 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
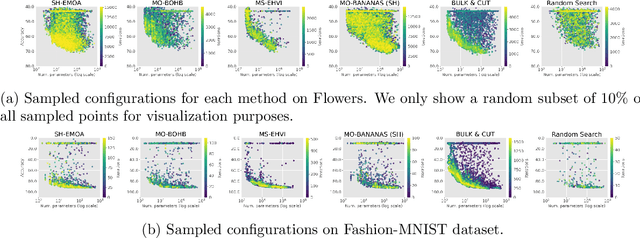
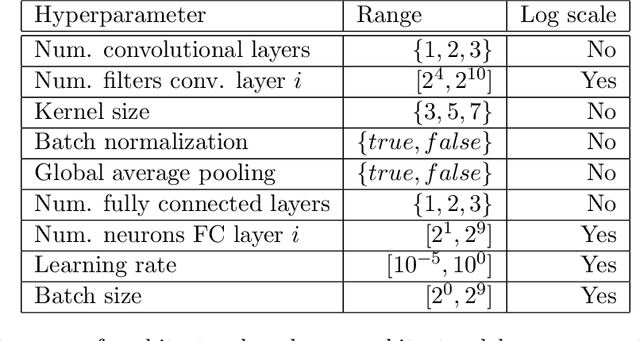
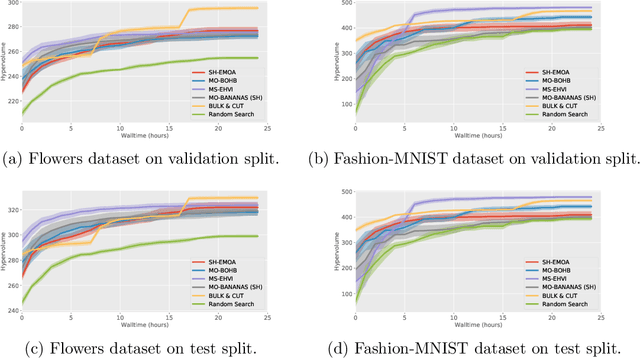
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.
How Powerful are Performance Predictors in Neural Architecture Search?
Apr 02, 2021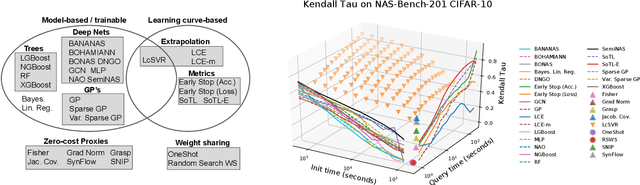
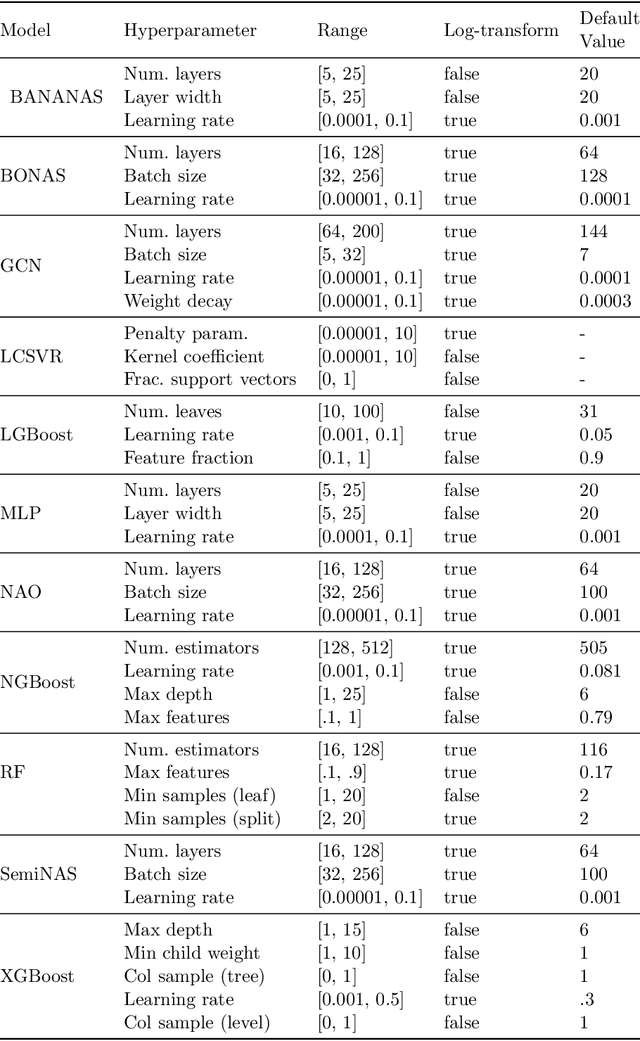
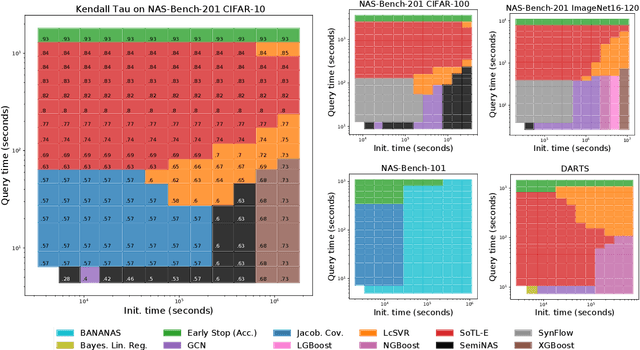
Early methods in the rapidly developing field of neural architecture search (NAS) required fully training thousands of neural networks. To reduce this extreme computational cost, dozens of techniques have since been proposed to predict the final performance of neural architectures. Despite the success of such performance prediction methods, it is not well-understood how different families of techniques compare to one another, due to the lack of an agreed-upon evaluation metric and optimization for different constraints on the initialization time and query time. In this work, we give the first large-scale study of performance predictors by analyzing 31 techniques ranging from learning curve extrapolation, to weight-sharing, to supervised learning, to "zero-cost" proxies. We test a number of correlation- and rank-based performance measures in a variety of settings, as well as the ability of each technique to speed up predictor-based NAS frameworks. Our results act as recommendations for the best predictors to use in different settings, and we show that certain families of predictors can be combined to achieve even better predictive power, opening up promising research directions. Our code, featuring a library of 31 performance predictors, is available at https://github.com/automl/naslib.
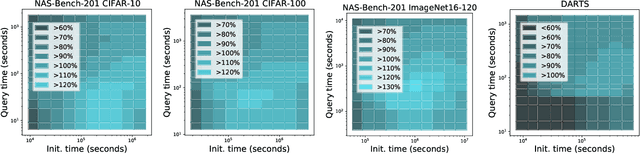
TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation
Mar 18, 2021
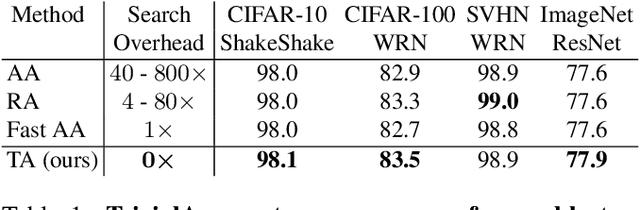
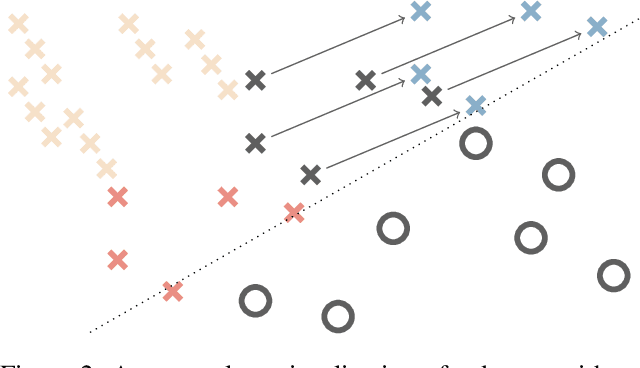
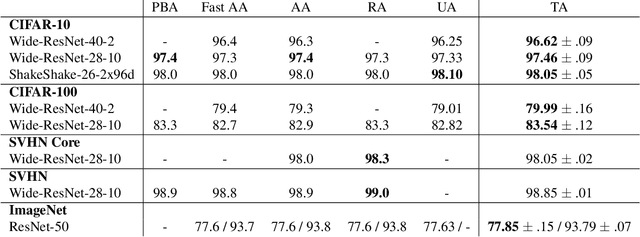
Automatic augmentation methods have recently become a crucial pillar for strong model performance in vision tasks. Current methods are mostly a trade-off between being simple, in-expensive or well-performing. We present a most simple automatic augmentation baseline, TrivialAugment, that outperforms previous methods almost for free. It is parameter-free and only applies a single augmentation to each image. To us, TrivialAugment's effectiveness is very unexpected. Thus, we performed very thorough experiments on its performance. First, we compare TrivialAugment to previous state-of-the-art methods in a plethora of scenarios. Then, we perform multiple ablation studies with different augmentation spaces, augmentation methods and setups to understand the crucial requirements for its performance. We condensate our learnings into recommendations to automatic augmentation users. Additionally, we provide a simple interface to use multiple automatic augmentation methods in any codebase, as well as, our full code base for reproducibility. Since our work reveals a stagnation in many parts of automatic augmentation research, we end with a short proposal of best practices for sustained future progress in automatic augmentation methods.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
Feb 26, 2021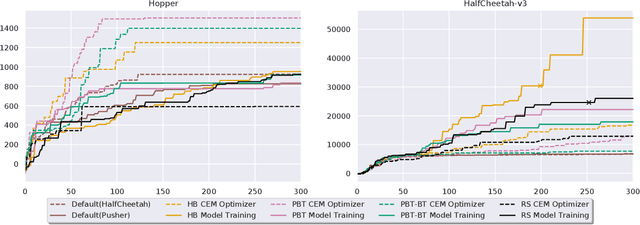
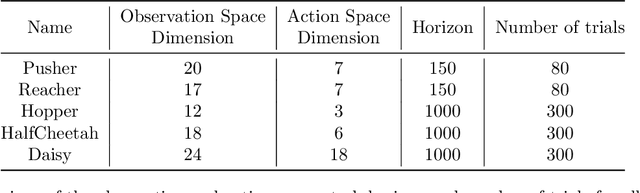
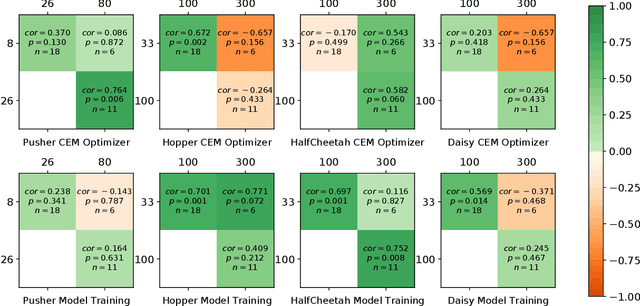
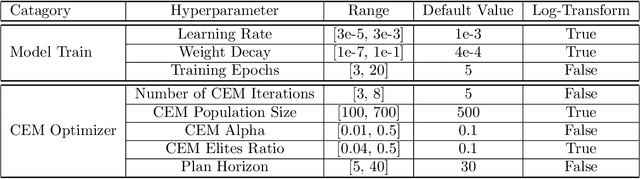
Model-based Reinforcement Learning (MBRL) is a promising framework for learning control in a data-efficient manner. MBRL algorithms can be fairly complex due to the separate dynamics modeling and the subsequent planning algorithm, and as a result, they often possess tens of hyperparameters and architectural choices. For this reason, MBRL typically requires significant human expertise before it can be applied to new problems and domains. To alleviate this problem, we propose to use automatic hyperparameter optimization (HPO). We demonstrate that this problem can be tackled effectively with automated HPO, which we demonstrate to yield significantly improved performance compared to human experts. In addition, we show that tuning of several MBRL hyperparameters dynamically, i.e. during the training itself, further improves the performance compared to using static hyperparameters which are kept fixed for the whole training. Finally, our experiments provide valuable insights into the effects of several hyperparameters, such as plan horizon or learning rate and their influence on the stability of training and resulting rewards.
Learning Synthetic Environments for Reinforcement Learning with Evolution Strategies
Feb 08, 2021
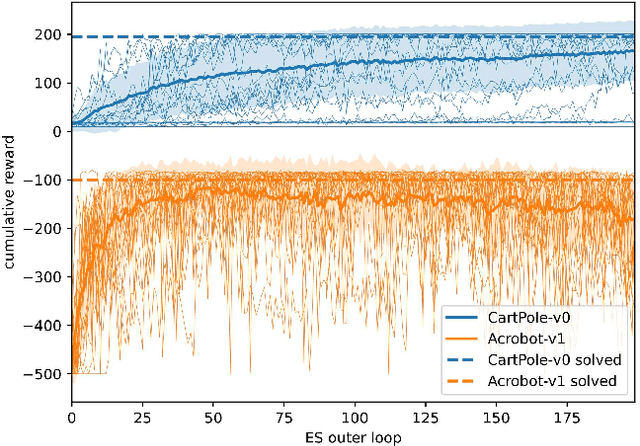
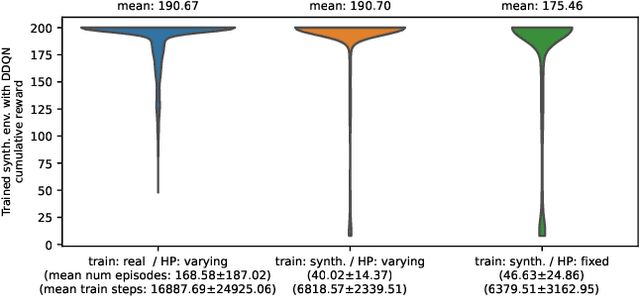
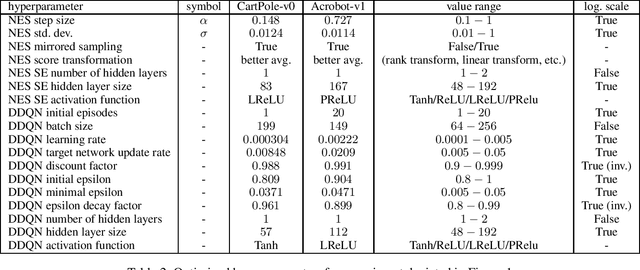
This work explores learning agent-agnostic synthetic environments (SEs) for Reinforcement Learning. SEs act as a proxy for target environments and allow agents to be trained more efficiently than when directly trained on the target environment. We formulate this as a bi-level optimization problem and represent an SE as a neural network. By using Natural Evolution Strategies and a population of SE parameter vectors, we train agents in the inner loop on evolving SEs while in the outer loop we use the performance on the target task as a score for meta-updating the SE population. We show empirically that our method is capable of learning SEs for two discrete-action-space tasks (CartPole-v0 and Acrobot-v1) that allow us to train agents more robustly and with up to 60% fewer steps. Not only do we show in experiments with 4000 evaluations that the SEs are robust against hyperparameter changes such as the learning rate, batch sizes and network sizes, we also show that SEs trained with DDQN agents transfer in limited ways to a discrete-action-space version of TD3 and very well to Dueling DDQN.
In-Loop Meta-Learning with Gradient-Alignment Reward
Feb 05, 2021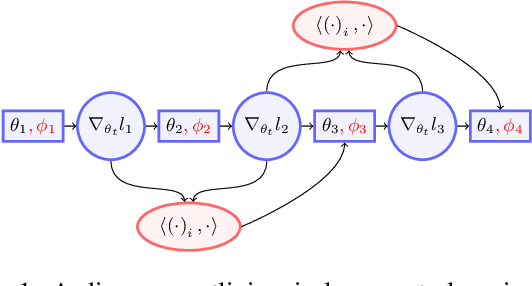
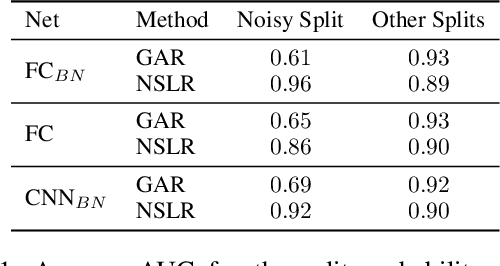
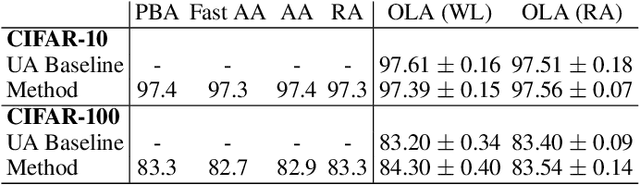

At the heart of the standard deep learning training loop is a greedy gradient step minimizing a given loss. We propose to add a second step to maximize training generalization. To do this, we optimize the loss of the next training step. While computing the gradient for this generally is very expensive and many interesting applications consider non-differentiable parameters (e.g. due to hard samples), we present a cheap-to-compute and memory-saving reward, the gradient-alignment reward (GAR), that can guide the optimization. We use this reward to optimize multiple distributions during model training. First, we present the application of GAR to choosing the data distribution as a mixture of multiple dataset splits in a small scale setting. Second, we show that it can successfully guide learning augmentation strategies competitive with state-of-the-art augmentation strategies on CIFAR-10 and CIFAR-100.
Squirrel: A Switching Hyperparameter Optimizer
Dec 16, 2020In this short note, we describe our submission to the NeurIPS 2020 BBO challenge. Motivated by the fact that different optimizers work well on different problems, our approach switches between different optimizers. Since the team names on the competition's leaderboard were randomly generated "alliteration nicknames", consisting of an adjective and an animal with the same initial letter, we called our approach the Switching Squirrel, or here, short, Squirrel.
Differential Evolution for Neural Architecture Search
Dec 11, 2020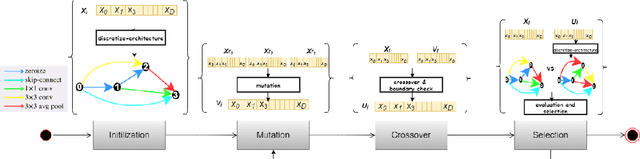
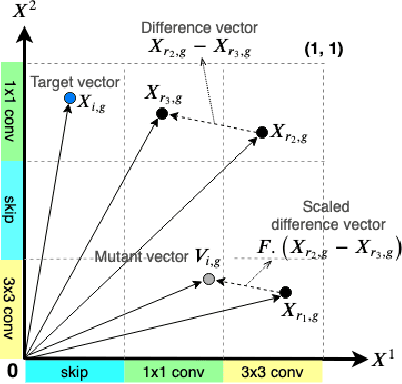
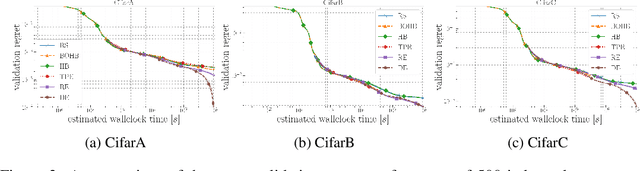
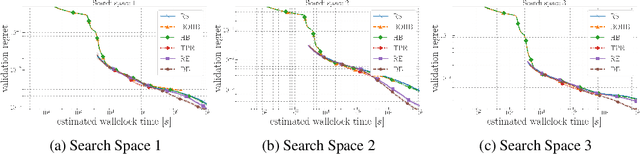
Neural architecture search (NAS) methods rely on a search strategy for deciding which architectures to evaluate next and a performance estimation strategy for assessing their performance (e.g., using full evaluations, multi-fidelity evaluations, or the one-shot model). In this paper, we focus on the search strategy. We introduce the simple yet powerful evolutionary algorithm of differential evolution to the NAS community. Using the simplest performance evaluation strategy of full evaluations, we comprehensively compare this search strategy to regularized evolution and Bayesian optimization and demonstrate that it yields improved and more robust results for 13 tabular NAS benchmarks based on NAS-Bench-101, NAS-Bench-1Shot1, NAS-Bench-201 and NAS-HPO bench.
Convergence Analysis of Homotopy-SGD for non-convex optimization
Nov 20, 2020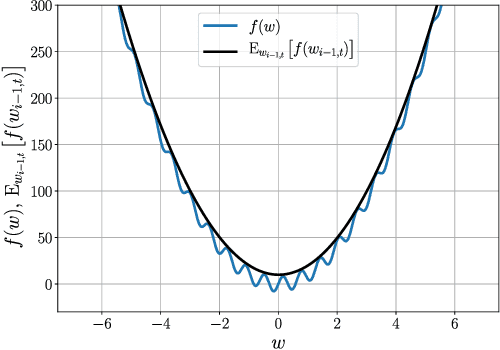
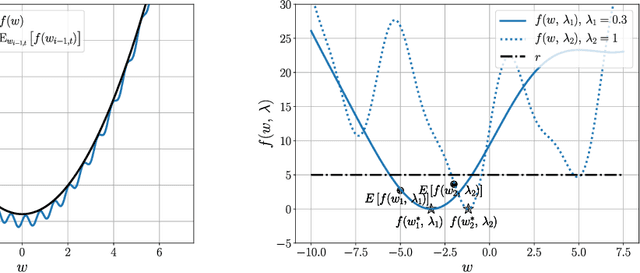
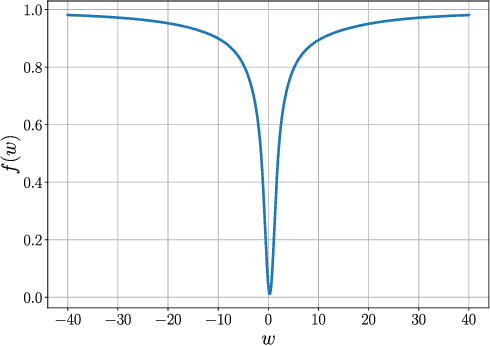

First-order stochastic methods for solving large-scale non-convex optimization problems are widely used in many big-data applications, e.g. training deep neural networks as well as other complex and potentially non-convex machine learning models. Their inexpensive iterations generally come together with slow global convergence rate (mostly sublinear), leading to the necessity of carrying out a very high number of iterations before the iterates reach a neighborhood of a minimizer. In this work, we present a first-order stochastic algorithm based on a combination of homotopy methods and SGD, called Homotopy-Stochastic Gradient Descent (H-SGD), which finds interesting connections with some proposed heuristics in the literature, e.g. optimization by Gaussian continuation, training by diffusion, mollifying networks. Under some mild assumptions on the problem structure, we conduct a theoretical analysis of the proposed algorithm. Our analysis shows that, with a specifically designed scheme for the homotopy parameter, H-SGD enjoys a global linear rate of convergence to a neighborhood of a minimum while maintaining fast and inexpensive iterations. Experimental evaluations confirm the theoretical results and show that H-SGD can outperform standard SGD.
Hyperparameter Transfer Across Developer Adjustments
Oct 25, 2020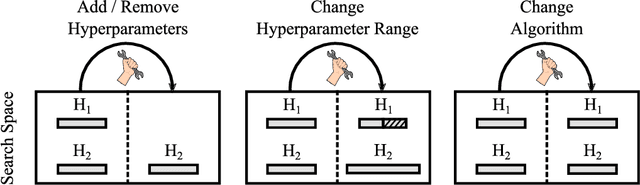

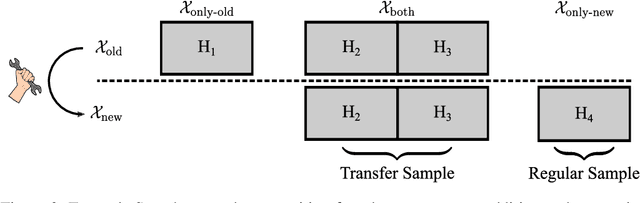
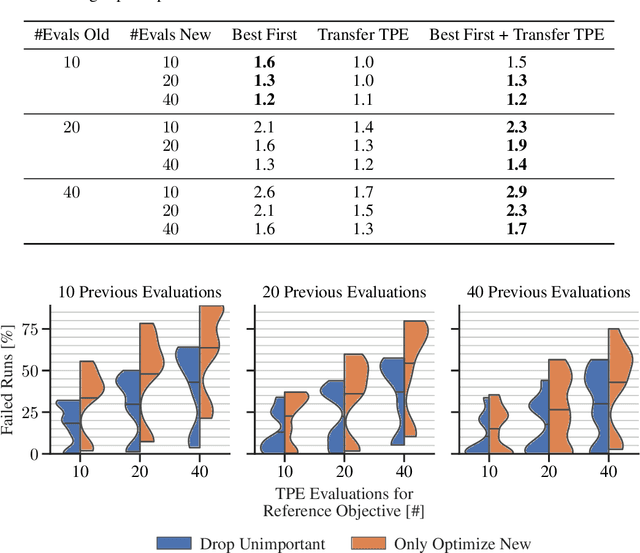
After developer adjustments to a machine learning (ML) algorithm, how can the results of an old hyperparameter optimization (HPO) automatically be used to speedup a new HPO? This question poses a challenging problem, as developer adjustments can change which hyperparameter settings perform well, or even the hyperparameter search space itself. While many approaches exist that leverage knowledge obtained on previous tasks, so far, knowledge from previous development steps remains entirely untapped. In this work, we remedy this situation and propose a new research framework: hyperparameter transfer across adjustments (HT-AA). To lay a solid foundation for this research framework, we provide four simple HT-AA baseline algorithms and eight benchmarks changing various aspects of ML algorithms, their hyperparameter search spaces, and the neural architectures used. The best baseline, on average and depending on the budgets for the old and new HPO, reaches a given performance 1.2--2.6x faster than a prominent HPO algorithm without transfer. As HPO is a crucial step in ML development but requires extensive computational resources, this speedup would lead to faster development cycles, lower costs, and reduced environmental impacts. To make these benefits available to ML developers off-the-shelf and to facilitate future research on HT-AA, we provide python packages for our baselines and benchmarks.