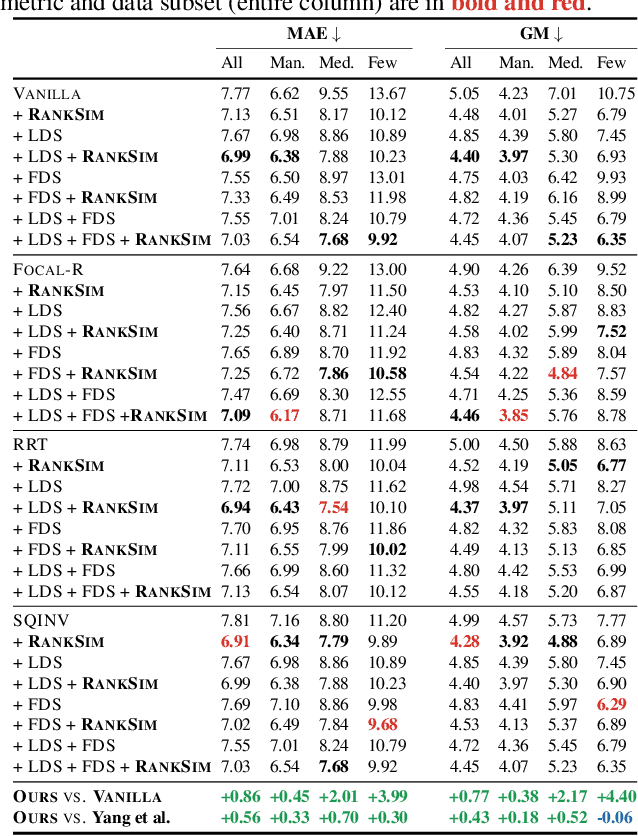

Data imbalance, in which a plurality of the data samples come from a small proportion of labels, poses a challenge in training deep neural networks. Unlike classification, in regression the labels are continuous, potentially boundless, and form a natural ordering. These distinct features of regression call for new techniques that leverage the additional information encoded in label-space relationships. This paper presents the RankSim (ranking similarity) regularizer for deep imbalanced regression, which encodes an inductive bias that samples that are closer in label space should also be closer in feature space. In contrast to recent distribution smoothing based approaches, RankSim captures both nearby and distant relationships: for a given data sample, RankSim encourages the sorted list of its neighbors in label space to match the sorted list of its neighbors in feature space. RankSim is complementary to conventional imbalanced learning techniques, including re-weighting, two-stage training, and distribution smoothing, and lifts the state-of-the-art performance on three imbalanced regression benchmarks: IMDB-WIKI-DIR, AgeDB-DIR, and STS-B-DIR.
Heterogeneous Multi-task Learning with Expert Diversity
Jun 20, 2021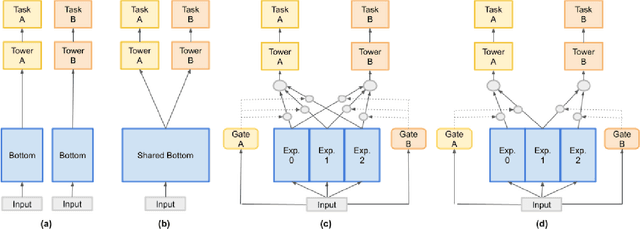
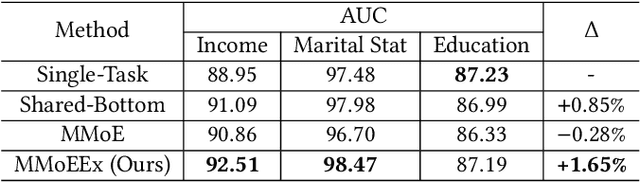
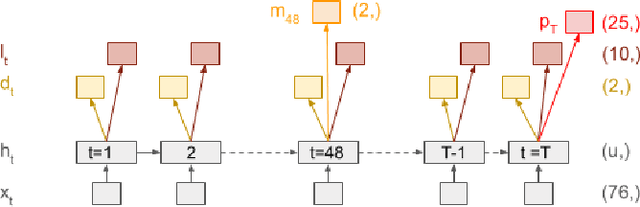
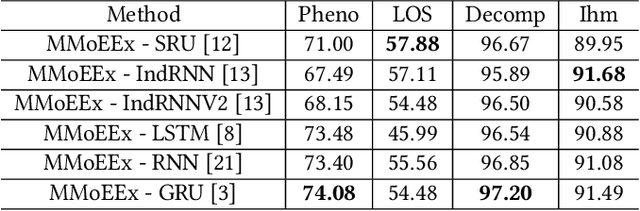
Predicting multiple heterogeneous biological and medical targets is a challenge for traditional deep learning models. In contrast to single-task learning, in which a separate model is trained for each target, multi-task learning (MTL) optimizes a single model to predict multiple related targets simultaneously. To address this challenge, we propose the Multi-gate Mixture-of-Experts with Exclusivity (MMoEEx). Our work aims to tackle the heterogeneous MTL setting, in which the same model optimizes multiple tasks with different characteristics. Such a scenario can overwhelm current MTL approaches due to the challenges in balancing shared and task-specific representations and the need to optimize tasks with competing optimization paths. Our method makes two key contributions: first, we introduce an approach to induce more diversity among experts, thus creating representations more suitable for highly imbalanced and heterogenous MTL learning; second, we adopt a two-step optimization [6, 11] approach to balancing the tasks at the gradient level. We validate our method on three MTL benchmark datasets, including Medical Information Mart for Intensive Care (MIMIC-III) and PubChem BioAssay (PCBA).
Piggyback GAN: Efficient Lifelong Learning for Image Conditioned Generation
Apr 24, 2021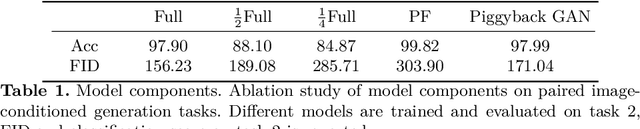
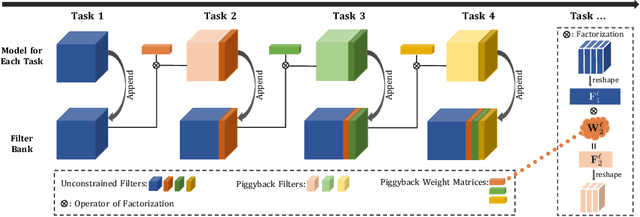
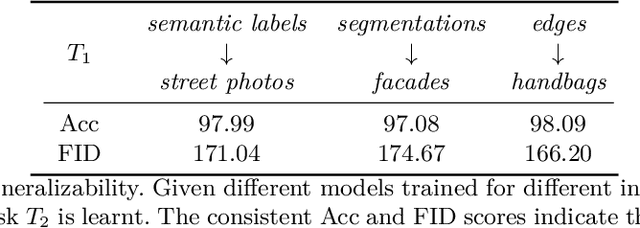
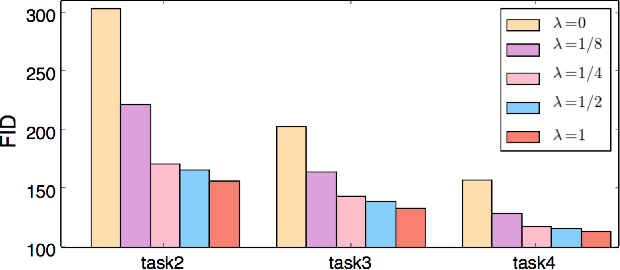
Humans accumulate knowledge in a lifelong fashion. Modern deep neural networks, on the other hand, are susceptible to catastrophic forgetting: when adapted to perform new tasks, they often fail to preserve their performance on previously learned tasks. Given a sequence of tasks, a naive approach addressing catastrophic forgetting is to train a separate standalone model for each task, which scales the total number of parameters drastically without efficiently utilizing previous models. In contrast, we propose a parameter efficient framework, Piggyback GAN, which learns the current task by building a set of convolutional and deconvolutional filters that are factorized into filters of the models trained on previous tasks. For the current task, our model achieves high generation quality on par with a standalone model at a lower number of parameters. For previous tasks, our model can also preserve generation quality since the filters for previous tasks are not altered. We validate Piggyback GAN on various image-conditioned generation tasks across different domains, and provide qualitative and quantitative results to show that the proposed approach can address catastrophic forgetting effectively and efficiently.
Learning Discriminative Prototypes with Dynamic Time Warping
Mar 17, 2021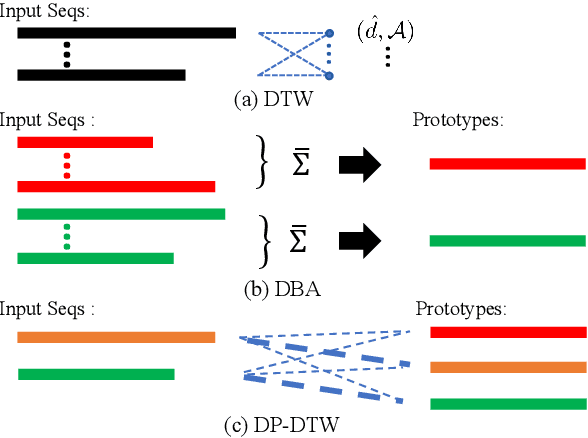

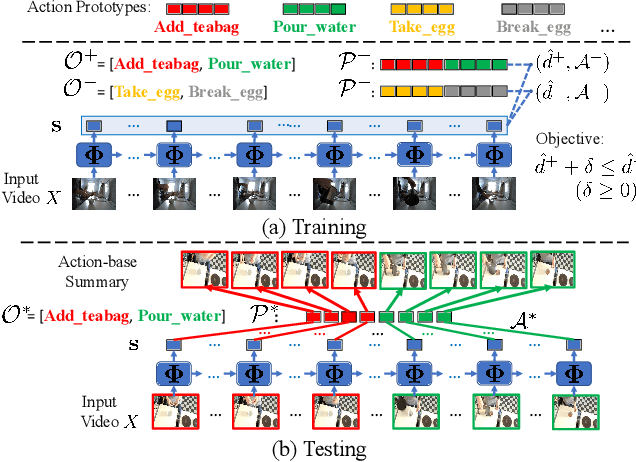
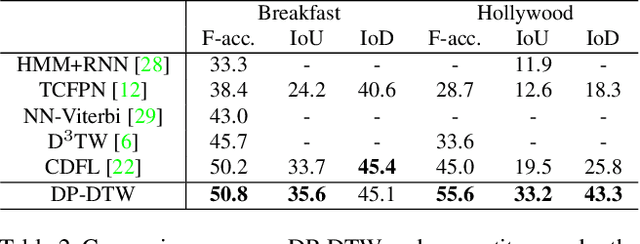
Dynamic Time Warping (DTW) is widely used for temporal data processing. However, existing methods can neither learn the discriminative prototypes of different classes nor exploit such prototypes for further analysis. We propose Discriminative Prototype DTW (DP-DTW), a novel method to learn class-specific discriminative prototypes for temporal recognition tasks. DP-DTW shows superior performance compared to conventional DTWs on time series classification benchmarks. Combined with end-to-end deep learning, DP-DTW can handle challenging weakly supervised action segmentation problems and achieves state of the art results on standard benchmarks. Moreover, detailed reasoning on the input video is enabled by the learned action prototypes. Specifically, an action-based video summarization can be obtained by aligning the input sequence with action prototypes.
Similarity-Preserving Knowledge Distillation
Aug 01, 2019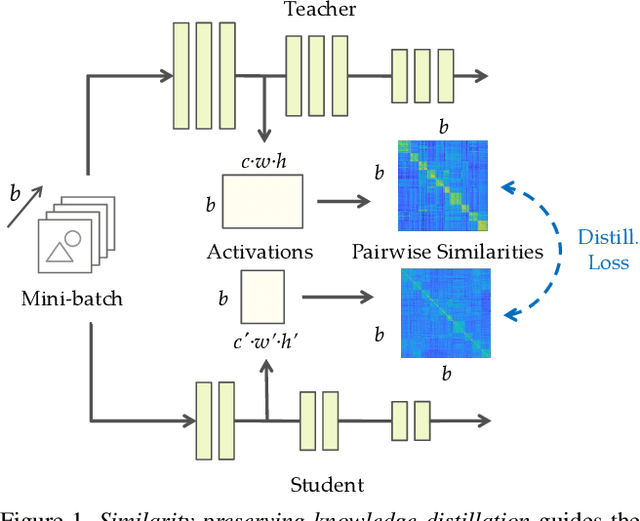
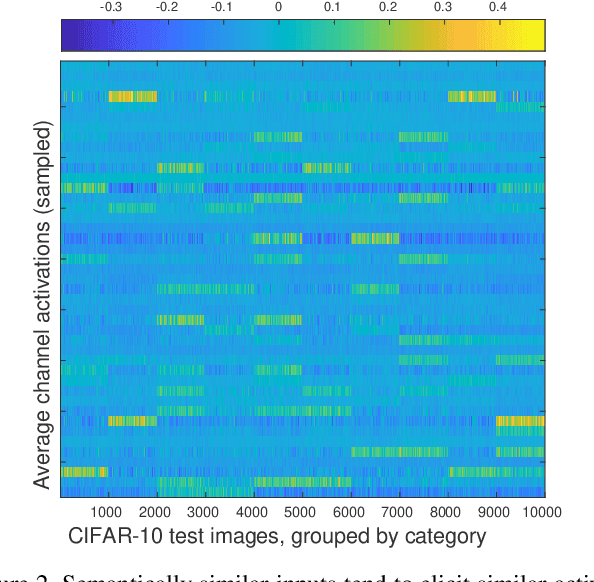

Knowledge distillation is a widely applicable technique for training a student neural network under the guidance of a trained teacher network. For example, in neural network compression, a high-capacity teacher is distilled to train a compact student; in privileged learning, a teacher trained with privileged data is distilled to train a student without access to that data. The distillation loss determines how a teacher's knowledge is captured and transferred to the student. In this paper, we propose a new form of knowledge distillation loss that is inspired by the observation that semantically similar inputs tend to elicit similar activation patterns in a trained network. Similarity-preserving knowledge distillation guides the training of a student network such that input pairs that produce similar (dissimilar) activations in the teacher network produce similar (dissimilar) activations in the student network. In contrast to previous distillation methods, the student is not required to mimic the representation space of the teacher, but rather to preserve the pairwise similarities in its own representation space. Experiments on three public datasets demonstrate the potential of our approach.