 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Early Universe with Deep Learning
Sep 26, 2025Hydrogen is the most abundant element in our Universe. The first generation of stars and galaxies produced photons that ionized hydrogen gas, driving a cosmological event known as the Epoch of Reionization (EoR). The upcoming Square Kilometre Array Observatory (SKAO) will map the distribution of neutral hydrogen during this era, aiding in the study of the properties of these first-generation objects. Extracting astrophysical information will be challenging, as SKAO will produce a tremendous amount of data where the hydrogen signal will be contaminated with undesired foreground contamination and instrumental systematics. To address this, we develop the latest deep learning techniques to extract information from the 2D power spectra of the hydrogen signal expected from SKAO. We apply a series of neural network models to these measurements and quantify their ability to predict the history of cosmic hydrogen reionization, which is connected to the increasing number and efficiency of early photon sources. We show that the study of the early Universe benefits from modern deep learning technology. In particular, we demonstrate that dedicated machine learning algorithms can achieve more than a $0.95$ $R^2$ score on average in recovering the reionization history. This enables accurate and precise cosmological and astrophysical inference of structure formation in the early Universe.
* EPIA 2025 preprint version, 12 pages, 3 figures
Savage-Dickey density ratio estimation with normalizing flows for Bayesian model comparison
Jun 04, 2025A core motivation of science is to evaluate which scientific model best explains observed data. Bayesian model comparison provides a principled statistical approach to comparing scientific models and has found widespread application within cosmology and astrophysics. Calculating the Bayesian evidence is computationally challenging, especially as we continue to explore increasingly more complex models. The Savage-Dickey density ratio (SDDR) provides a method to calculate the Bayes factor (evidence ratio) between two nested models using only posterior samples from the super model. The SDDR requires the calculation of a normalised marginal distribution over the extra parameters of the super model, which has typically been performed using classical density estimators, such as histograms. Classical density estimators, however, can struggle to scale to high-dimensional settings. We introduce a neural SDDR approach using normalizing flows that can scale to settings where the super model contains a large number of extra parameters. We demonstrate the effectiveness of this neural SDDR methodology applied to both toy and realistic cosmological examples. For a field-level inference setting, we show that Bayes factors computed for a Bayesian hierarchical model (BHM) and simulation-based inference (SBI) approach are consistent, providing further validation that SBI extracts as much cosmological information from the field as the BHM approach. The SDDR estimator with normalizing flows is implemented in the open-source harmonic Python package.
Transfer learning for multifidelity simulation-based inference in cosmology
May 27, 2025Simulation-based inference (SBI) enables cosmological parameter estimation when closed-form likelihoods or models are unavailable. However, SBI relies on machine learning for neural compression and density estimation. This requires large training datasets which are prohibitively expensive for high-quality simulations. We overcome this limitation with multifidelity transfer learning, combining less expensive, lower-fidelity simulations with a limited number of high-fidelity simulations. We demonstrate our methodology on dark matter density maps from two separate simulation suites in the hydrodynamical CAMELS Multifield Dataset. Pre-training on dark-matter-only $N$-body simulations reduces the required number of high-fidelity hydrodynamical simulations by a factor between $8$ and $15$, depending on the model complexity, posterior dimensionality, and performance metrics used. By leveraging cheaper simulations, our approach enables performant and accurate inference on high-fidelity models while substantially reducing computational costs.
Anchors no more: Using peculiar velocities to constrain $H_0$ and the primordial Universe without calibrators
Apr 14, 2025We develop a novel approach to constrain the Hubble parameter $H_0$ and the primordial power spectrum amplitude $A_\mathrm{s}$ using supernovae type Ia (SNIa) data. By considering SNIa as tracers of the peculiar velocity field, we can model their distance and their covariance as a function of cosmological parameters without the need of calibrators like Cepheids; this yields a new independent probe of the large-scale structure based on SNIa data without distance anchors. Crucially, we implement a differentiable pipeline in JAX, including efficient emulators and affine sampling, reducing inference time from years to hours on a single GPU. We first validate our method on mock datasets, demonstrating that we can constrain $H_0$ and $\log 10^{10}A_\mathrm{s}$ within $\sim10\%$ using $\sim10^3$ SNIa. We then test our pipeline with SNIa from an $N$-body simulation, obtaining $7\%$-level unbiased constraints on $H_0$ with a moderate noise level. We finally apply our method to Pantheon+ data, constraining $H_0$ at the $10\%$ level without Cepheids when fixing $A_\mathrm{s}$ to its $\it{Planck}$ value. On the other hand, we obtain $15\%$-level constraints on $\log 10^{10}A_\mathrm{s}$ in agreement with $\it{Planck}$ when including Cepheids in the analysis. In light of upcoming observations of low redshift SNIa from the Zwicky Transient Facility and the Vera Rubin Legacy Survey of Space and Time, surveys for which our method will develop its full potential, we make our code publicly available.
The future of cosmological likelihood-based inference: accelerated high-dimensional parameter estimation and model comparison
May 21, 2024We advocate for a new paradigm of cosmological likelihood-based inference, leveraging recent developments in machine learning and its underlying technology, to accelerate Bayesian inference in high-dimensional settings. Specifically, we combine (i) emulation, where a machine learning model is trained to mimic cosmological observables, e.g. CosmoPower-JAX; (ii) differentiable and probabilistic programming, e.g. JAX and NumPyro, respectively; (iii) scalable Markov chain Monte Carlo (MCMC) sampling techniques that exploit gradients, e.g. Hamiltonian Monte Carlo; and (iv) decoupled and scalable Bayesian model selection techniques that compute the Bayesian evidence purely from posterior samples, e.g. the learned harmonic mean implemented in harmonic. This paradigm allows us to carry out a complete Bayesian analysis, including both parameter estimation and model selection, in a fraction of the time of traditional approaches. First, we demonstrate the application of this paradigm on a simulated cosmic shear analysis for a Stage IV survey in 37- and 39-dimensional parameter spaces, comparing $\Lambda$CDM and a dynamical dark energy model ($w_0w_a$CDM). We recover posterior contours and evidence estimates that are in excellent agreement with those computed by the traditional nested sampling approach while reducing the computational cost from 8 months on 48 CPU cores to 2 days on 12 GPUs. Second, we consider a joint analysis between three simulated next-generation surveys, each performing a 3x2pt analysis, resulting in 157- and 159-dimensional parameter spaces. Standard nested sampling techniques are simply not feasible in this high-dimensional setting, requiring a projected 12 years of compute time on 48 CPU cores; on the other hand, the proposed approach only requires 8 days of compute time on 24 GPUs. All packages used in our analyses are publicly available.
A representation learning approach to probe for dynamical dark energy in matter power spectra
Oct 16, 2023



We present DE-VAE, a variational autoencoder (VAE) architecture to search for a compressed representation of dynamical dark energy (DE) models in observational studies of the cosmic large-scale structure. DE-VAE is trained on matter power spectra boosts generated at wavenumbers $k\in(0.01-2.5) \ h/\rm{Mpc}$ and at four redshift values $z\in(0.1,0.48,0.78,1.5)$ for the most typical dynamical DE parametrization with two extra parameters describing an evolving DE equation of state. The boosts are compressed to a lower-dimensional representation, which is concatenated with standard cold dark matter (CDM) parameters and then mapped back to reconstructed boosts; both the compression and the reconstruction components are parametrized as neural networks. Remarkably, we find that a single latent parameter is sufficient to predict 95% (99%) of DE power spectra generated over a broad range of cosmological parameters within $1\sigma$ ($2\sigma$) of a Gaussian error which includes cosmic variance, shot noise and systematic effects for a Stage IV-like survey. This single parameter shows a high mutual information with the two DE parameters, and these three variables can be linked together with an explicit equation through symbolic regression. Considering a model with two latent variables only marginally improves the accuracy of the predictions, and adding a third latent variable has no significant impact on the model's performance. We discuss how the DE-VAE architecture can be extended from a proof of concept to a general framework to be employed in the search for a common lower-dimensional parametrization of a wide range of beyond-$\Lambda$CDM models and for different cosmological datasets. Such a framework could then both inform the development of cosmological surveys by targeting optimal probes, and provide theoretical insight into the common phenomenological aspects of beyond-$\Lambda$CDM models.
A robust estimator of mutual information for deep learning interpretability
Oct 31, 2022We develop the use of mutual information (MI), a well-established metric in information theory, to interpret the inner workings of deep learning models. To accurately estimate MI from a finite number of samples, we present GMM-MI (pronounced $``$Jimmie$"$), an algorithm based on Gaussian mixture models that can be applied to both discrete and continuous settings. GMM-MI is computationally efficient, robust to the choice of hyperparameters and provides the uncertainty on the MI estimate due to the finite sample size. We extensively validate GMM-MI on toy data for which the ground truth MI is known, comparing its performance against established mutual information estimators. We then demonstrate the use of our MI estimator in the context of representation learning, working with synthetic data and physical datasets describing highly non-linear processes. We train deep learning models to encode high-dimensional data within a meaningful compressed (latent) representation, and use GMM-MI to quantify both the level of disentanglement between the latent variables, and their association with relevant physical quantities, thus unlocking the interpretability of the latent representation. We make GMM-MI publicly available.
Fast and realistic large-scale structure from machine-learning-augmented random field simulations
May 16, 2022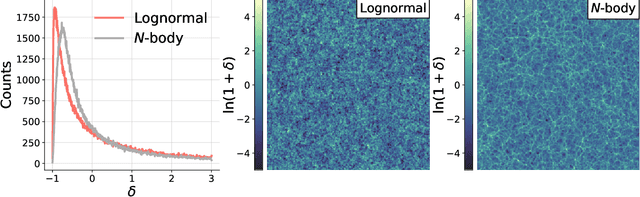
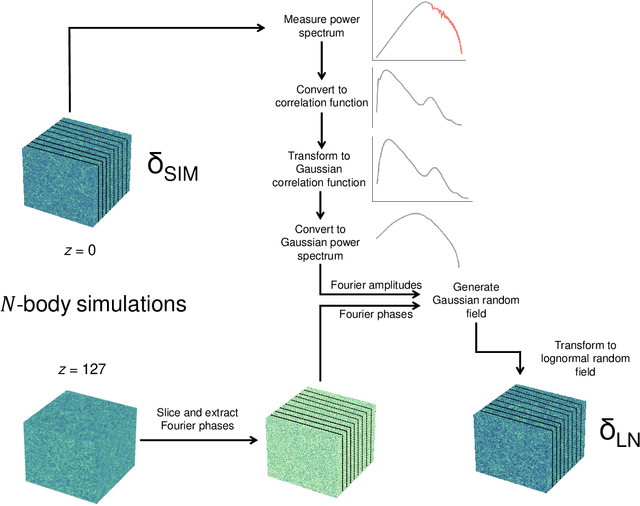
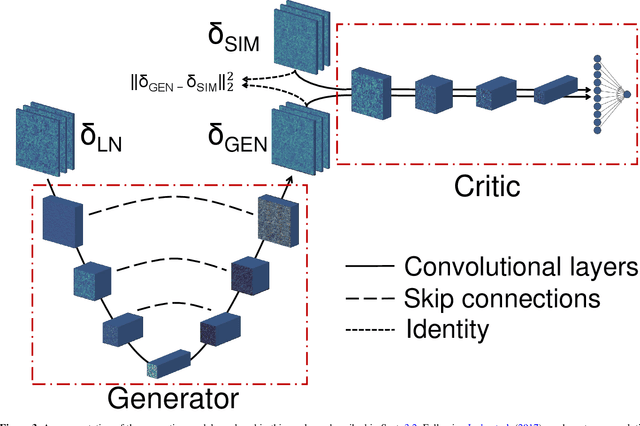
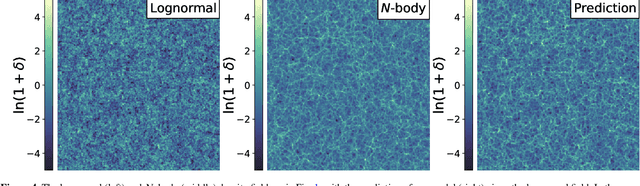
Producing thousands of simulations of the dark matter distribution in the Universe with increasing precision is a challenging but critical task to facilitate the exploitation of current and forthcoming cosmological surveys. Many inexpensive substitutes to full $N$-body simulations have been proposed, even though they often fail to reproduce the statistics of the smaller, non-linear scales. Among these alternatives, a common approximation is represented by the lognormal distribution, which comes with its own limitations as well, while being extremely fast to compute even for high-resolution density fields. In this work, we train a machine learning model to transform projected lognormal dark matter density fields to more realistic dark matter maps, as obtained from full $N$-body simulations. We detail the procedure that we follow to generate highly correlated pairs of lognormal and simulated maps, which we use as our training data, exploiting the information of the Fourier phases. We demonstrate the performance of our model comparing various statistical tests with different field resolutions, redshifts and cosmological parameters, proving its robustness and explaining its current limitations. The augmented lognormal random fields reproduce the power spectrum up to wavenumbers of $1 \ h \ \rm{Mpc}^{-1}$, the bispectrum and the peak counts within 10%, and always within the error bars, of the fiducial target simulations. Finally, we describe how we plan to integrate our proposed model with existing tools to yield more accurate spherical random fields for weak lensing analysis, going beyond the lognormal approximation.
Discovering the building blocks of dark matter halo density profiles with neural networks
Mar 16, 2022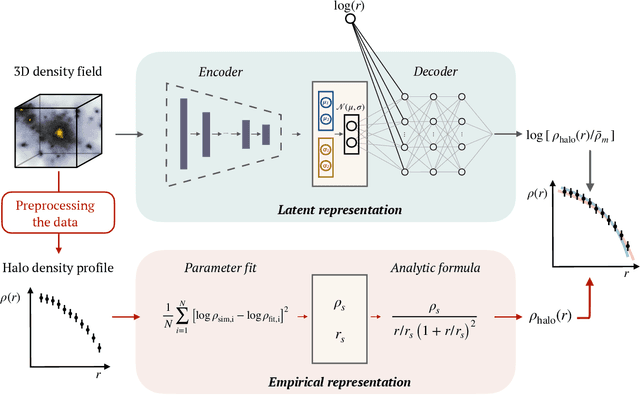
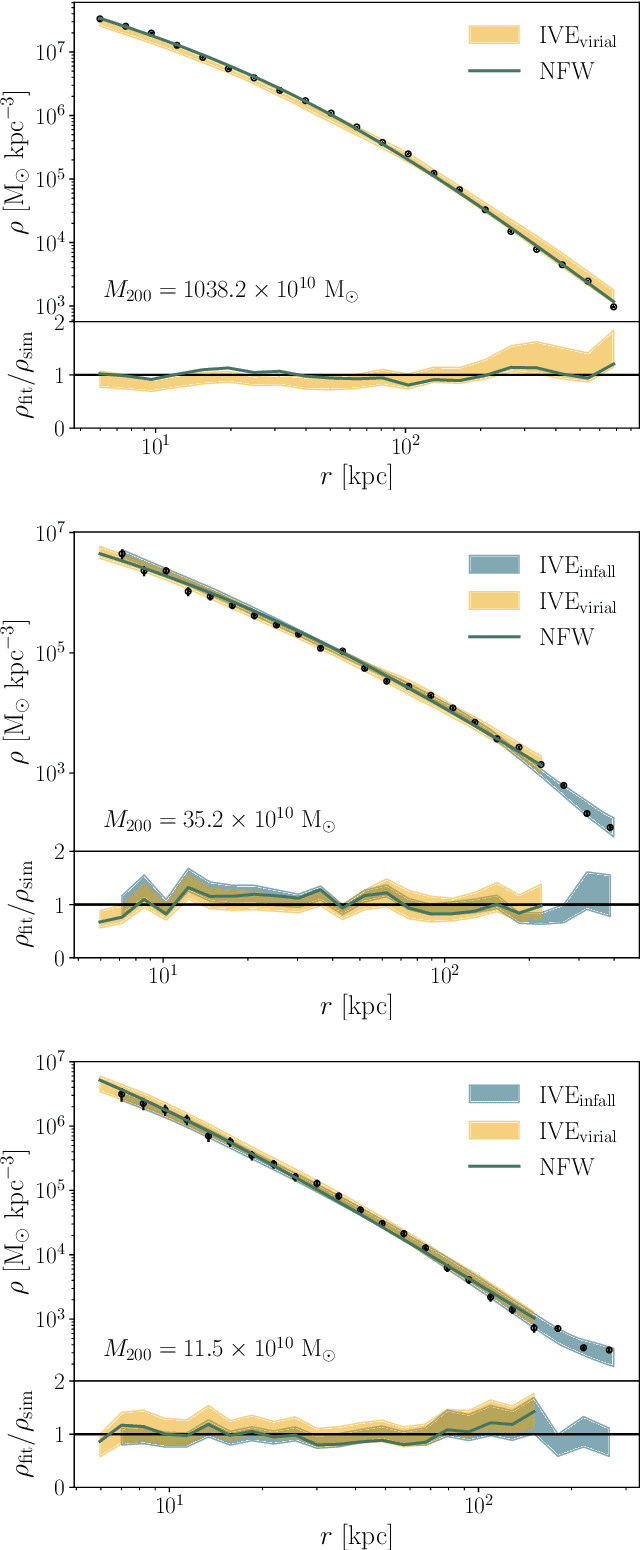
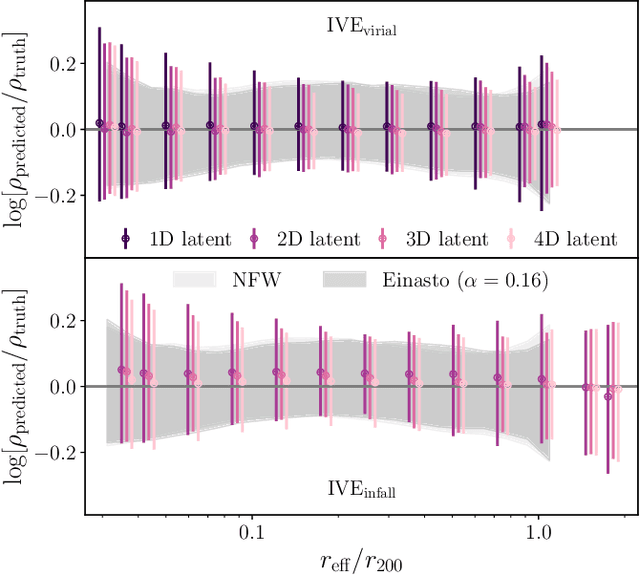
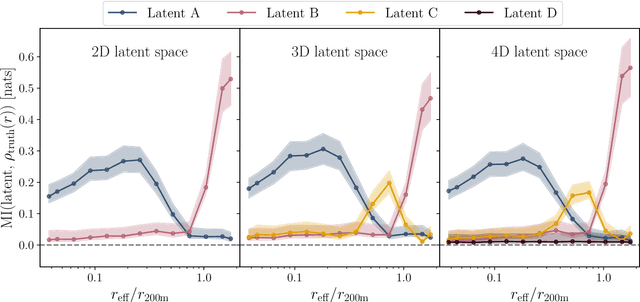
The density profiles of dark matter halos are typically modeled using empirical formulae fitted to the density profiles of relaxed halo populations. We present a neural network model that is trained to learn the mapping from the raw density field containing each halo to the dark matter density profile. We show that the model recovers the widely-used Navarro-Frenk-White (NFW) profile out to the virial radius, and can additionally describe the variability in the outer profile of the halos. The neural network architecture consists of a supervised encoder-decoder framework, which first compresses the density inputs into a low-dimensional latent representation, and then outputs $\rho(r)$ for any desired value of radius $r$. The latent representation contains all the information used by the model to predict the density profiles. This allows us to interpret the latent representation by quantifying the mutual information between the representation and the halos' ground-truth density profiles. A two-dimensional representation is sufficient to accurately model the density profiles up to the virial radius; however, a three-dimensional representation is required to describe the outer profiles beyond the virial radius. The additional dimension in the representation contains information about the infalling material in the outer profiles of dark matter halos, thus discovering the splashback boundary of halos without prior knowledge of the halos' dynamical history.
Towards fast machine-learning-assisted Bayesian posterior inference of realistic microseismic events
Jan 12, 2021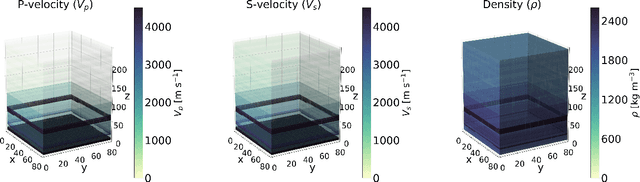
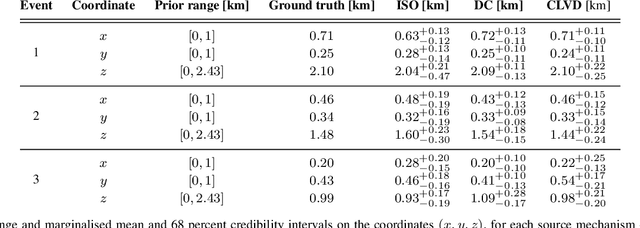
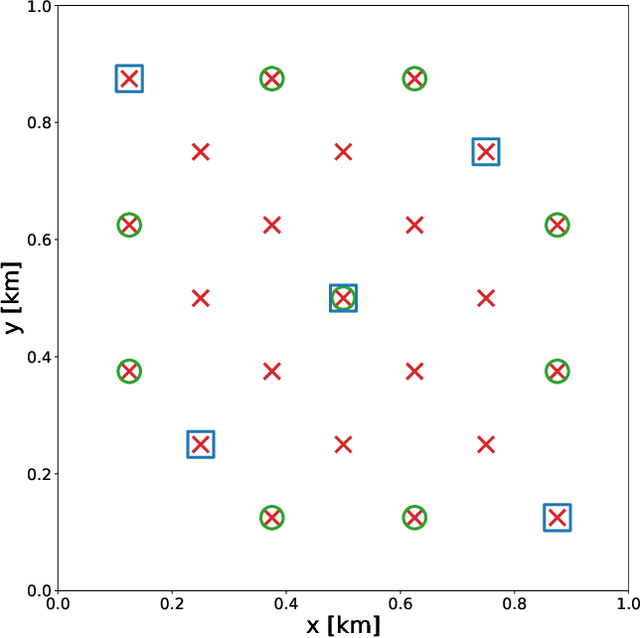

Bayesian inference applied to microseismic activity monitoring allows for principled estimation of the coordinates of microseismic events from recorded seismograms, and their associated uncertainties. However, forward modelling of these microseismic events, necessary to perform Bayesian source inversion, can be prohibitively expensive in terms of computational resources. A viable solution is to train a surrogate model based on machine learning techniques, to emulate the forward model and thus accelerate Bayesian inference. In this paper, we improve on previous work, which considered only sources with isotropic moment tensor. We train a machine learning algorithm on the power spectrum of the recorded pressure wave and show that the trained emulator allows for the complete and fast retrieval of the event coordinates for $\textit{any}$ source mechanism. Moreover, we show that our approach is computationally inexpensive, as it can be run in less than 1 hour on a commercial laptop, while yielding accurate results using less than $10^4$ training seismograms. We additionally demonstrate how the trained emulators can be used to identify the source mechanism through the estimation of the Bayesian evidence. This work lays the foundations for the efficient localisation and characterisation of any recorded seismogram, thus helping to quantify human impact on seismic activity and mitigate seismic hazard.