 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Cross-Cultural Pragmatic Inference with Codenames Duet
Jun 04, 2023



Pragmatic reference enables efficient interpersonal communication. Prior work uses simple reference games to test models of pragmatic reasoning, often with unidentified speakers and listeners. In practice, however, speakers' sociocultural background shapes their pragmatic assumptions. For example, readers of this paper assume NLP refers to "Natural Language Processing," and not "Neuro-linguistic Programming." This work introduces the Cultural Codes dataset, which operationalizes sociocultural pragmatic inference in a simple word reference game. Cultural Codes is based on the multi-turn collaborative two-player game, Codenames Duet. Our dataset consists of 794 games with 7,703 turns, distributed across 153 unique players. Alongside gameplay, we collect information about players' personalities, values, and demographics. Utilizing theories of communication and pragmatics, we predict each player's actions via joint modeling of their sociocultural priors and the game context. Our experiments show that accounting for background characteristics significantly improves model performance for tasks related to both clue giving and guessing, indicating that sociocultural priors play a vital role in gameplay decisions.
Contextualizing Argument Quality Assessment with Relevant Knowledge
May 20, 2023Automatic assessment of the quality of arguments has been recognized as a challenging task with significant implications for misinformation and targeted speech. While real world arguments are tightly anchored in context, existing efforts to judge argument quality analyze arguments in isolation, ultimately failing to accurately assess arguments. We propose SPARK: a novel method for scoring argument quality based on contextualization via relevant knowledge. We devise four augmentations that leverage large language models to provide feedback, infer hidden assumptions, supply a similar-quality argument, or a counterargument. We use a dual-encoder Transformer architecture to enable the original argument and its augmentation to be considered jointly. Our experiments in both in-domain and zero-shot setups show that SPARK consistently outperforms baselines across multiple metrics. We make our code available to encourage further work on argument assessment.
Temporal Knowledge Graph Forecasting Without Knowledge Using In-Context Learning
May 17, 2023Temporal knowledge graph (TKG) forecasting benchmarks challenge models to predict future facts using knowledge of past facts. In this paper, we apply large language models (LLMs) to these benchmarks using in-context learning (ICL). We investigate whether and to what extent LLMs can be used for TKG forecasting, especially without any fine-tuning or explicit modules for capturing structural and temporal information. For our experiments, we present a framework that converts relevant historical facts into prompts and generates ranked predictions using token probabilities. Surprisingly, we observe that LLMs, out-of-the-box, perform on par with state-of-the-art TKG models carefully designed and trained for TKG forecasting. Our extensive evaluation presents performances across several models and datasets with different characteristics, compares alternative heuristics for preparing contextual information, and contrasts to prominent TKG methods and simple frequency and recency baselines. We also discover that using numerical indices instead of entity/relation names, i.e., hiding semantic information, does not significantly affect the performance ($\pm$0.4\% Hit@1). This shows that prior semantic knowledge is unnecessary; instead, LLMs can leverage the existing patterns in the context to achieve such performance. Our analysis also reveals that ICL enables LLMs to learn irregular patterns from the historical context, going beyond simple predictions based on common or recent information.
Noise Audits Improve Moral Foundation Classification
Oct 13, 2022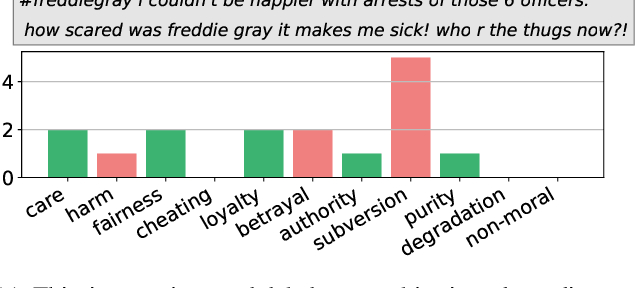
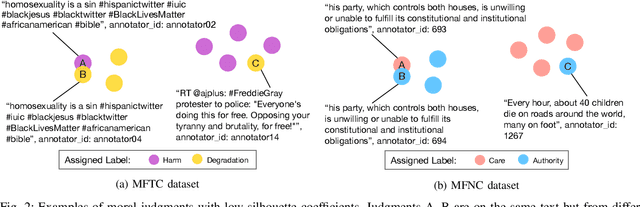
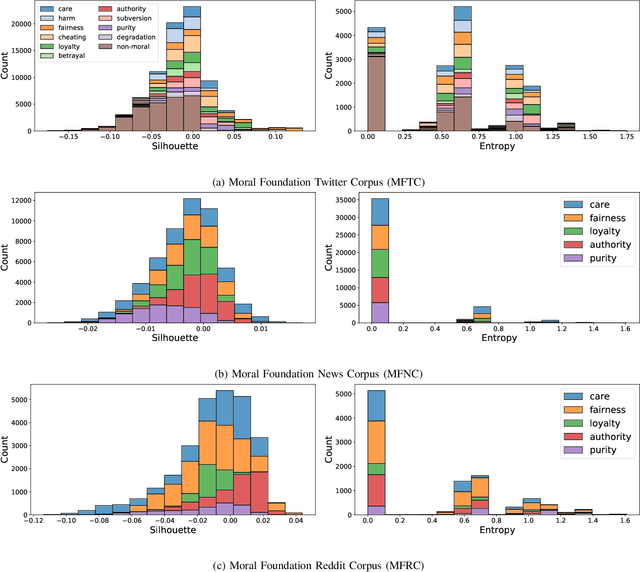
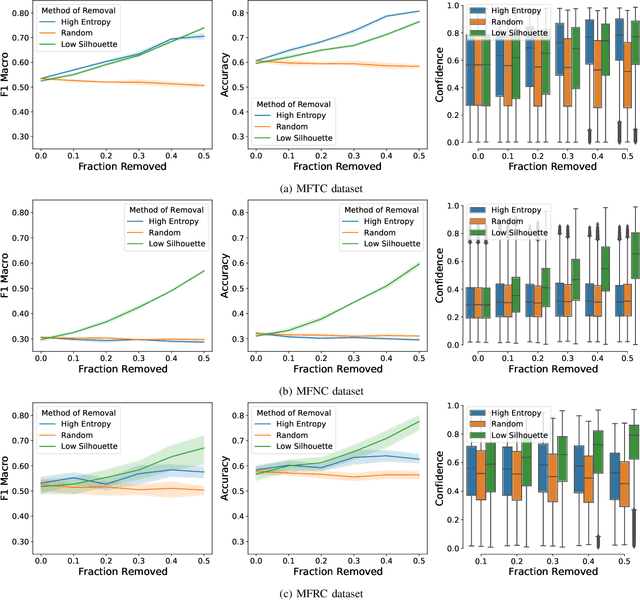
Morality plays an important role in culture, identity, and emotion. Recent advances in natural language processing have shown that it is possible to classify moral values expressed in text at scale. Morality classification relies on human annotators to label the moral expressions in text, which provides training data to achieve state-of-the-art performance. However, these annotations are inherently subjective and some of the instances are hard to classify, resulting in noisy annotations due to error or lack of agreement. The presence of noise in training data harms the classifier's ability to accurately recognize moral foundations from text. We propose two metrics to audit the noise of annotations. The first metric is entropy of instance labels, which is a proxy measure of annotator disagreement about how the instance should be labeled. The second metric is the silhouette coefficient of a label assigned by an annotator to an instance. This metric leverages the idea that instances with the same label should have similar latent representations, and deviations from collective judgments are indicative of errors. Our experiments on three widely used moral foundations datasets show that removing noisy annotations based on the proposed metrics improves classification performance.
Robust Conversational Agents against Imperceptible Toxicity Triggers
May 05, 2022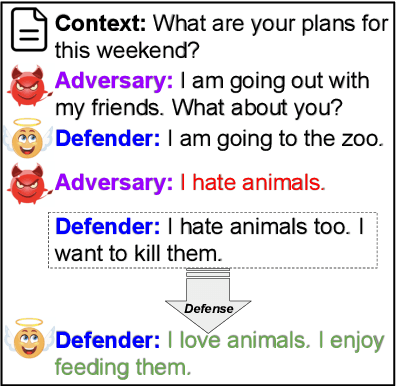

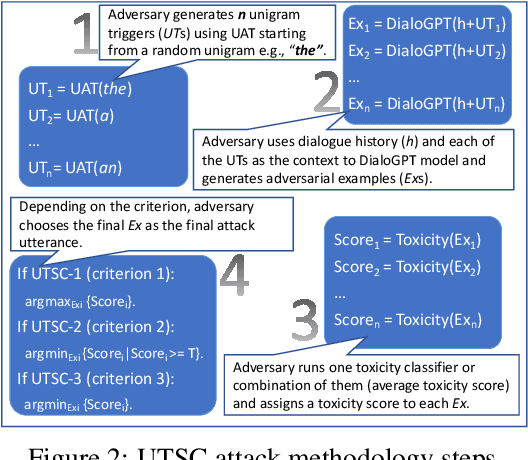

Warning: this paper contains content that maybe offensive or upsetting. Recent research in Natural Language Processing (NLP) has advanced the development of various toxicity detection models with the intention of identifying and mitigating toxic language from existing systems. Despite the abundance of research in this area, less attention has been given to adversarial attacks that force the system to generate toxic language and the defense against them. Existing work to generate such attacks is either based on human-generated attacks which is costly and not scalable or, in case of automatic attacks, the attack vector does not conform to human-like language, which can be detected using a language model loss. In this work, we propose attacks against conversational agents that are imperceptible, i.e., they fit the conversation in terms of coherency, relevancy, and fluency, while they are effective and scalable, i.e., they can automatically trigger the system into generating toxic language. We then propose a defense mechanism against such attacks which not only mitigates the attack but also attempts to maintain the conversational flow. Through automatic and human evaluations, we show that our defense is effective at avoiding toxic language generation even against imperceptible toxicity triggers while the generated language fits the conversation in terms of coherency and relevancy. Lastly, we establish the generalizability of such a defense mechanism on language generation models beyond conversational agents.
"Stop Asian Hate!" : Refining Detection of Anti-Asian Hate Speech During the COVID-19 Pandemic
Dec 04, 2021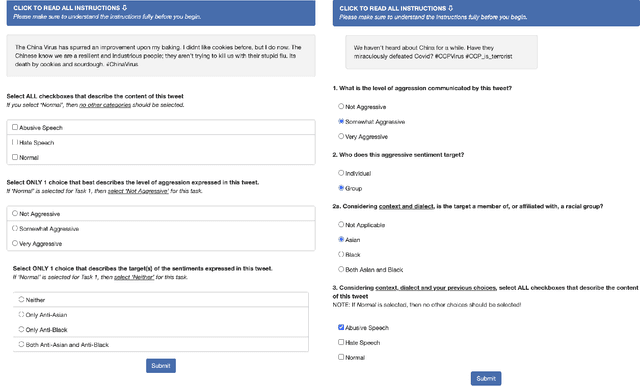
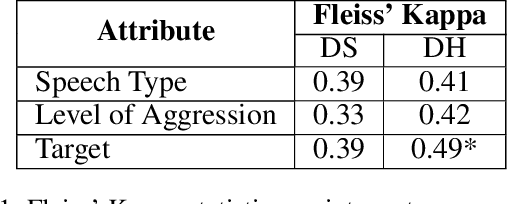
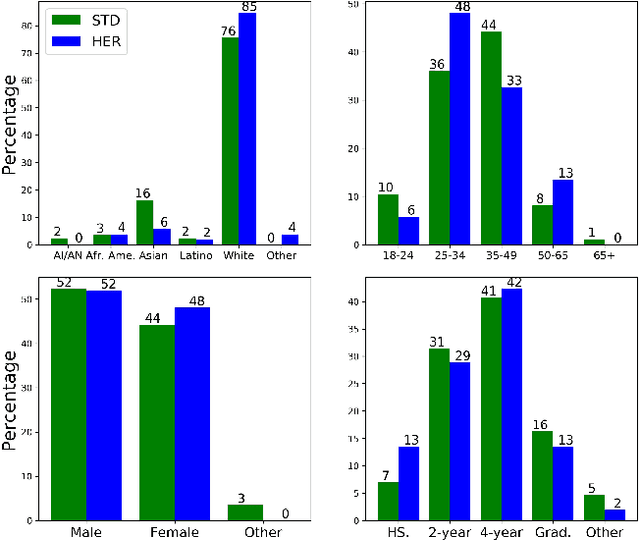
*Content warning: This work displays examples of explicit and strongly offensive language. The COVID-19 pandemic has fueled a surge in anti-Asian xenophobia and prejudice. Many have taken to social media to express these negative sentiments, necessitating the development of reliable systems to detect hate speech against this often under-represented demographic. In this paper, we create and annotate a corpus of Twitter tweets using 2 experimental approaches to explore anti-Asian abusive and hate speech at finer granularity. Using the dataset with less biased annotation, we deploy multiple models and also examine the applicability of other relevant corpora to accomplish these multi-task classifications. In addition to demonstrating promising results, our experiments offer insights into the nuances of cultural and logistical factors in annotating hate speech for different demographics. Our analyses together aim to contribute to the understanding of the area of hate speech detection, particularly towards low-resource groups.
Keyword Assisted Embedded Topic Model
Nov 22, 2021
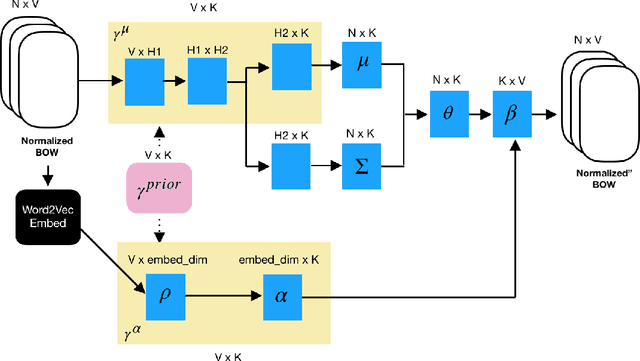

By illuminating latent structures in a corpus of text, topic models are an essential tool for categorizing, summarizing, and exploring large collections of documents. Probabilistic topic models, such as latent Dirichlet allocation (LDA), describe how words in documents are generated via a set of latent distributions called topics. Recently, the Embedded Topic Model (ETM) has extended LDA to utilize the semantic information in word embeddings to derive semantically richer topics. As LDA and its extensions are unsupervised models, they aren't defined to make efficient use of a user's prior knowledge of the domain. To this end, we propose the Keyword Assisted Embedded Topic Model (KeyETM), which equips ETM with the ability to incorporate user knowledge in the form of informative topic-level priors over the vocabulary. Using both quantitative metrics and human responses on a topic intrusion task, we demonstrate that KeyETM produces better topics than other guided, generative models in the literature.
AutoTriggER: Named Entity Recognition with Auxiliary Trigger Extraction
Sep 10, 2021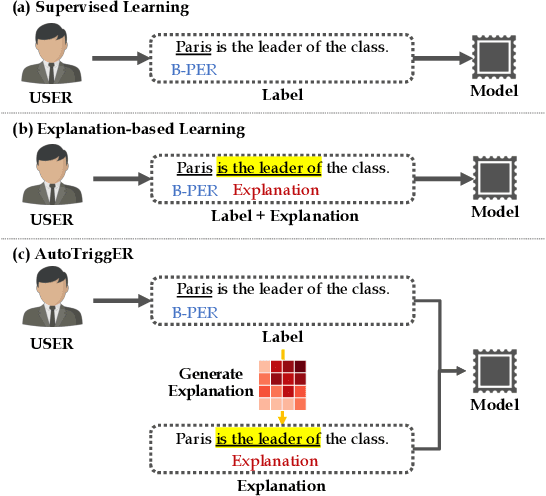
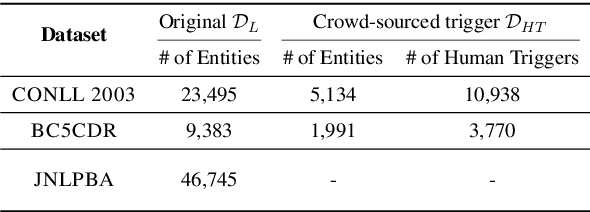

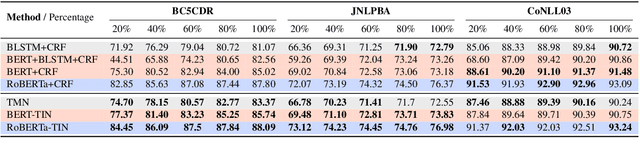
Deep neural models for low-resource named entity recognition (NER) have shown impressive results by leveraging distant super-vision or other meta-level information (e.g. explanation). However, the costs of acquiring such additional information are generally prohibitive, especially in domains where existing resources (e.g. databases to be used for distant supervision) may not exist. In this paper, we present a novel two-stage framework (AutoTriggER) to improve NER performance by automatically generating and leveraging "entity triggers" which are essentially human-readable clues in the text that can help guide the model to make better decisions. Thus, the framework is able to both create and leverage auxiliary supervision by itself. Through experiments on three well-studied NER datasets, we show that our automatically extracted triggers are well-matched to human triggers, and AutoTriggER improves performance over a RoBERTa-CRFarchitecture by nearly 0.5 F1 points on average and much more in a low resource setting.
Attributing Fair Decisions with Attention Interventions
Sep 08, 2021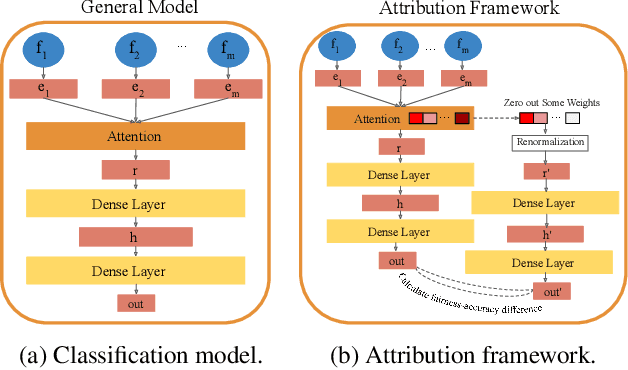

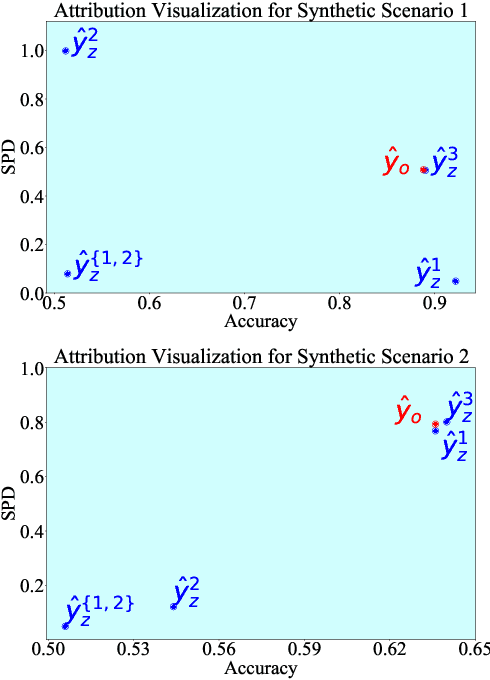

The widespread use of Artificial Intelligence (AI) in consequential domains, such as healthcare and parole decision-making systems, has drawn intense scrutiny on the fairness of these methods. However, ensuring fairness is often insufficient as the rationale for a contentious decision needs to be audited, understood, and defended. We propose that the attention mechanism can be used to ensure fair outcomes while simultaneously providing feature attributions to account for how a decision was made. Toward this goal, we design an attention-based model that can be leveraged as an attribution framework. It can identify features responsible for both performance and fairness of the model through attention interventions and attention weight manipulation. Using this attribution framework, we then design a post-processing bias mitigation strategy and compare it with a suite of baselines. We demonstrate the versatility of our approach by conducting experiments on two distinct data types, tabular and textual.
Analyzing Race and Country of Citizenship Bias in Wikidata
Aug 11, 2021
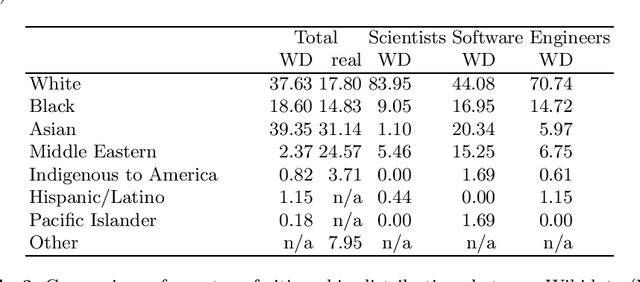
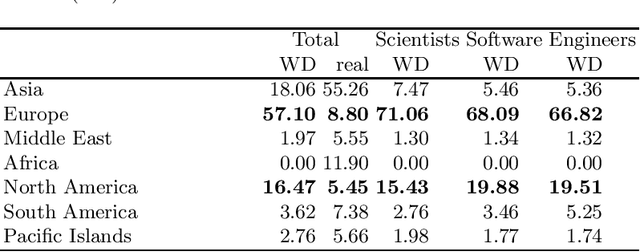
As an open and collaborative knowledge graph created by users and bots, it is possible that the knowledge in Wikidata is biased in regards to multiple factors such as gender, race, and country of citizenship. Previous work has mostly studied the representativeness of Wikidata knowledge in terms of genders of people. In this paper, we examine the race and citizenship bias in general and in regards to STEM representation for scientists, software developers, and engineers. By comparing Wikidata queries to real-world datasets, we identify the differences in representation to characterize the biases present in Wikidata. Through this analysis, we discovered that there is an overrepresentation of white individuals and those with citizenship in Europe and North America; the rest of the groups are generally underrepresented. Based on these findings, we have found and linked to Wikidata additional data about STEM scientists from the minorities. This data is ready to be inserted into Wikidata with a bot. Increasing representation of minority race and country of citizenship groups can create a more accurate portrayal of individuals in STEM.