 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Machine Learning Practitioners Still Use Manual Tuning? A Qualitative Study
Mar 03, 2022


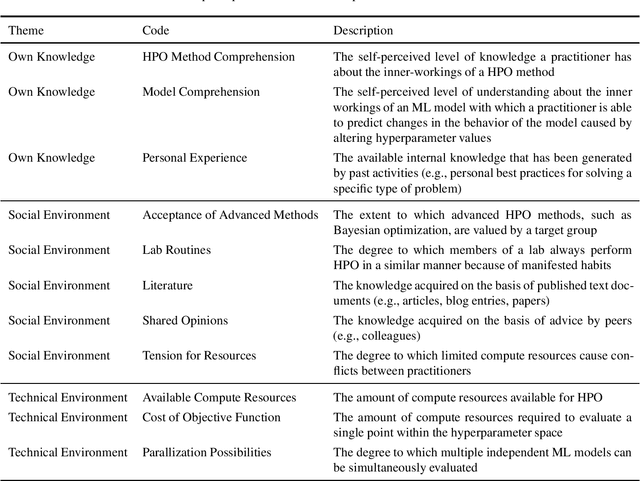
Current advanced hyperparameter optimization (HPO) methods, such as Bayesian optimization, have high sampling efficiency and facilitate replicability. Nonetheless, machine learning (ML) practitioners (e.g., engineers, scientists) mostly apply less advanced HPO methods, which can increase resource consumption during HPO or lead to underoptimized ML models. Therefore, we suspect that practitioners choose their HPO method to achieve different goals, such as decrease practitioner effort and target audience compliance. To develop HPO methods that align with such goals, the reasons why practitioners decide for specific HPO methods must be unveiled and thoroughly understood. Because qualitative research is most suitable to uncover such reasons and find potential explanations for them, we conducted semi-structured interviews to explain why practitioners choose different HPO methods. The interviews revealed six principal practitioner goals (e.g., increasing model comprehension), and eleven key factors that impact decisions for HPO methods (e.g., available computing resources). We deepen the understanding about why practitioners decide for different HPO methods and outline recommendations for improvements of HPO methods by aligning them with practitioner goals.
Neural Architecture Search for Dense Prediction Tasks in Computer Vision
Feb 15, 2022The success of deep learning in recent years has lead to a rising demand for neural network architecture engineering. As a consequence, neural architecture search (NAS), which aims at automatically designing neural network architectures in a data-driven manner rather than manually, has evolved as a popular field of research. With the advent of weight sharing strategies across architectures, NAS has become applicable to a much wider range of problems. In particular, there are now many publications for dense prediction tasks in computer vision that require pixel-level predictions, such as semantic segmentation or object detection. These tasks come with novel challenges, such as higher memory footprints due to high-resolution data, learning multi-scale representations, longer training times, and more complex and larger neural architectures. In this manuscript, we provide an overview of NAS for dense prediction tasks by elaborating on these novel challenges and surveying ways to address them to ease future research and application of existing methods to novel problems.
NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy
Feb 11, 2022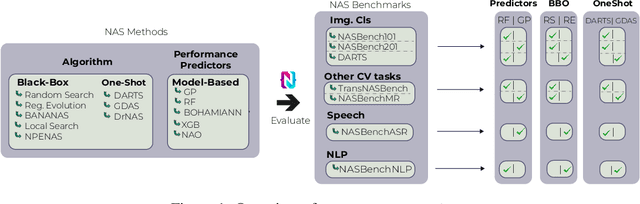
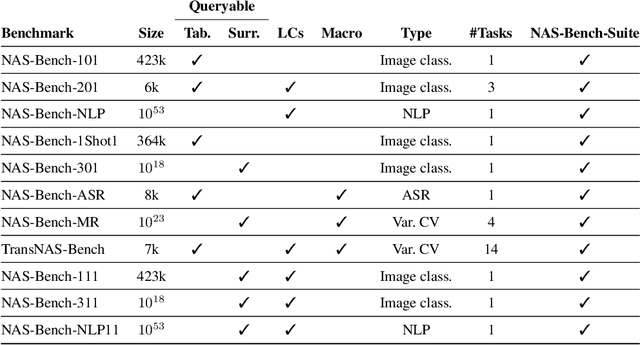
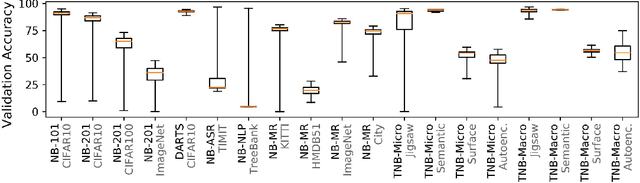
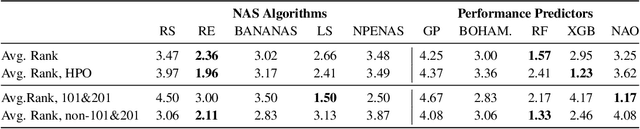
The release of tabular benchmarks, such as NAS-Bench-101 and NAS-Bench-201, has significantly lowered the computational overhead for conducting scientific research in neural architecture search (NAS). Although they have been widely adopted and used to tune real-world NAS algorithms, these benchmarks are limited to small search spaces and focus solely on image classification. Recently, several new NAS benchmarks have been introduced that cover significantly larger search spaces over a wide range of tasks, including object detection, speech recognition, and natural language processing. However, substantial differences among these NAS benchmarks have so far prevented their widespread adoption, limiting researchers to using just a few benchmarks. In this work, we present an in-depth analysis of popular NAS algorithms and performance prediction methods across 25 different combinations of search spaces and datasets, finding that many conclusions drawn from a few NAS benchmarks do not generalize to other benchmarks. To help remedy this problem, we introduce NAS-Bench-Suite, a comprehensive and extensible collection of NAS benchmarks, accessible through a unified interface, created with the aim to facilitate reproducible, generalizable, and rapid NAS research. Our code is available at https://github.com/automl/naslib.
Contextualize Me -- The Case for Context in Reinforcement Learning
Feb 09, 2022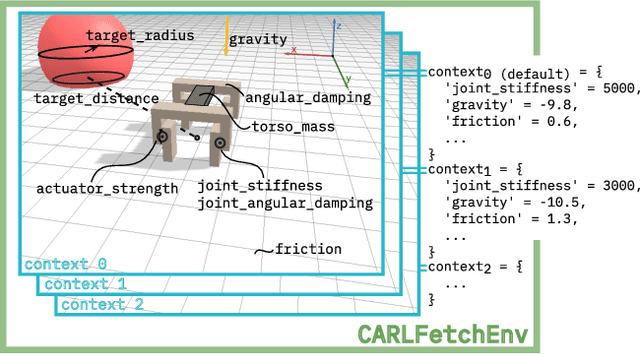
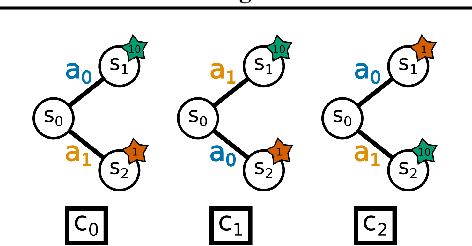
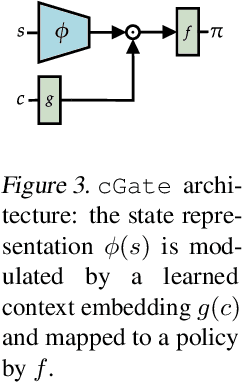
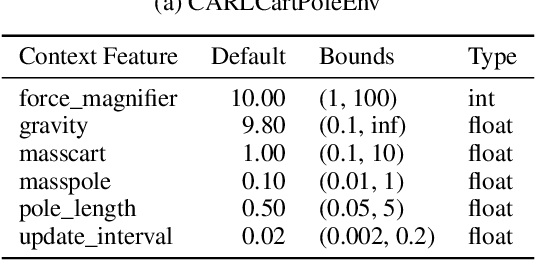
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!
Theory-inspired Parameter Control Benchmarks for Dynamic Algorithm Configuration
Feb 07, 2022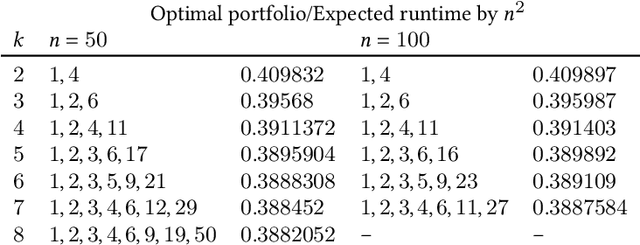
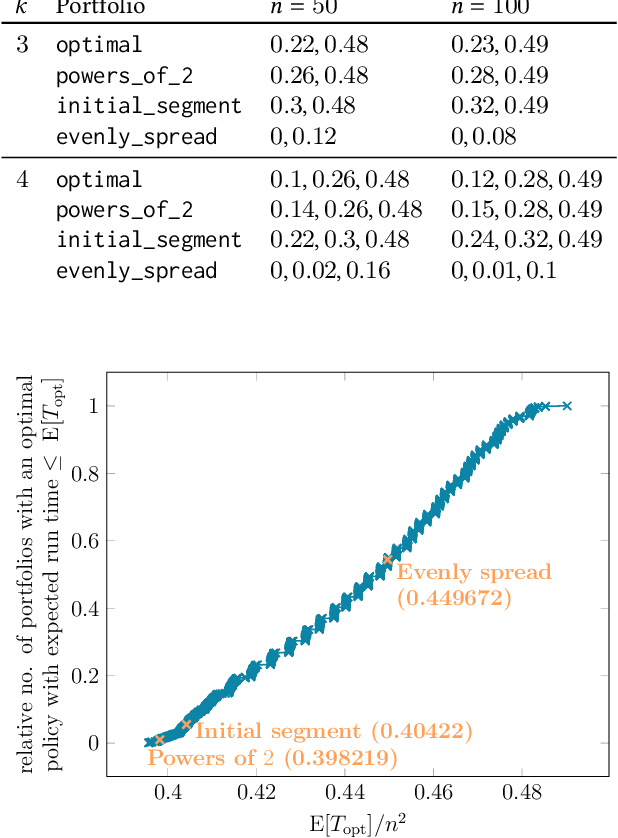
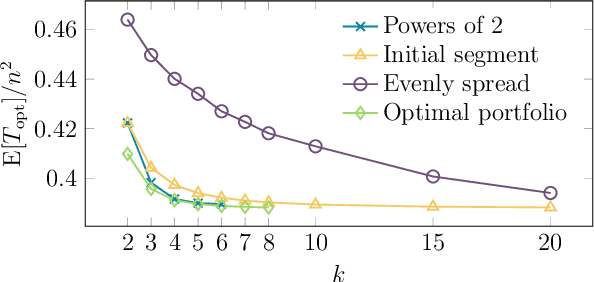
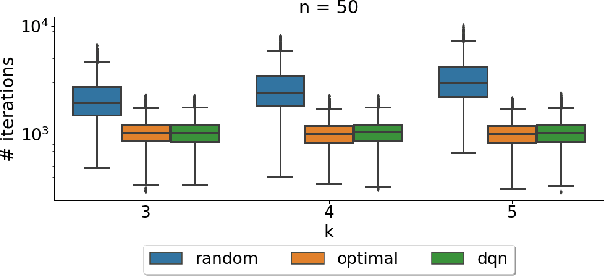
It has long been observed that the performance of evolutionary algorithms and other randomized search heuristics can benefit from a non-static choice of the parameters that steer their optimization behavior. Mechanisms that identify suitable configurations on the fly ("parameter control") or via a dedicated training process ("dynamic algorithm configuration") are therefore an important component of modern evolutionary computation frameworks. Several approaches to address the dynamic parameter setting problem exist, but we barely understand which ones to prefer for which applications. As in classical benchmarking, problem collections with a known ground truth can offer very meaningful insights in this context. Unfortunately, settings with well-understood control policies are very rare. One of the few exceptions for which we know which parameter settings minimize the expected runtime is the LeadingOnes problem. We extend this benchmark by analyzing optimal control policies that can select the parameters only from a given portfolio of possible values. This also allows us to compute optimal parameter portfolios of a given size. We demonstrate the usefulness of our benchmarks by analyzing the behavior of the DDQN reinforcement learning approach for dynamic algorithm configuration.
Learning Synthetic Environments and Reward Networks for Reinforcement Learning
Feb 06, 2022

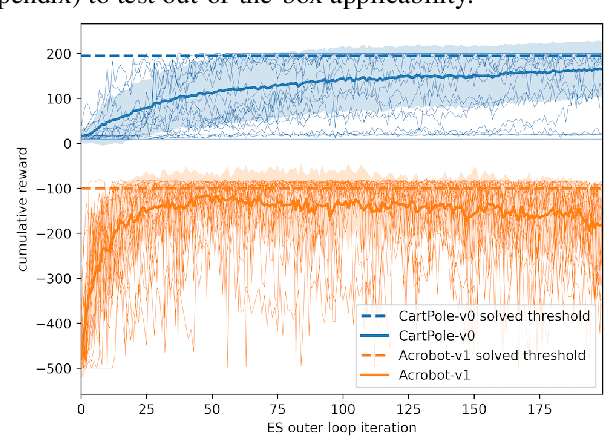

We introduce Synthetic Environments (SEs) and Reward Networks (RNs), represented by neural networks, as proxy environment models for training Reinforcement Learning (RL) agents. We show that an agent, after being trained exclusively on the SE, is able to solve the corresponding real environment. While an SE acts as a full proxy to a real environment by learning about its state dynamics and rewards, an RN is a partial proxy that learns to augment or replace rewards. We use bi-level optimization to evolve SEs and RNs: the inner loop trains the RL agent, and the outer loop trains the parameters of the SE / RN via an evolution strategy. We evaluate our proposed new concept on a broad range of RL algorithms and classic control environments. In a one-to-one comparison, learning an SE proxy requires more interactions with the real environment than training agents only on the real environment. However, once such an SE has been learned, we do not need any interactions with the real environment to train new agents. Moreover, the learned SE proxies allow us to train agents with fewer interactions while maintaining the original task performance. Our empirical results suggest that SEs achieve this result by learning informed representations that bias the agents towards relevant states. Moreover, we find that these proxies are robust against hyperparameter variation and can also transfer to unseen agents.
Transformers Can Do Bayesian Inference
Jan 25, 2022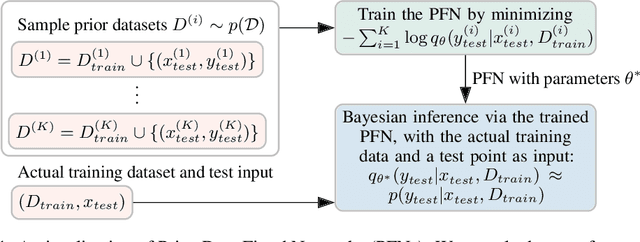
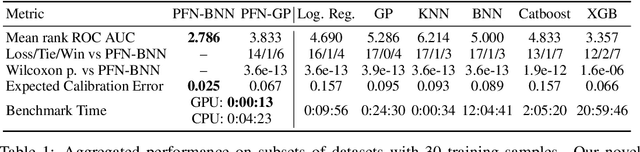
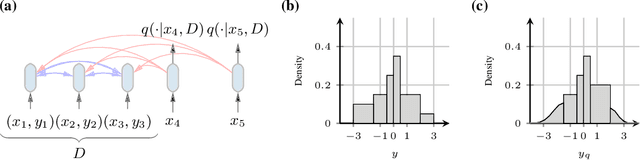

Currently, it is hard to reap the benefits of deep learning for Bayesian methods, which allow the explicit specification of prior knowledge and accurately capture model uncertainty. We present Prior-Data Fitted Networks (PFNs). PFNs leverage large-scale machine learning techniques to approximate a large set of posteriors. The only requirement for PFNs to work is the ability to sample from a prior distribution over supervised learning tasks (or functions). Our method restates the objective of posterior approximation as a supervised classification problem with a set-valued input: it repeatedly draws a task (or function) from the prior, draws a set of data points and their labels from it, masks one of the labels and learns to make probabilistic predictions for it based on the set-valued input of the rest of the data points. Presented with a set of samples from a new supervised learning task as input, PFNs make probabilistic predictions for arbitrary other data points in a single forward propagation, having learned to approximate Bayesian inference. We demonstrate that PFNs can near-perfectly mimic Gaussian processes and also enable efficient Bayesian inference for intractable problems, with over 200-fold speedups in multiple setups compared to current methods. We obtain strong results in very diverse areas such as Gaussian process regression, Bayesian neural networks, classification for small tabular data sets, and few-shot image classification, demonstrating the generality of PFNs. Code and trained PFNs are released at https://github.com/automl/TransformersCanDoBayesianInference.
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
Jan 11, 2022
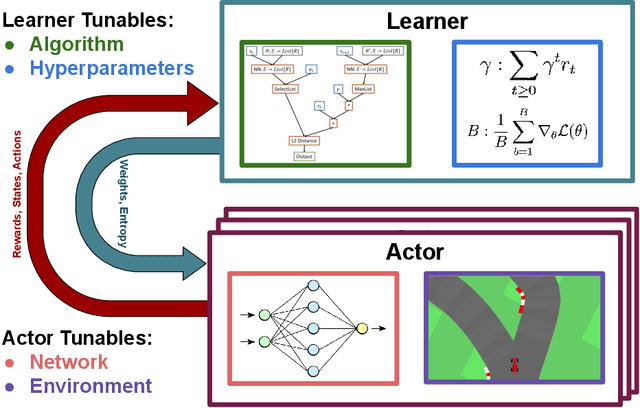
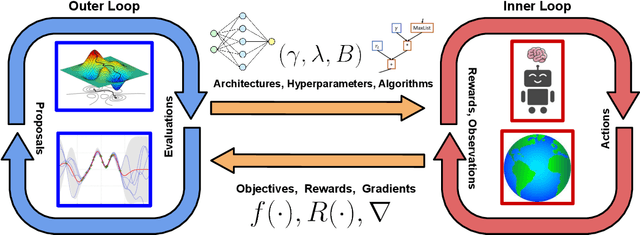

The combination of Reinforcement Learning (RL) with deep learning has led to a series of impressive feats, with many believing (deep) RL provides a path towards generally capable agents. However, the success of RL agents is often highly sensitive to design choices in the training process, which may require tedious and error-prone manual tuning. This makes it challenging to use RL for new problems, while also limits its full potential. In many other areas of machine learning, AutoML has shown it is possible to automate such design choices and has also yielded promising initial results when applied to RL. However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go. Given the diversity of methods and environments considered in RL, much of the research has been conducted in distinct subfields, ranging from meta-learning to evolution. In this survey we seek to unify the field of AutoRL, we provide a common taxonomy, discuss each area in detail and pose open problems which would be of interest to researchers going forward.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022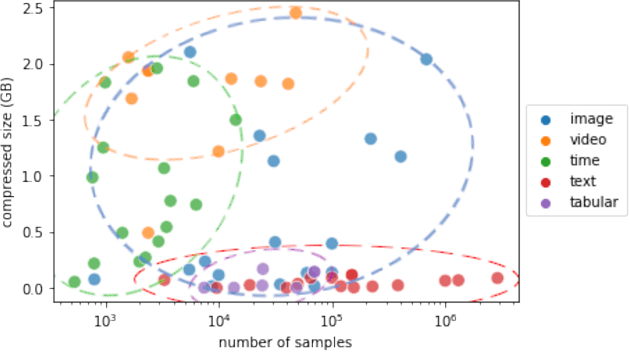
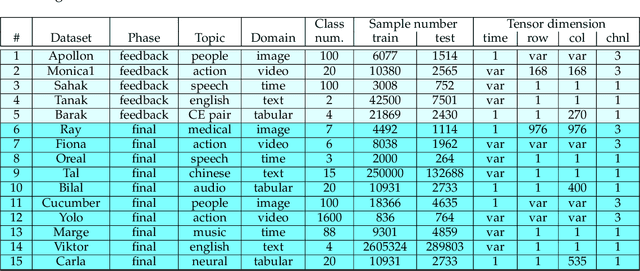
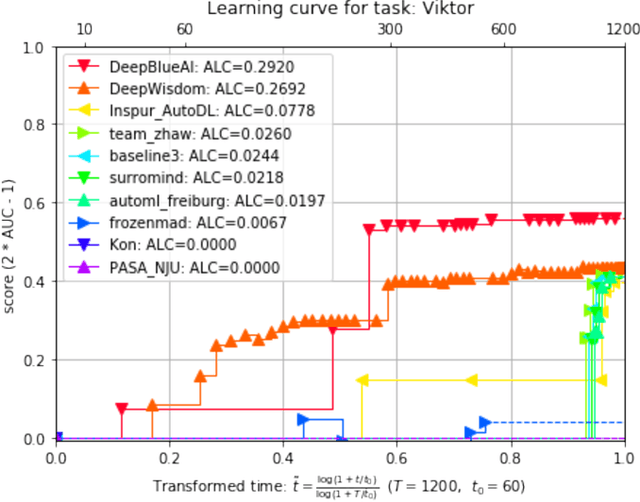
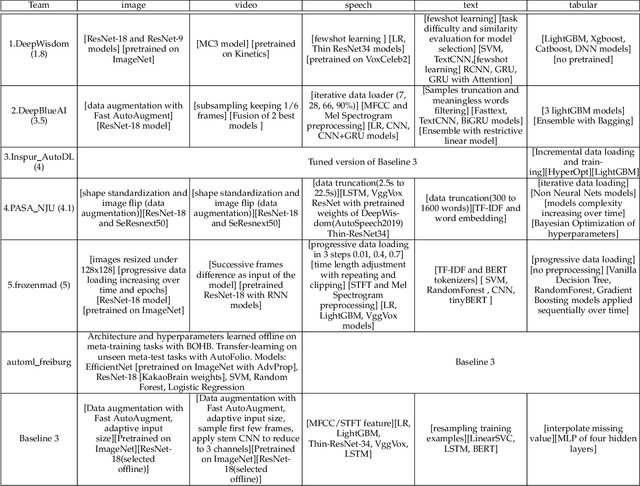
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version
NAS-Bench-x11 and the Power of Learning Curves
Nov 05, 2021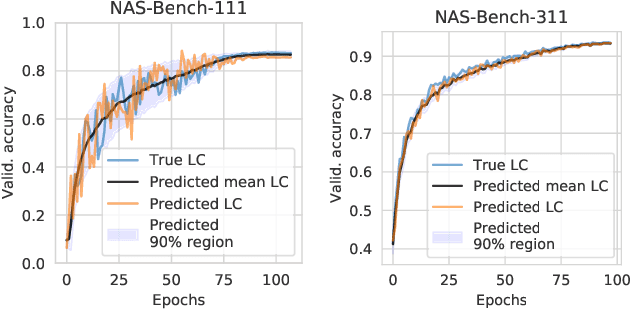
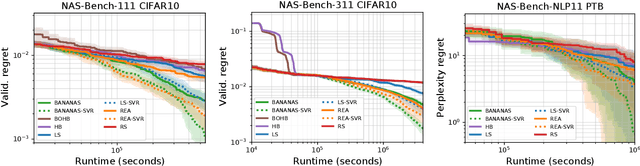
While early research in neural architecture search (NAS) required extreme computational resources, the recent releases of tabular and surrogate benchmarks have greatly increased the speed and reproducibility of NAS research. However, two of the most popular benchmarks do not provide the full training information for each architecture. As a result, on these benchmarks it is not possible to run many types of multi-fidelity techniques, such as learning curve extrapolation, that require evaluating architectures at arbitrary epochs. In this work, we present a method using singular value decomposition and noise modeling to create surrogate benchmarks, NAS-Bench-111, NAS-Bench-311, and NAS-Bench-NLP11, that output the full training information for each architecture, rather than just the final validation accuracy. We demonstrate the power of using the full training information by introducing a learning curve extrapolation framework to modify single-fidelity algorithms, showing that it leads to improvements over popular single-fidelity algorithms which claimed to be state-of-the-art upon release. Our code and pretrained models are available at https://github.com/automl/nas-bench-x11.