 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust field-level likelihood-free inference with galaxies
Feb 27, 2023We train graph neural networks to perform field-level likelihood-free inference using galaxy catalogs from state-of-the-art hydrodynamic simulations of the CAMELS project. Our models are rotationally, translationally, and permutation invariant and have no scale cutoff. By training on galaxy catalogs that only contain the 3D positions and radial velocities of approximately $1,000$ galaxies in tiny volumes of $(25~h^{-1}{\rm Mpc})^3$, our models achieve a precision of approximately $12$% when inferring the value of $\Omega_{\rm m}$. To test the robustness of our models, we evaluated their performance on galaxy catalogs from thousands of hydrodynamic simulations, each with different efficiencies of supernova and AGN feedback, run with five different codes and subgrid models, including IllustrisTNG, SIMBA, Astrid, Magneticum, and SWIFT-EAGLE. Our results demonstrate that our models are robust to astrophysics, subgrid physics, and subhalo/galaxy finder changes. Furthermore, we test our models on 1,024 simulations that cover a vast region in parameter space - variations in 5 cosmological and 23 astrophysical parameters - finding that the model extrapolates really well. Including both positions and velocities are key to building robust models, and our results indicate that our networks have likely learned an underlying physical relation that does not depend on galaxy formation and is valid on scales larger than, at least, $~\sim10~h^{-1}{\rm kpc}$.
Robust field-level inference with dark matter halos
Sep 14, 2022
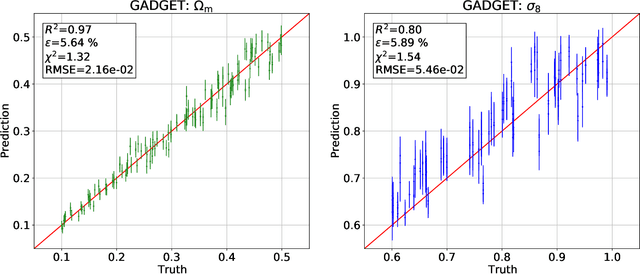
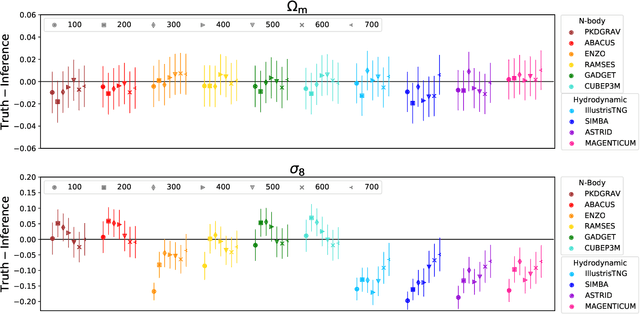

We train graph neural networks on halo catalogues from Gadget N-body simulations to perform field-level likelihood-free inference of cosmological parameters. The catalogues contain $\lesssim$5,000 halos with masses $\gtrsim 10^{10}~h^{-1}M_\odot$ in a periodic volume of $(25~h^{-1}{\rm Mpc})^3$; every halo in the catalogue is characterized by several properties such as position, mass, velocity, concentration, and maximum circular velocity. Our models, built to be permutationally, translationally, and rotationally invariant, do not impose a minimum scale on which to extract information and are able to infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a mean relative error of $\sim6\%$, when using positions plus velocities and positions plus masses, respectively. More importantly, we find that our models are very robust: they can infer the value of $\Omega_{\rm m}$ and $\sigma_8$ when tested using halo catalogues from thousands of N-body simulations run with five different N-body codes: Abacus, CUBEP$^3$M, Enzo, PKDGrav3, and Ramses. Surprisingly, the model trained to infer $\Omega_{\rm m}$ also works when tested on thousands of state-of-the-art CAMELS hydrodynamic simulations run with four different codes and subgrid physics implementations. Using halo properties such as concentration and maximum circular velocity allow our models to extract more information, at the expense of breaking the robustness of the models. This may happen because the different N-body codes are not converged on the relevant scales corresponding to these parameters.
The SZ flux-mass relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
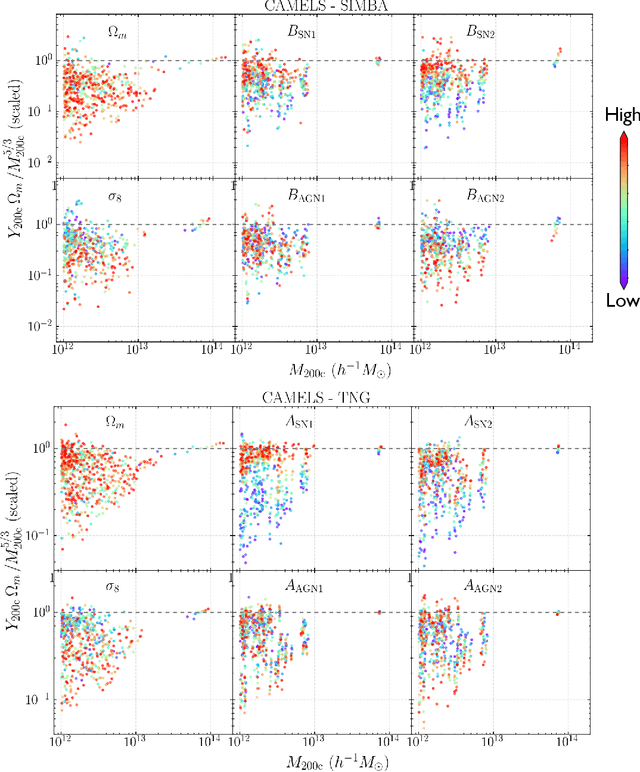
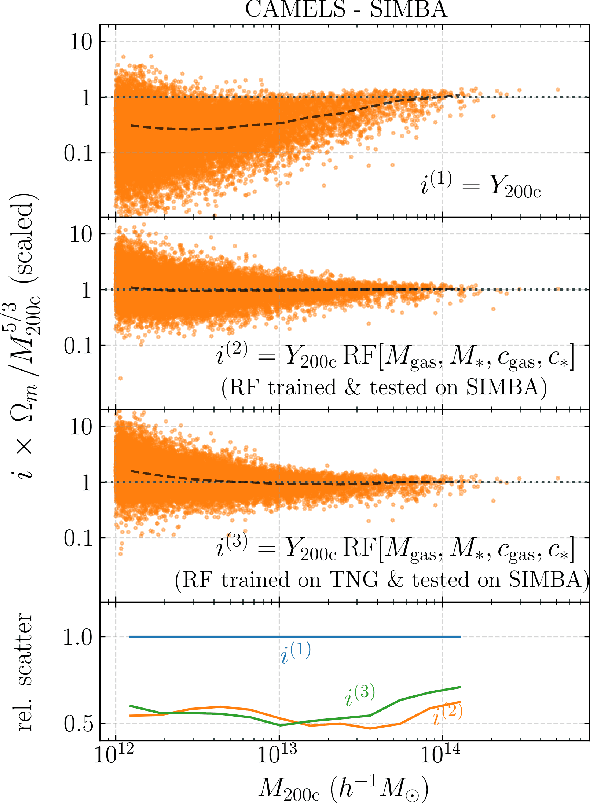

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.
Simple lessons from complex learning: what a neural network model learns about cosmic structure formation
Jun 14, 2022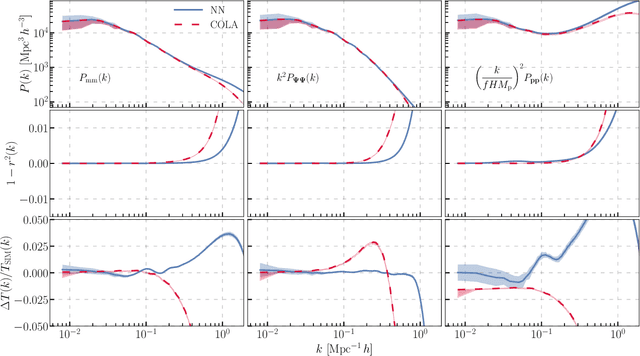
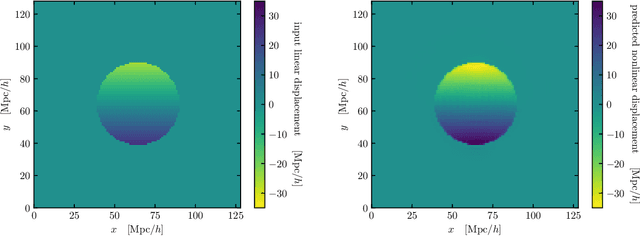
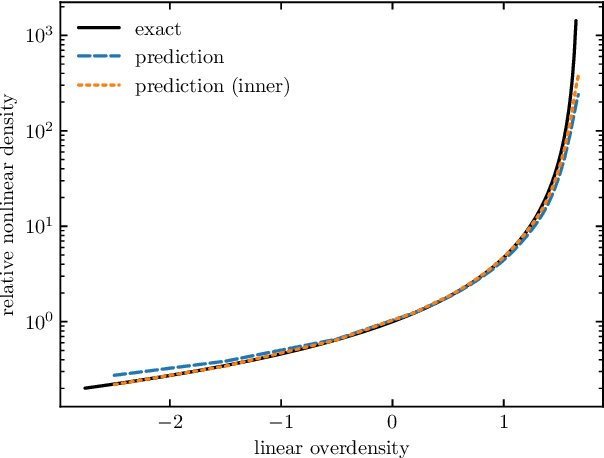
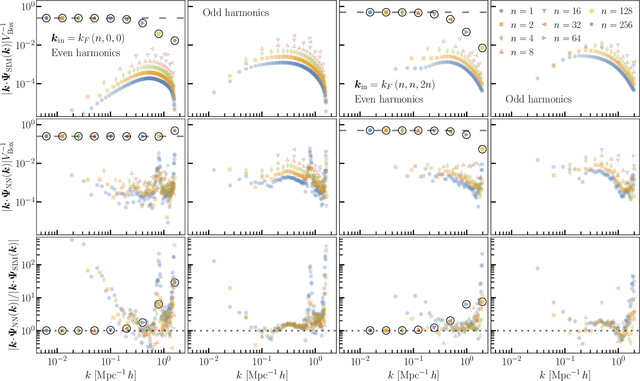
We train a neural network model to predict the full phase space evolution of cosmological N-body simulations. Its success implies that the neural network model is accurately approximating the Green's function expansion that relates the initial conditions of the simulations to its outcome at later times in the deeply nonlinear regime. We test the accuracy of this approximation by assessing its performance on well understood simple cases that have either known exact solutions or well understood expansions. These scenarios include spherical configurations, isolated plane waves, and two interacting plane waves: initial conditions that are very different from the Gaussian random fields used for training. We find our model generalizes well to these well understood scenarios, demonstrating that the networks have inferred general physical principles and learned the nonlinear mode couplings from the complex, random Gaussian training data. These tests also provide a useful diagnostic for finding the model's strengths and weaknesses, and identifying strategies for model improvement. We also test the model on initial conditions that contain only transverse modes, a family of modes that differ not only in their phases but also in their evolution from the longitudinal growing modes used in the training set. When the network encounters these initial conditions that are orthogonal to the training set, the model fails completely. In addition to these simple configurations, we evaluate the model's predictions for the density, displacement, and momentum power spectra with standard initial conditions for N-body simulations. We compare these summary statistics against N-body results and an approximate, fast simulation method called COLA. Our model achieves percent level accuracy at nonlinear scales of $k\sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a significant improvement over COLA.
Field Level Neural Network Emulator for Cosmological N-body Simulations
Jun 14, 2022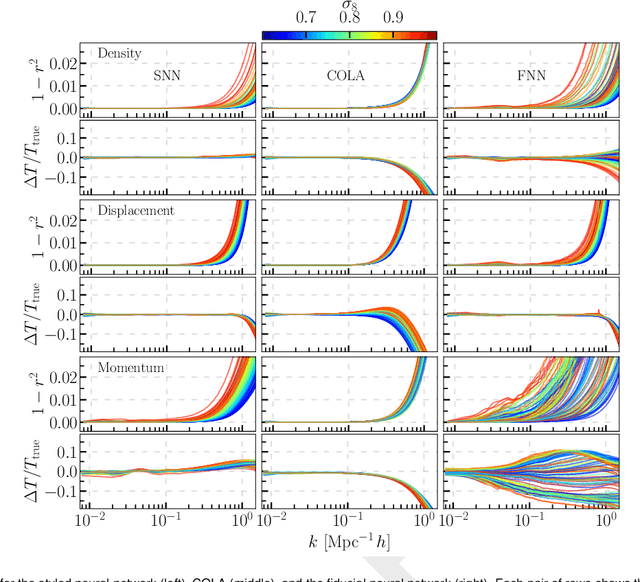
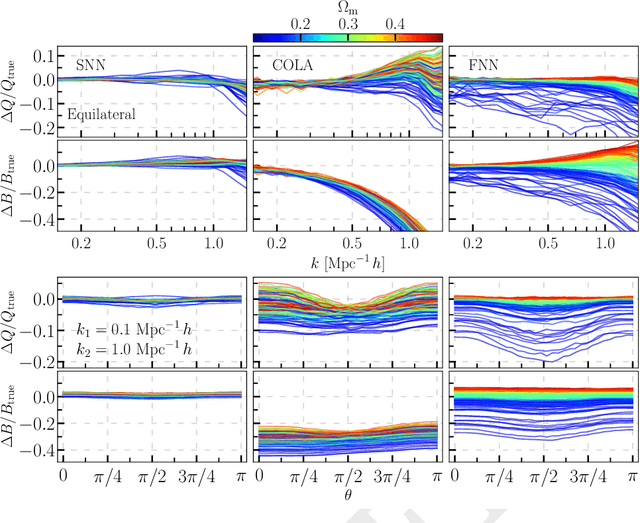
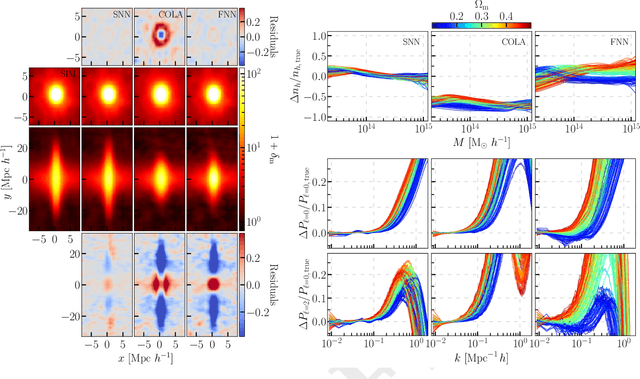
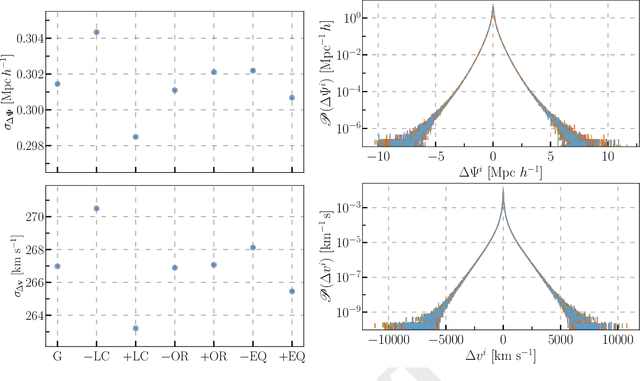
We build a field level emulator for cosmic structure formation that is accurate in the nonlinear regime. Our emulator consists of two convolutional neural networks trained to output the nonlinear displacements and velocities of N-body simulation particles based on their linear inputs. Cosmology dependence is encoded in the form of style parameters at each layer of the neural network, enabling the emulator to effectively interpolate the outcomes of structure formation between different flat $\Lambda$CDM cosmologies over a wide range of background matter densities. The neural network architecture makes the model differentiable by construction, providing a powerful tool for fast field level inference. We test the accuracy of our method by considering several summary statistics, including the density power spectrum with and without redshift space distortions, the displacement power spectrum, the momentum power spectrum, the density bispectrum, halo abundances, and halo profiles with and without redshift space distortions. We compare these statistics from our emulator with the full N-body results, the COLA method, and a fiducial neural network with no cosmological dependence. We find our emulator gives accurate results down to scales of $k \sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a considerable improvement over both COLA and the fiducial neural network. We also demonstrate that our emulator generalizes well to initial conditions containing primordial non-Gaussianity, without the need for any additional style parameters or retraining.
Fast and realistic large-scale structure from machine-learning-augmented random field simulations
May 16, 2022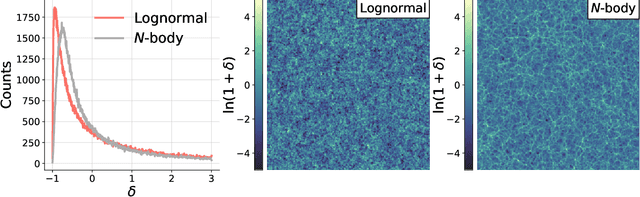
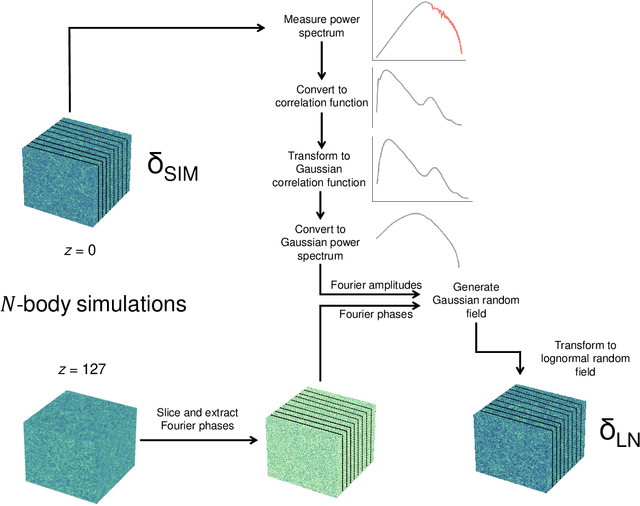
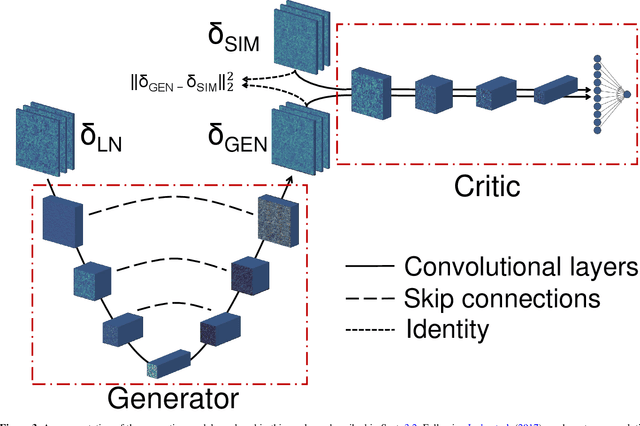
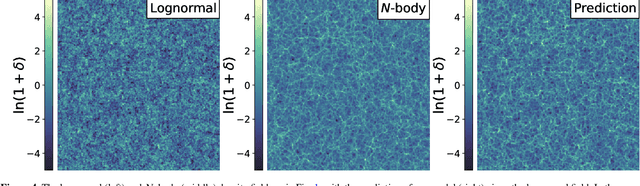
Producing thousands of simulations of the dark matter distribution in the Universe with increasing precision is a challenging but critical task to facilitate the exploitation of current and forthcoming cosmological surveys. Many inexpensive substitutes to full $N$-body simulations have been proposed, even though they often fail to reproduce the statistics of the smaller, non-linear scales. Among these alternatives, a common approximation is represented by the lognormal distribution, which comes with its own limitations as well, while being extremely fast to compute even for high-resolution density fields. In this work, we train a machine learning model to transform projected lognormal dark matter density fields to more realistic dark matter maps, as obtained from full $N$-body simulations. We detail the procedure that we follow to generate highly correlated pairs of lognormal and simulated maps, which we use as our training data, exploiting the information of the Fourier phases. We demonstrate the performance of our model comparing various statistical tests with different field resolutions, redshifts and cosmological parameters, proving its robustness and explaining its current limitations. The augmented lognormal random fields reproduce the power spectrum up to wavenumbers of $1 \ h \ \rm{Mpc}^{-1}$, the bispectrum and the peak counts within 10%, and always within the error bars, of the fiducial target simulations. Finally, we describe how we plan to integrate our proposed model with existing tools to yield more accurate spherical random fields for weak lensing analysis, going beyond the lognormal approximation.
Learning cosmology and clustering with cosmic graphs
Apr 28, 2022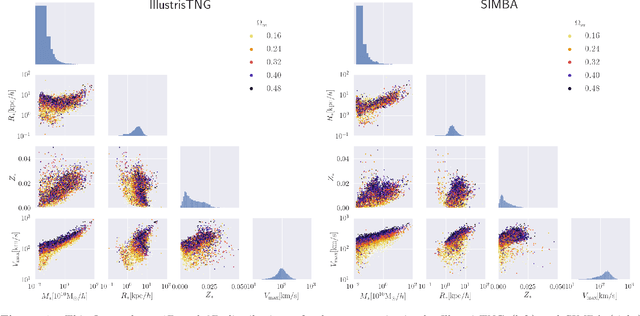
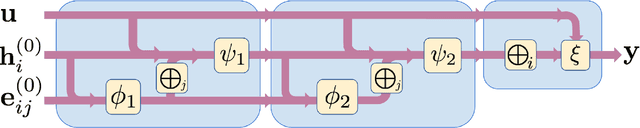
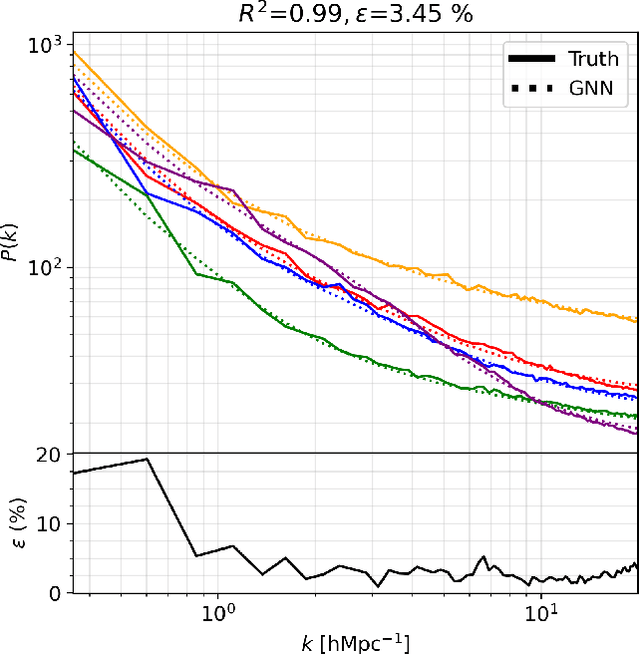
We train deep learning models on thousands of galaxy catalogues from the state-of-the-art hydrodynamic simulations of the CAMELS project to perform regression and inference. We employ Graph Neural Networks (GNNs), architectures designed to work with irregular and sparse data, like the distribution of galaxies in the Universe. We first show that GNNs can learn to compute the power spectrum of galaxy catalogues with a few percent accuracy. We then train GNNs to perform likelihood-free inference at the galaxy-field level. Our models are able to infer the value of $\Omega_{\rm m}$ with a $\sim12\%-13\%$ accuracy just from the positions of $\sim1000$ galaxies in a volume of $(25~h^{-1}{\rm Mpc})^3$ at $z=0$ while accounting for astrophysical uncertainties as modelled in CAMELS. Incorporating information from galaxy properties, such as stellar mass, stellar metallicity, and stellar radius, increases the accuracy to $4\%-8\%$. Our models are built to be translational and rotational invariant, and they can extract information from any scale larger than the minimum distance between two galaxies. However, our models are not completely robust: testing on simulations run with a different subgrid physics than the ones used for training does not yield as accurate results.
Machine Learning and Cosmology
Mar 15, 2022Methods based on machine learning have recently made substantial inroads in many corners of cosmology. Through this process, new computational tools, new perspectives on data collection, model development, analysis, and discovery, as well as new communities and educational pathways have emerged. Despite rapid progress, substantial potential at the intersection of cosmology and machine learning remains untapped. In this white paper, we summarize current and ongoing developments relating to the application of machine learning within cosmology and provide a set of recommendations aimed at maximizing the scientific impact of these burgeoning tools over the coming decade through both technical development as well as the fostering of emerging communities.
Augmenting astrophysical scaling relations with machine learning : application to reducing the SZ flux-mass scatter
Jan 17, 2022
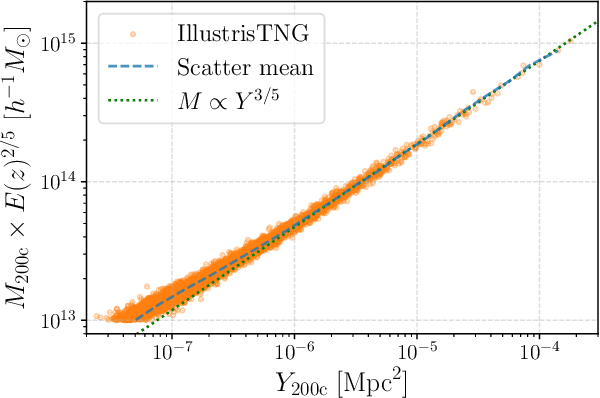
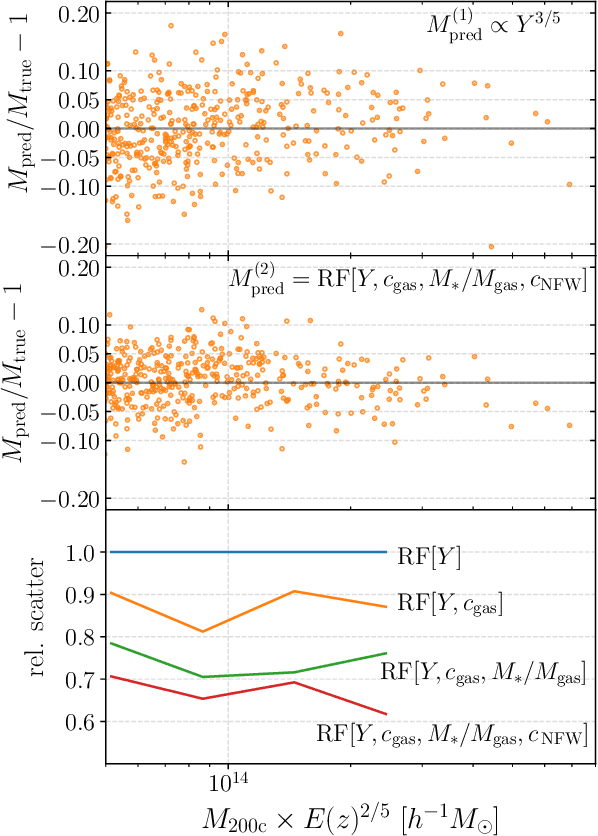
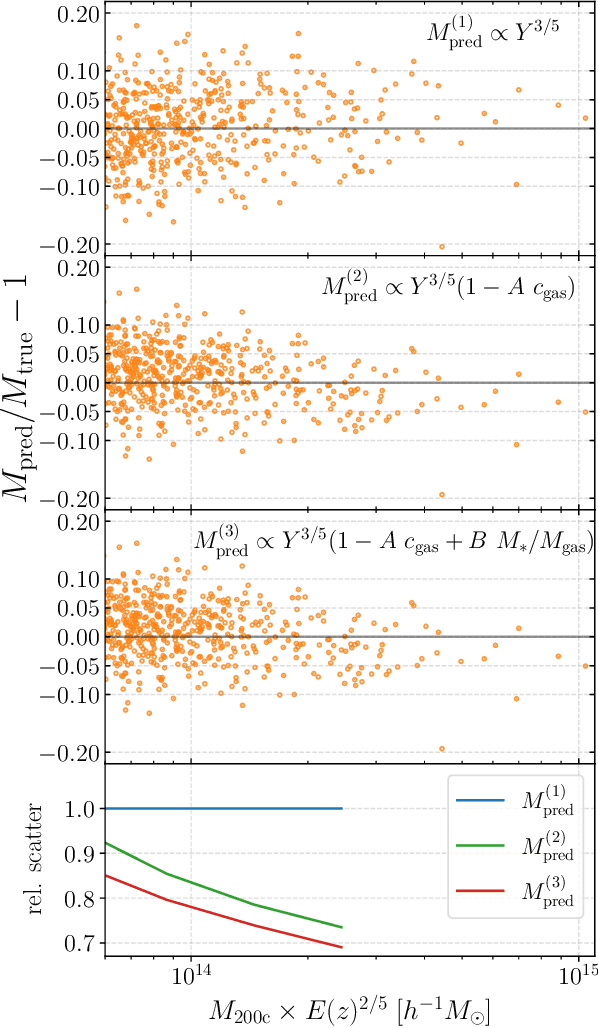
Complex systems (stars, supernovae, galaxies, and clusters) often exhibit low scatter relations between observable properties (e.g., luminosity, velocity dispersion, oscillation period, temperature). These scaling relations can illuminate the underlying physics and can provide observational tools for estimating masses and distances. Machine learning can provide a systematic way to search for new scaling relations (or for simple extensions to existing relations) in abstract high-dimensional parameter spaces. We use a machine learning tool called symbolic regression (SR), which models the patterns in a given dataset in the form of analytic equations. We focus on the Sunyaev-Zeldovich flux$-$cluster mass relation ($Y_\mathrm{SZ}-M$), the scatter in which affects inference of cosmological parameters from cluster abundance data. Using SR on the data from the IllustrisTNG hydrodynamical simulation, we find a new proxy for cluster mass which combines $Y_\mathrm{SZ}$ and concentration of ionized gas ($c_\mathrm{gas}$): $M \propto Y_\mathrm{conc}^{3/5} \equiv Y_\mathrm{SZ}^{3/5} (1-A\, c_\mathrm{gas})$. $Y_\mathrm{conc}$ reduces the scatter in the predicted $M$ by $\sim 20-30$% for large clusters ($M\gtrsim 10^{14}\, h^{-1} \, M_\odot$) at both high and low redshifts, as compared to using just $Y_\mathrm{SZ}$. We show that the dependence on $c_\mathrm{gas}$ is linked to cores of clusters exhibiting larger scatter than their outskirts. Finally, we test $Y_\mathrm{conc}$ on clusters from simulations of the CAMELS project and show that $Y_\mathrm{conc}$ is robust against variations in cosmology, astrophysics, subgrid physics, and cosmic variance. Our results and methodology can be useful for accurate multiwavelength cluster mass estimation from current and upcoming CMB and X-ray surveys like ACT, SO, SPT, eROSITA and CMB-S4.
The CAMELS project: public data release
Jan 04, 2022
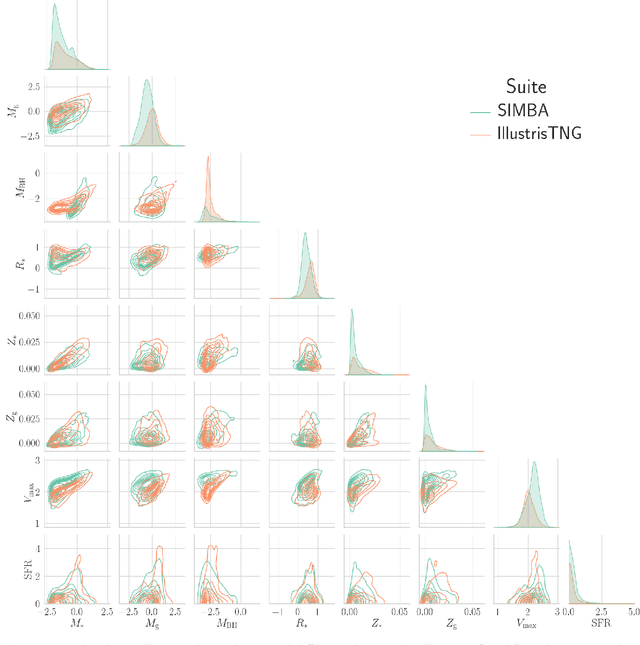
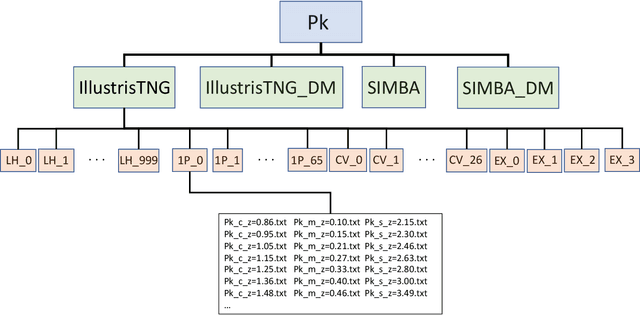
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.